


 0
0 3
3 0
0


从现在知道的信息来看,应该还是ARM架构,除了ARM也没什么适合移动端的新架构。

 登录|注册
登录|注册






众所周知,世界上的第一台通用电脑 ENIAC 是为了计算火炮火力表而制造出来的,可以说电脑从问世伊始,最大的贡献就是解决各种人力难以企及的复杂计算问题。时至今日,虽然普通电脑早就比 ENIAC 快千万倍,但是算力饥渴问题反而日益突出,其中大家现在接触最多的就是三维渲染、多媒体处理、人工智能等应用。

相对于游戏而言,强调生产力的创作者们在显卡上的要求更高,不仅要求有足够快的性能,而且在兼容性和可靠性方面都是要求工具必须有足够的的保证,因此像NVIDIA推出了专业卡产品线,例如 Quadro 等,这些专业卡一般配有很大的显存并且开放了一些 OpenGL 加速支持,主要面向工作站市场。

不过随着近年来 DirectX 也已经在工作站应用中得到了广泛的应用,加上高端游戏卡本身的价格水涨船高,对专业卡的影响已经降低了不少,甚至是有益的产品线补充。为此,NVIDIA 也发布了 Studio 驱动程序,让非专业卡的游戏卡产品线可以获得一些原本工作站卡才具备的特性,例如 30 位 OpenGL 显示支持等,摇身一变就成了准专业卡,成为生产力工具。
对于创作者而言,为了追求专业的设计软件运行性能,要么选择价格非常昂贵的专业显卡,要么使用同样昂贵的高性能CPU搭配大容量内存。专业级的显卡虽然能提升工作效率,但其价格并不亲民,这让很多创作者望而却步。而NVIDIA Studio驱动以及SDK的推出让搭载图灵核心的RTX游戏显卡在专业性能上也有了非常抢眼的表现,这在无形中为设计师们节省了大量的成本,而这也正是NVIDIA Studio驱动的优势所在。对于大多数创作者而言,如果仅仅买一块普通的GeForce RTX游戏显卡配合NVIDIA Studio驱动就能大幅提升工作效率,这无疑是非常吸引人的事。

而和GeForce Game Ready驱动不同的是,NVIDIA Studio驱动为艺术家、创作者和3D开发人员在使用创造性应用程序时提供最佳性能和可靠性。为了实现最高级别的可靠性,NVIDIA Studio驱动程序将对多个app creator工作流和从Adobe到Autodesk等多个顶级创意应用程序的多个版本进行广泛的测试,确保提供给用户的驱动程序是最可靠、效率最高的,因此对于非刚需专业显卡的用户来说,使用一块NVIDIA GeForce RTX系列显卡,就能胜任日常工作中的全部需求。
尤其在NVIDIA GeForce RTX30系列显卡发布之后,搭载NVIDIA Ampere架构的GeForce系列显卡拥有更多显存容量和更强大的AI性能,在面对专业生产力软件时,也拥有足以媲美专业卡的能力。

