


 2
2 1
1 2
2


从现在知道的信息来看,应该还是ARM架构,除了ARM也没什么适合移动端的新架构。

 登录|注册
登录|注册






GTC China 2018在苏州拉开序幕。为期三天的GPU技术大会正式开始前,少不了英伟达创始人、CEO黄仁勋登台点燃气氛。很显然,作为一家技术公司,今年发布的Quadro RTX、GeForce RTX仍然不会是英伟达的终点,正如黄仁勋所期望的,英伟达的GPU已经变得无处不在。

话题一开始自然少不了游戏,在GeForce RTX正式发布之后,网游《逆水寒》、《剑网三》先后加入了GeForce RTX新技术的支持阵营,《逆水寒》更是成为首个支持光线追踪技术的国产网络游戏。

在《逆水寒》的演示DEMO中,游戏被加入了大量光线追踪特效,从盔甲的反光、水面倒影,以及阴暗面的光线折射的实时运算,光线追踪特效的表现效果不是生硬添加光源所能比拟。


与此同时,游戏也利用了图灵架构GPU中的Tensor Core张量内核来支援DLSS深度学习超采样技术。简单而言,在DLSS加持下,游戏可以获得与高倍率MSAA多重采样抗锯齿画面相似,但却能够节省大量运算性能。
这意味着即使原始计算性能提升不明显,凭借着DLSS和光线追踪,游戏画质不仅可以获得巨幅提升,效能更是可以达到3.5倍的跨越。并且RT Core和Tensor Core为图灵架构以后的GPU才被加入,以往的显卡难以超越。

黄仁勋在现场甚至不惜吊打上一代旗舰GeForce GTX 1080 Ti,即便是499美元的GeForce RTX 2070,实际表现和性能都远比GeForce GTX 1080 Ti抢眼得多,直接终结了帕斯卡架构任何逆袭的可能性。

摩尔定律终结众人皆知。但在相同价格或者功率下,计算机行业仍然能以10%的速度增长,很大原因归功于计算芯片对任务的进一步细分。
英伟达开创了一套基于GPU的加速计算,通过专门设计的处理器堆栈加速大规模并行数据的整理。事实上,英伟达在推出CUDA的数年时间中,已经为众多关键应用程序加速了1000倍以上。黄仁勋还自豪的宣布NVIDIA CUDA SDK下载量已经接近1400万,其中去年一年就贡献了600万。加入CUDA阵营的科学计算、实验室、研究人员越来越多。
而美国能源部的超算采购计划也是推动了GPU加速的快速发展,超算Summit就是用了27648块NVIDIA V100,已经有127个超算采用了NVIDIA GPU系统,其中美国、欧洲、日本第一超算全部源自于英伟达,能效比Top25的超级计算机中,有22个都是用了英伟达GPU解决方案,著名的NVLink告诉传输也诞生于其中。

大规模数据下,无限可能性被催生。AI人工智能正式其中之一,让机器通过大量数据自主学习、编写软件,甚至是探索人类不曾想象过的可能性。借助AI,人们可以从海量数据中学习建立预测模型,并将其再付诸实践。不要小看数据的力量,电商、零售、金融服务、电信、医疗保健的数据都已经被技术领先者们采用,从而也诞生了需要更多计算量的想法。
HPC和超大规模计算正在因为AI而不断改进,从多精度Volta Tensor Core GPU开始,运算性能正在不断加速。英伟达给大型仿真设计了V100 HGX-2,单个机箱中有8个V100 GPU连接,运算量达到1 PFLOPS,其中每个GPU能够以300GB/s的速度与其他GPU之间通讯,并以8TB/s的速度访问256GB显存。


