


 23
23 6
6 23
23


从现在知道的信息来看,应该还是ARM架构,除了ARM也没什么适合移动端的新架构。

 登录|注册
登录|注册






为了实现在某些负载中的计算需求,AMD 在 Vega GPU 中首次引入 packed(紧缩)数学操作支持。例如深度学习,并不需要 GPU 所提供的32 位浮点或者说单精度运算。
在之前的 Fiji 和 Polaris 中,AMD 的单精度(FP32,32 位浮点)性能和半精度(FP16,16 位浮点)是相同速率的,16 位处理的时候,可以有两倍于 32 位的寄存器,不过 NVIDIA 那边的 GP100(Tesla 100 采用的 GPU)还实现了两倍 32 位性能比率的 16 位计算性能。
AMD 在 Vega GPU 上引入了名为 NCU(下一代计算单元)的微架构,这里 NCU 是对应 GCN 中的 CU 而言的,全新的 NCU 支持紧缩(packed)数学处理,每个 NCU 拥有 64 个 ALU,在采用紧缩数学操作指令的时候,可以支持每个周期 512 个 8 位计算,或者 256 个 16 位计算,又或者是 128 个 32 位计算。
AMD 强调 Vega GPU 在提升单线程性能方面上下了不少功夫,包括更高的频率以及更高的 IPC,前者目前还绝对保密,而后者或者说 IPC 方面,AMD 表示 Vega GPU 具备更大的指令缓存,确保指令流可以运行得更持续,尤其是三操作的指令。
AMD 还在 Vega GPU 上对像素着色处理流程进行了大幅度的改进,引入了 AMD 称之为渲染流分仓光栅器(draw-streaming binning rasterizer,简称 DSBR)的下一代像素引擎。

这个 DSBR 实际上类似于 PowerVR 的块元式渲染技术,能让 GPU 更高效地处理像素着色,尤其是具有高度复杂性(意味着大量无效渲染)深度缓存的像素。DSBR 对重叠的图元只拾取、渲染一次,从而显著节省耗电并提升性能,尤其适合于延后式着色操作。
DSBR 会按照 AMD 称之为高速缓存感知化的方式来调度,它先在一个高速缓冲中对一个场景中给定的“对象包”进行尽可能多的处理,然后 GPU 才会清空掉这个高速缓存并拾取其余的数据。DSBR 可以让 GPU 在无需考虑重叠的前后关系的情况下,在复杂的重叠几何体里抓出哪些像素无需渲染,节省掉在最终场景中非可视的像素渲染处理,从而提升性能。
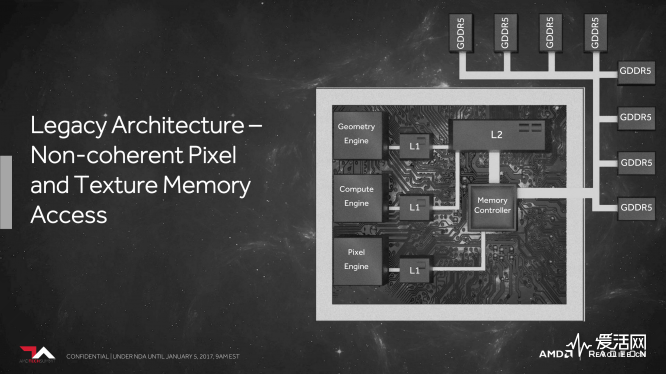
为了让 DSBR 更有效运作,AMD 还对 Vega GPU 的二级高速缓存进行了重大的改进——在以往的 AMD GPU 中,纹理和像素的内存存取是非一致性操作,如果是执行渲染至纹理操作的话,需要先写到内存后,再读到纹理缓存里,增加了大量数据搬动的次数,而且这样的非一致性增加了大量的同步处理和驱动层级的编程挑战。
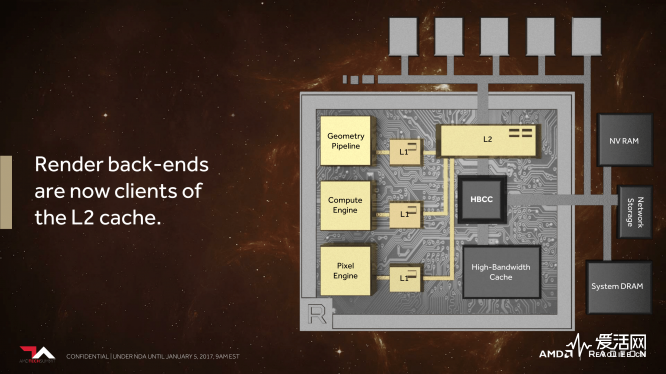
现在,Vega GPU 的后端单元可以直接访问片上的二级高速缓存,这样的变化可以让更多的数据访问动作在片上的二级高速缓存上实现,减少了清空缓存然后在需要的时候又从显存中读回的处理,同样有助于延后式渲染技术的性能提升。
按照 AMD 的说法,DSBR 只是 Vega GPU 的光栅化处理途径之一,是高度动态以及基于状态变换的,GPU 未必一直采用 DSBR 来处理所有的光栅操作,之所以这样讲,可能是因为 AMD 觉得片上的 DSBR 缓存未必总能放进所需的数据。
AMD 目前对 Vega GPU 所公开的资料其实相当之少。毫无疑问,我们依然有大量不明确的细节,例如 L2 Cache 的大小、ROP 的数量、具体的频率以及功耗等指标。根据上月AMD正式发布的Radeon Instinct MI25 能实现 25TFLOPS 的 FP16 性能来推断,Vega GPU 的顶配版至少有 4096 个流处理器,频率可能是 1.5GHz 左右。
AMD 在一个演示房间中用一片早期版的 8GB 显存(内存类型不明) Vega GPU 显卡进行了 Doom 2016 Argemt D’Nur 关卡的演示,在 4K 分辨率 Ultra 画面设置下实现了 60 到 70 fps 的性能,在大型爆炸的时候,帧时间为 24.8ms(相当于 40 fps),这个性能被认为是 GTX 1070 至 GTX 1080 之间。
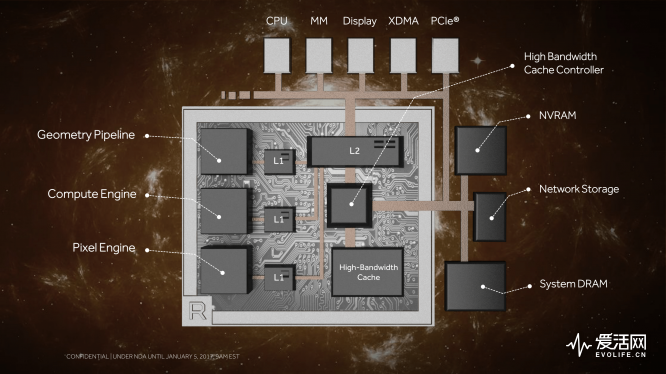
为了保持 ISA 命名的一贯性,AMD 可能还是会把 Vega GPU 归为 GCN 架构,就好像 NVIDIA 现在依然把 G80 以来的 GPU 都称作是 CUDA 架构,所不同的是,Vega GPU 和之前的 GCN 已经有了很大的区别,尤其是 NCU 部分,很可能已经和以前的 GCN 1.X 有明显改进(相信到正式发布的时候会公开),基于这些改进的 Vega GPU 实体卡如果顺利的话将会在今年上半年就能让消费者购买到。
最后来个应该比较靠谱的预言:Vega GPU 未必能让 AMD 重新称霸,但是一定可以增强市场的竞争,让玩家有更多选择
要发表评论,您必须先登录。