NVIDIA Ampere微架构集成了第二代光线追踪内核(RT Core),每个 SM 内都拥有一个 RT Core,作用是对光线追踪最消耗算力和带宽的 BVH、三角形遍历和求交进行加速。
相比图灵的第一代 RT Core,NVIDIA Ampere的 RT Core 主要改进之处是增加了一个三角形求交单元,支持三角形求交内插支持,能对动态模糊特效下的光线追踪求交处理加速。
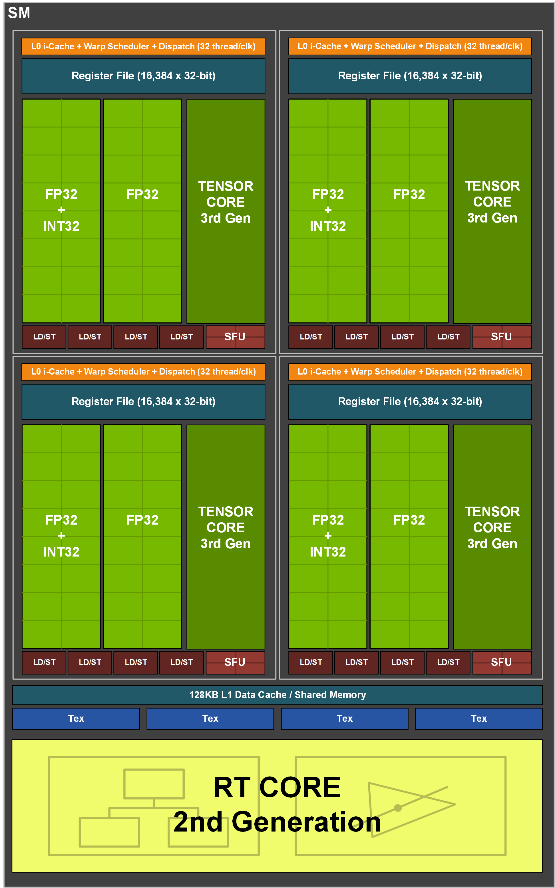
在人工智能或者说深度学习加速方面,NVIDIA Ampere架构的每个 SM 里有 4 个 Tensor Core(每个子核有一个 Tensor Core),但是每个 Tensor Core 的处理能力都倍增了,因此NVIDIA Ampere的每个 SM 也能跑 512 个 FP16 Tensor 操作。
在数据格式支持能力方面,NVIDIA Ampere引入了 BF16、TF32 两种新的数据格式,前者是 Google 引入的一种 16 位数据格式,而后者则是 NVIDIA 自家首次引入的 19 位数据格式。
BF16:也被称作 Brain Float 16 或者 BFloat 16,由 Google Brain 推出,最初只有谷歌的 TPU 深度学习处理器采用。和 FP16 一样,BF16 也是 16 位长的二进制数,但是它的数据格式是 1 位符号位、8 位指数,7 位尾数。这样的设计是为了追求 FP32 的动态范围,但是需要牺牲尾数数据范围。
TF32:这是 NVIDIA 在 A100 厨房发布会首次公布的数据格式,目前已发布的NVIDIA Ampere全系 GPU 配备的 Tensor Core 都支持这个数据格式。TF32 的数据格式是 19 位二进制,有 1 个符号位,8 位指数以及 10 位尾数。
TF32 具备 FP32 和 BF16 一样的 8 位动态范围,但是有效数字精度比 BF16 多了 3 位,如果以十进制来说相当于有效数字精度从两位提高到了接近四位。
在具体实现上,在启用 TF32 的时候,NVIDIA Tensor Core 输入输出的数据格式依然是 FP32,但是 Tensor Core 内部会以 TF32 的格式进行计算,因此,TF32 无需程序员修改代码,只需要编译器提供支持即可,和 FP32 相比,TF32 只是精度降低,但是动态范围保持一样。
由于数据格式的原因,FP16 和 BF16 都需要更多的代码量,但是因为可以节省内存占用以及更快的速度,所以 BF16 和 FP16 依然值得采纳。
除了支持更广泛的数据格式外,A100 引入的硬件稀疏化技术在 GA10X 上也得以实现,透过该技术,GA10X 在同样每周期 512 个 FP16 tensor 操作的能力上可以再增加一倍达到等效每周期 1024 个 FP16 操作。
和GeForce RTX 2080 Super 相比,GeForce RTX 3080 的张量性能可以最高达到 2.7 倍。
和 A100 相比,作为面向消费级市场的 GA10X 去掉了 A100 的 FP64 以及 Binary(二元)张量计算支持。
A10X 的 Tensor Core 数量是 TU10X 的二分之一,但是由于每个 Tensor Core 规模是前代的两倍,因此跑同样格式的数据性能都是一样的,例如 FP16 的时候都是每个 SM 每周期跑 512 个 FP16 tensor Ops。
比较特别的是,GA10X 具备 A100 一样的硬件细粒度结构化稀疏加速能力,能够以每 4 个权重为一组的方式,将已经训练好的权重分组中权重值为 0 的两个权重修剪掉,透过这个稀疏化处理,实现了推理准确无损情况下等效 100% 的深度学习性能提升,或者说等效每周期每个 SM 完成 1024 个 FP16 Tensor 操作。
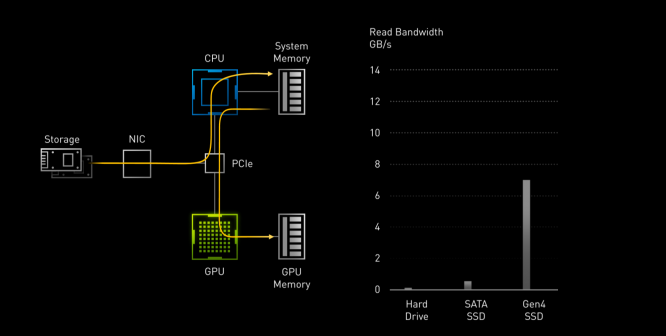
除了 RT Core 和 Tensor Core 的改进外,技嘉 GeForce RTX 3080 VISION 雪鹰采用的 GA102 GPU 还支持 RTX IO,透过 RTX IO,GPU 可以直接从 NVME 硬盘读取数据而无需 CPU 和系统主内存参与,这对很多生产力应用都有莫大的好处,例如 8K RAW 视频采编等,要知道,对于 NVME 硬盘来说如果传输的压缩数据需要 CPU 先解码的话,会吃掉数十个内核的算力,但是如果直接让 GPU 读取解码的话,只需要半个 CPU 的开销。RTX IO 在 Windows 上需要 2021 年微软 DirectIO 支持。