为了让云端无所不能,英伟达将所有新技术融入到一块芯片中,不管被用来处理什么内容,数据中心大规模集群都应该胜任。名为NVIDIA T4 CLOUD GPU就此诞生,这是一块能混合FP32、FP16 TC、IN8 TC、INT4 TC计算的芯片,理论性能可以从65TFLOPS到230TOPS。它们将两两为一组,与CPU搭配插入一个占位2U的服务器四分之一盘位,也就是说,在一个2U机架中,能最多融入8个NVIDIA T4。
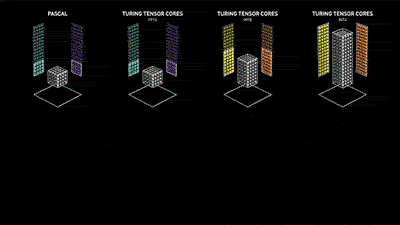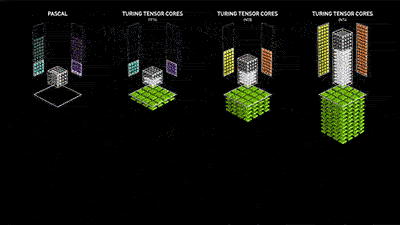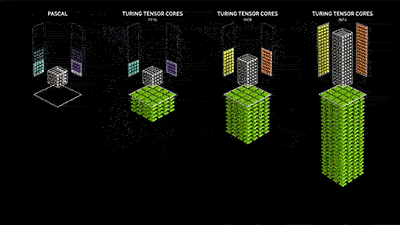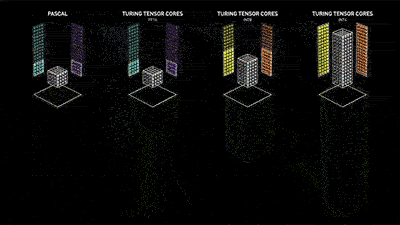
这套由NVIDIA T4加持,名为Tensor RT的推理服务器系统性能表现是恐怖的。黄仁勋在现场不忘抓起CPU一通吊打,在一块英特尔Skylake CPU中,图像学习只能同时处理两位数的图片,但到了NVIDIA T4,同样一套系统表现出的性能可以数千倍的提升。这也意味着本来需要数小时的数据科学计算,可能只需要数分钟就能完成。
同样,也意味着NVIDIA T4的服务器面积效能比更高,占地面积更小。黄仁勋在现场多次表示“买越多,越省钱”,感觉不买真的很亏。


云端计算获得的AI人工智能模型、算法会最终实践到具体的硬件终端上。英伟达Xavier正是其中之一,这是一款专门针对机器人计算业务设计的芯片,能够同时处理高速率、AI、控制算法、浮渣传感器。
Xavier本身就是一块完整的SoC,包括ISP图像传感器处理单元、PVA可编程立体视觉加速器、VPU视频处理器、OFE光流引擎、Tensor Core可编程张量内核、CUDA并行计算加速器、GPU图像加速器、DLA深度学习加速器、CPU中央处理器。配合NVIDIA AGX全家桶,就能实现一整套包括自动驾驶、机器人和智能仪器的互动。

事实上包括京东、阿里巴巴菜鸟物流在内的诸多国内顶级物流公司已经开始尝试机器人配送,甚至最后一公里投递。GPU加速会出现在每一个机器人、服务器、工作站上,并且所有芯片都开放了从低层到系统的权限,开发者可以根据实际情况对芯片进行定制化。
最后,黄仁勋也没有忘记秀一把英伟达的自动驾驶技术。事实上包括沃尔沃、小鹏汽车在内的厂商已经开始采用英伟达的自动驾驶解决方案测试Level 4自动驾驶系统。英伟达也已经开始着手帮助租赁出行服务商研发自动驾驶出租车服务。有意思的是,自动驾驶出租车服务同样也是福特、丰田等车企大佬们当下正在攻坚的测试项目之一。

摩尔定律停滞不代表着人们对运算需求量减缓。相反,人工智能、深度学习、自动驾驶、IoT背后对计算机运算效能要求日益严苛,定制化芯片正好是英伟达擅长的工作之一。在游戏市场近乎没有对手的同时,英伟达早已将GPU延伸到运算的各个领域,并且利用CUDA、Tensor Core等多项技术给运算再踩上一脚油门。
是的,以后你看到的游戏PC、快递机器、自动驾驶汽车,甚至是负责跟你交互的人工智能,可能都少不了英伟达的影子。

要发表评论,您必须先登录。



可惜华人的老黄改了国际
不改也…….你懂的