sss
AMD GCN放弃了矢量之后,基本上越来越像CUDA。那么问题来了,要和NV性能一致,AMD GPU的规模也将一致。唯一优势就是HBM了,问题是GP100也有HBM。
说的好像你的1080是HBM一样
说的好像1080有HBM一样,呵呵
说得好像有了HBM就能干掉1080一样,呵呵
Vulkan和DX12下Fury X难道干不过1080?呵呵
Fury X在Vulkcan和DX12下难道打不死1080?呵呵
AMD的GCN放弃矢量之后越来越像CUDA了,这样搞最终结果就是,如果性能和NV一样,那GPU die规模也一样。
那就是证明NV不行咯?一样规模NV连HBM都没
CHO 陈寅初 好久不见啊,当年再GZEASY经常看你的文章啊
我现在都怀疑石村是不是来自爱活了
石村是谁?
沙壁一只
HSR隐面消除在所有GPU内都有,AMD这个单独拿出来形成管线有意思。
但是最终输出的画面其实只有 0.02 亿个多边形需要着色处理,明确哪些多边形需要被渲染将能够显著降低渲染负荷。 这些都是NV玩剩地。
桌面gpu一般是立即渲染模式的,imr,vega的dsbr那个图是和power vr的tbdr分块延时渲染一样的?
gpu已经不全是立即渲染了吧?
无论这个NCU和普通CU有什么线性流程上面的改进。最多改进的内部线程排列合理程度。改进渲染,缩减冗余多余计算。这样的做法或许可能让更大的核心面积容纳更少的SP更性能不会有太大提高。这个说白了就是中端200-300mmGPU处理器到了500-600mm的其中本身改进。
我反对这样的看法。vega的HMC实际上有机会解决统一寻址的问题。radeon pro ssg挂载ssd,连同vram统一寻址就很有意思,如果换成hbm2,后面挂载gddr5x呢?5x后面再挂载ssd呢?
统一寻址有用,但是延迟怎么解决?从cpu到pcie到gpu到hmc到hbm最后到ssd,你逗我么?
这样也比不能统一强,你能找个1tb的RAM系统我看看么?
你有什么数据有1TB?纹理?
预感引擎底层程序员对Vega的优化又得捣鼓一阵了