而技嘉的 GeForce RTX 3080 VISION 雪鹰就是技嘉科技针对工作站市场的一款准专业卡产品。技嘉 GeForce RTX 3080 VISION 雪鹰采用的是 NVIDIA GeForce RTX 3080 GPU,基于NVIDIA Ampere 架构,拥有第二代光线追踪内核和第三代张量内核,拥有 10 GiB GDDR6X 显存,配备三槽式“风之力”静音散热器,强调性能、稳定性以及噪音的最佳平衡。


作为定位工作与游戏兼顾的产品,技嘉 GeForce RTX 3080 VISION 雪鹰采用的风之力三风扇搭配了两个 90mm 和一个 80mm 特殊刀锋扇叶风扇,分别以正逆转方式运作,散热器拥有 7 根高性能纯铜导热管,GPU 接触面为硕大铜片,风扇能根据负载实现动态启停,挡板经过镂空处理,便于让热量直接排除机箱外。

除此以外,技嘉 GeForce RTX 3080 VISION 雪鹰配备了金属强化背板,能为 PCB 提供全面加固减少变形,尾部还有镂空设计,能让散热器风扇气流通过增强散热。

由于现在的 GPU 和 PCB 相当复杂,我们这次没有做拆卡,上图是技嘉官方提供的散热电路图。技嘉 GeForce RTX 3080 VISION 雪鹰合共采用了 17 相供电,用于 GPU 的有 13 相,显存为 4 相,每组 MOSFET 都提供了过热保护和负载平衡设计,加上长寿命固态电容、合金电感、低电阻晶体管等耐用材料,可以确保显卡强劲性能以及持久使用。

