


 23
23 6
6 23
23


从现在知道的信息来看,应该还是ARM架构,除了ARM也没什么适合移动端的新架构。

 登录|注册
登录|注册






AMD 的 Fiji 是全球首个采用 HBM(高带宽)显存的 GPU,在 2015 年发布时HBM的确很震撼——在一枚 GPU 芯片上,GPU 的管芯(Die)和 HBM 内存的管芯都焊在同一基片上,显卡 的 PCB 上没有内存芯片,只有供电电路和输出接口器件,可以轻松放进 ITX 的机箱里,这可是当时的高端显卡。彻底颠覆了传统旗舰卡动辄超长超大的定论。

上一代AMD Radeon R9 GPU与HBM显存
不过 Fiji 搭配的 HBM 显存是第一代 HBM,存在难以克服的容量问题。所以即便是旗舰定位的Radeon Fury X也不过是4GiB显存容量。而在同一时期,AMD 自己的 R9 390 系列都已做到了 8GiB。在游戏中高分辨率、高特效设置的时候,游戏所需显存会轻易超过 4GiB ,所以搭配HBM显存的Fiji其实是有些尴尬的,它定位高端,但是在一定程度上来说,Fiji 就是中端和高端之间的先锋产品。

AMD Vega GPU与HBM2显存
而这次的 Vega GPU 则采用了 HBM2,容量上可以做到 8GiB、16GiB 等多种规格,不仅涵盖了游戏领域,甚至连对存储容量有较高要求的高性能计算也不在话下,不会再在容量上受人诟病。
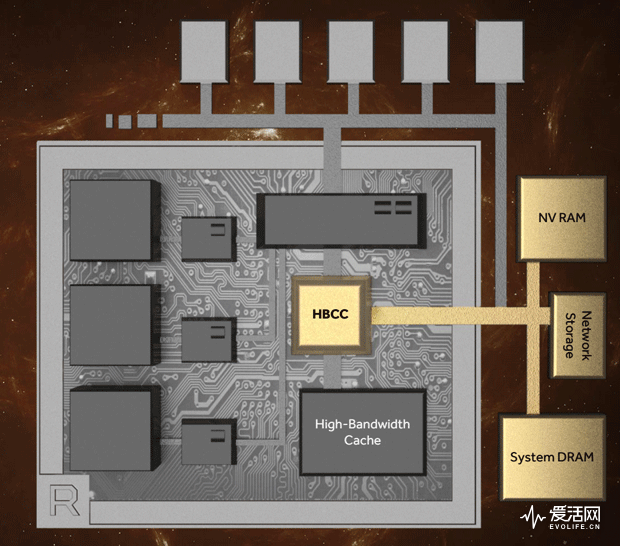
和上代产品相比,Vega GPU还几乎完全重新设计了显存控制器。AMD 将 Vega GPU 上的 HBM2 称作 HBC(高带宽缓存),将Vega GPU GPU的显存控制逻辑称作 HBCC(高带宽高速缓存控制器),而不是显存控制器这样的传统称谓。这样的命名在一定程度上是因为 Vega GPU 允许在显卡 PCB 上放置 SSD、网络存储等多种形式的基片外存储部件,而且这些存储部件的访问对用户(开发人员)来说是可以像显存一样直接存取的,HBM2 扮演的就是作为 GPU 和外部存储单元的大容量高速缓存。
HBM2 的带宽是 HBM1 的两倍,达到 256GiB/s,根据配置的不同,Vega GPU 可以实现 256GiB/s 或者 512GiB/s 的超高带宽。

Vega GPU 不仅有更快更大的 HBM2,它的 HBCC 还提供了高达 512 TiB 的寻址能力,这样的寻址能力当然不会只用于 HBM 上,在去年 Siggraph 上 AMD 公布的 RADEON PRO SSG 其实就是基于 Vega GPU 的专业显卡,该卡的最大特点就是集成了 1TiB 的 NAND 闪存,可以藉此将海量的数据全部存放到显卡上,不再受限于系统总线和存储一致性(存储一致性就是指各层次存储器中存放的数据确保为最新修改的)的性能约束,AMD 这次就用一块 Vega GPU 显卡进行了数据规模达数 TiB 的豪华卧室场景的成品级真实渲染。
要发表评论,您必须先登录。



sss
AMD GCN放弃了矢量之后,基本上越来越像CUDA。那么问题来了,要和NV性能一致,AMD GPU的规模也将一致。唯一优势就是HBM了,问题是GP100也有HBM。
说的好像你的1080是HBM一样
说的好像1080有HBM一样,呵呵
说得好像有了HBM就能干掉1080一样,呵呵
Vulkan和DX12下Fury X难道干不过1080?呵呵
Fury X在Vulkcan和DX12下难道打不死1080?呵呵
AMD的GCN放弃矢量之后越来越像CUDA了,这样搞最终结果就是,如果性能和NV一样,那GPU die规模也一样。
那就是证明NV不行咯?一样规模NV连HBM都没
CHO 陈寅初 好久不见啊,当年再GZEASY经常看你的文章啊
我现在都怀疑石村是不是来自爱活了
石村是谁?
沙壁一只
HSR隐面消除在所有GPU内都有,AMD这个单独拿出来形成管线有意思。
但是最终输出的画面其实只有 0.02 亿个多边形需要着色处理,明确哪些多边形需要被渲染将能够显著降低渲染负荷。 这些都是NV玩剩地。
桌面gpu一般是立即渲染模式的,imr,vega的dsbr那个图是和power vr的tbdr分块延时渲染一样的?
gpu已经不全是立即渲染了吧?
无论这个NCU和普通CU有什么线性流程上面的改进。最多改进的内部线程排列合理程度。改进渲染,缩减冗余多余计算。这样的做法或许可能让更大的核心面积容纳更少的SP更性能不会有太大提高。这个说白了就是中端200-300mmGPU处理器到了500-600mm的其中本身改进。
我反对这样的看法。vega的HMC实际上有机会解决统一寻址的问题。radeon pro ssg挂载ssd,连同vram统一寻址就很有意思,如果换成hbm2,后面挂载gddr5x呢?5x后面再挂载ssd呢?
统一寻址有用,但是延迟怎么解决?从cpu到pcie到gpu到hmc到hbm最后到ssd,你逗我么?
这样也比不能统一强,你能找个1tb的RAM系统我看看么?
你有什么数据有1TB?纹理?
预感引擎底层程序员对Vega的优化又得捣鼓一阵了