核心基频为 1.8 GHz(公版规格是 1.71G Hz),内存频率为 1.188 GHz(等效 19 Gbps),性能较公版略强。

显卡顶部支持 RGB FUSION 2.0 的 RGB 灯效支持,支持 1677 万色的变化。

镀金显示输出接口,双 HDMI + 三 Displayport,满足绝大多数应用场景。
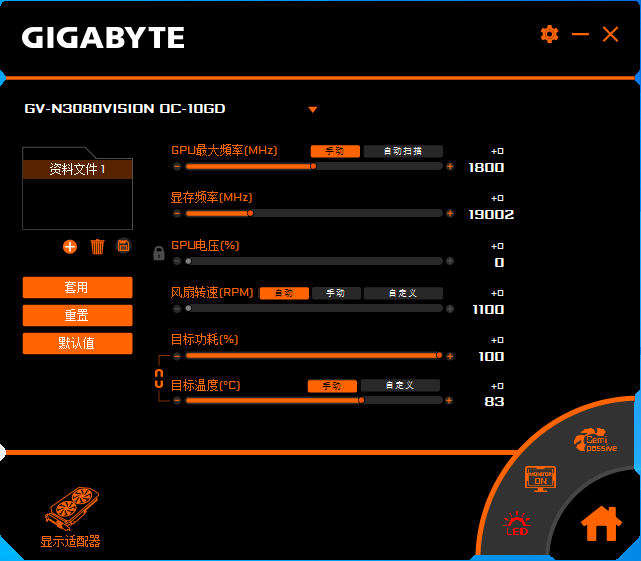
AORUS ENGINE 是技嘉官方提供的超频、监控软件,大家可以根据实际应用和显卡的体质进行频率、风扇转速等调整。
技嘉 GeForce RTX 3080 VISION 雪鹰与NVIDIA Ampere
技嘉 GeForce RTX 3080 VISION 雪鹰采用的 NVIDIA GeForce RTX 3080 GPU 是 NVIDIA 的第二代 RTX 系列产品,GPU 代号为 GA102,属于NVIDIA Ampere微架构,拥有 68 个流式多处理器(SM),合计 8704 和 CUDA Core,能提供每秒 31.3 GFLOPS 以上的单精度性能。
技嘉 GeForce RTX 3080 VISION 雪鹰支持 8K AV1 和 HEVC 硬件解码,配合最新版本的 Premiere Pro,可以在时间线里流畅拖拉进度素材完成剪辑。
显示器方面,技嘉 GeForce RTX 3080 VISION 雪鹰最高支持 8K 60Hz DP 1.4、HDMI 2.1 输出,可以完美实现新一代超高清播放的支持。
从生产力应用的角度来说,我觉得选择像技嘉 GeForce RTX 3080 VISION 雪鹰这类 N 系产品的最大好处是业界最强的应用生态,例如:
你是做实时建筑场景开发的话,UE、Unity 、Dunia(Farcry 引擎)等引擎已经把光线追踪集成,NVIDIA 这边提供了 RTX 支持,包括 DDGI 或者说 RTX GI 全局照明这类高级特效就是点一下鼠标就能马上用上,不再需要以前那样用彻夜通用计算来跑烘焙;
如果是做电影特效的话,三维方面 NVIDIA 光线追踪加速获得了业界最广泛支持,包括 Keyshot 这个以前只做 CPU 渲染的渲染器也都在图灵发布后就立马拥抱 NVIDIA,NVIDIA 的 OptiX 在这里扮演了重要角色。OptiX 是 NVIDIA 的光线追踪开发框架,是 NVIDIA 过去数十年做通用计算和光线追踪做出来的终极杀招,图灵和NVIDIA Ampere出来后,OptiX 都第一时间跟进,让各个渲染引擎快速实现对最新技术的支持。
如果你是做视频编辑的话,使用 RED 8K RAW 编辑,如果纯用 CPU 来跑的话,画面在时间线上的拖放回看和幻灯片没啥差别,NVIDIA 使用 CUDA 实现了 RED 官方采编软件的 8K RAW 加速,能实现实时拖放回看,效率大为提升。
我们使用了面向生产力的软件来做这次测试,首先登场的是 SPECviewperf 2020。
SPECviewperf 2020 是今年 10 月 SPEC.org 发布的面向专业图形应用的测试包,和 3DMark 不一样的是,它采集了真实软件的渲染轨迹,使用真实的复杂场景和模型,2020 版 Viewperf 光是安装包就有 16 GB,需要 60 GB 硬盘空间才能完成安装,连测试结果文件的大小都有 70 MB。
测试平台:
显卡:技嘉 GeForce RTX 3080 VISION 雪鹰
驱动版本:NVIDIA Studio Driver 460.89
内存:阿斯加特 DDR4-3600 8 GB * 4
硬盘:Micron 128 GB MLC SSD SATA3
显示器分辨率:1920×1080 60Hz
Windows 10 20H2 专业工作站版
我们这里使用了 spec.org 官网的测试数据作对比,需要注意的是,大家的 CPU 平台不一样,不过我们从价格来看的话,我们的平台价格要第一大截,生产力先决的产品选择价格也是一个重要的因素。
某东价格参考:
Quadro RTX 4000:7789 元
技嘉 GeForce RTX 3080 VISION 雪鹰:6899 元






从测试结果来看,技嘉 GeForce RTX 3080 VISION 雪鹰在 3dsmax-07、maya-06、solidworks-05 中有显著优势,其中 3dsmax-07 达到了对比产品的 1.76 倍和 2.34 倍,maya-06 达到 1.57 和 2.4 倍、solidworks-05 达到了 1.7 和 2.73 倍。落后较多的项目只有一个:snx-04,说明这个项目还是需要 OpenGL 专业卡才行。
上面是三维软件实时视口性能测试,接下来让我们看看离线渲染或者说成品渲染的性能。
我这次使用的是 Blender 2.9.1,场景为 DroidChase,这是一个运动场景,有大量的动态模糊效果,只对比开启 技嘉 GeForce RTX 3080 VISION 雪鹰硬件光线追踪(OptiX)、纯 CPU 渲染以及 CUDA GPU 通用计算加速。
先看看启用硬件光线追踪渲染和纯 CPU 渲染的画面对比图:
打开硬件光线追踪(OptiX):
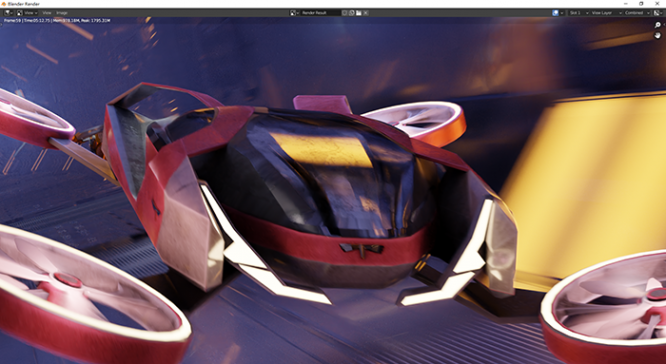
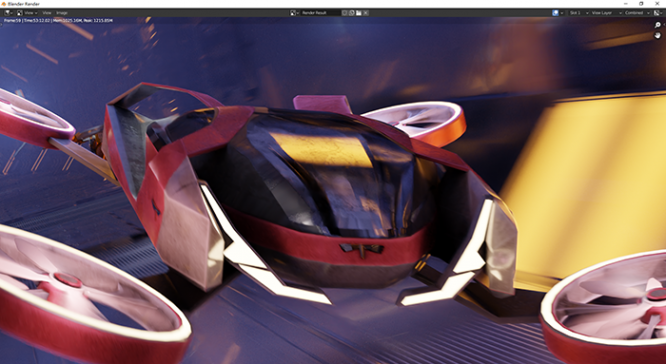
纯 CPU 渲染:
CUDA 通用计算:
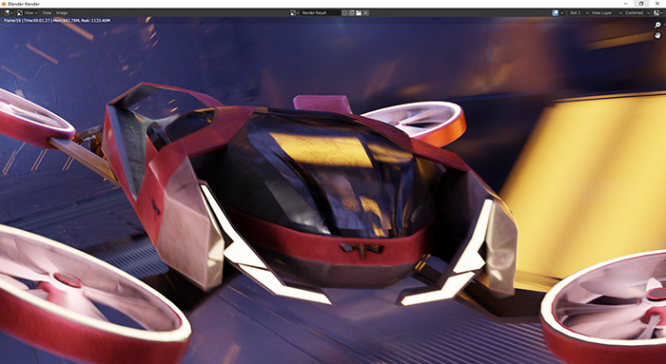
要是没有差别是假的,画面中车身右侧是有一些反射倒影的区别,但是整体来看非常接近,至于性能差别……:

就是这么强,这正是因为 技嘉 GeForce RTX 3080 VISION 雪鹰 RT Core 以及 CUDA 本身的算力加持才得以实现的,在渲染过程中,CPU 基本处于闲置状态,用户可以在此时上上网等干些别的事情而不会干扰到渲染,感觉技嘉 GeForce RTX 3080 VISION 雪鹰此时就是一个多快好省的迷你渲染农场。
接下来我们试了一下深度学习方面 技嘉 GeForce RTX 3080 VISION 雪鹰的性能表现。
如果从纯深度学习的角度来看,GeFroce RTX 3080 具备较强的浮点、张量性能,但是也不是没有缺点,例如内存容量只有 10 GB,有些数据集真的没法一下吃下去,此外三槽设计对多卡并行不是很友好。
我们基于最新版本的 CUDA 11.1 Toolkit 和 Tensorflow 20.10-tf1(用的是 NGC 上的 docker 容器)进行了一些深度学习的测试,技嘉 GeForce RTX 3080 VISION 雪鹰和上一代的 GeForce RTX 2080 Ti 相比,CNN/ResNET 的性能大约提升了 50%,不过受制于显存容量,batch 只能开到 192,多少影响了性能发挥,如果是 3090 的话 batch 数量可以开到 512,可以更充分发挥性能。
由于时间有限,我们这次并未进行稀疏化的对比。
毫无疑问,如果现在想要一片价格适宜、功能齐备、生产力先决的显卡,还是只能从 N 卡阵营里找,几乎全面覆盖甚至想你所想的保姆式应用生态可以让项目最快部署,时间、效率,都是必须优先考虑的。
技嘉 GeForce RTX 3080 VISION 雪鹰就是一块能适应这个选择的产品,它有强大的实时、离线渲染性能,具备一定的炼丹(深度学习)能力,我觉得可以作为工作站领域值得考虑的采购选项。
哦,对了,温度和噪音的结果又如何呢?这里翻出来吧:
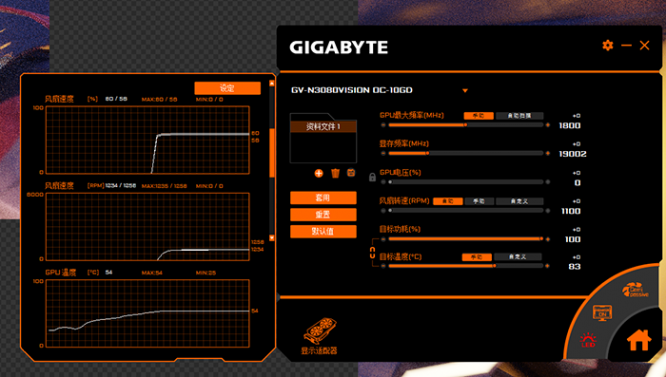
我们在 Blender 以硬件光线追踪加速渲染的时候打开技嘉的 AORUS ENGINE 进行风扇和温度的监控,可以看到,想开在 54 度之前,风扇是完全没启动的,当温度达到 54 度以后,风扇开始启动,此时转速大约是每分钟 1234 转,速度并不高,因此噪声其实也并不高,然后在这样的转速下温度就一直保持着。当然,我这里是靠一身正气御寒的广州,测试时候的室内气温大约是 15 摄氏度。


