


 3
3 21
21 3
3


从现在知道的信息来看,应该还是ARM架构,除了ARM也没什么适合移动端的新架构。

 登录|注册
登录|注册






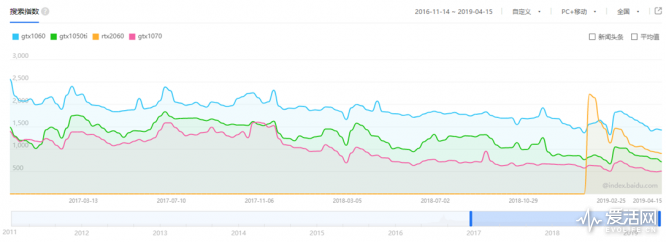
从百度指数上来看GeForce GTX 1050 Ti级别的显卡的用户关注度要低于GeForce GTX 1060,但其出货量依然不能小视,DIY究竟是小众的差异化市场,但GTX 1050 Ti这个级别的显卡在联想/HP/戴尔这样的整机厂商,还有宁美国度/名龙堂这样的SI整机厂商的出货量之中却占有了很大的比例。特别是在17年绝地求生火爆之前,GTX 1050 Ti由于能够很好的满足网游和MOBA类游戏的性能需求,很受消费者欢迎。但在17年下半年吃鸡逐渐火爆,1050TI仅能在低画质较为流畅的运行吃鸡,在这种应用的推动之下,游戏用户的需求被拔高,GTX 1060成为2017-2018年度的最受欢迎的显卡。
但对于50级别的显卡需求还是存在,但GTX 1050 Ti现在看来还是太老了,究竟是2016年的东西,现在都9102年了。因此NVIDIA在近日推出了采用全新Turing架构的GTX 1650,用来迭代更新已经老迈的GTX 1050 Ti。
![5D]OD19N(5M5_F{F`6$AJXT](https://file.evolife.cn/2019/04/5DOD19N5M5_FF6AJXT-666x369.png)
我们首批收到的测试样卡是由华硕提供的Phoenix和Dual版。Phoenix是单风扇的短卡,而Dual顾名思义是双风扇,长度也略长。

我们评测的重点是双风扇的Dual。
![2TJG6]$D%T(Q3C}N1ZZ`QOB](https://file.evolife.cn/2019/04/2TJG6DTQ3CN1ZZQOB-666x429.png)
Dual采用双8cm的大风扇设计,长时间烤机转速大概1600RPM,依然可以保持静音。

风扇下的散热器仅仅是整体铝片,而无热管。由于GTX 1650的TDP仅为75W,刚好在PCI-E标准的供电能力范围以内,因此并无额外的供电接口。

输出端为DP+HDMI+DVI组合,由于考虑到GTX 1650的市场定位和目标用户需求,DVI还是继续保留。
![H]DGMD4T8PZUYP%V8E64NF7](https://file.evolife.cn/2019/04/HDGMD4T8PZUYPV8E64NF7-666x626.png)
双风扇的Dual长度大概21.5cm,单风扇的长度20.5cm,区别不大。基本不会有两风扇塞不进去可以装单风扇的情况。

Phoenix和Dual版都是采用的相同PCB方案,实际PCB的长度仅为18cm。

GTX1650的PCB整体十分简洁,供电集中在输出段方向,四颗镁光的DDR5组成128Bit 4GB的显存。

GTX 1650的核心编号是TU117-300-A1,面积大概是14×14 196mm2。核心周围有华硕特有的点胶固定,这样可以很大程度避免核心脱焊导致的故障。

再来看看TU117核心的结构,GTX 1650/TI的TU116核心有3个GPC,而GTX 1650的TU116只有两个,并且两个还不是完整的。Turing架构一个 SM是64个流处理器,896个流处理器就说有14个SM,一个GPC是8个SM,那么这样说明TU117是有2个GPC,但并不是完整的,还差2个。完整的TU117应该是 16 个SM,就应该是1024流处理器,估计这个就应该是1650TI规格,这个就是后话。
![Q`VOM$LNP_3OX(]`~@SF0)O](https://file.evolife.cn/2019/04/QVOMLNP_3OX@SF0O-666x305.png)
当然性能不仅仅是看流处理器,还有其他方面,如ROP和TMU,ROP光栅化单元的规模决定像素填充率,这在很大程度决定不同分辨率的性能表现,ROP越多高分辨率性能表现越好,GTX 1650还是维持了GTX 1050 Ti的ROP规模,都是32个。这是定位相关,主要是应对1080P的目标分辨率,不过虽然ROP的数量没有发生变化,但Turing的ROP效率还是有提升的。
GTX 1650的目标用户群主要是网游或者是电竞游戏,这些游戏的画面水平相比顶级画面的 AAA,在性能需求上对于Shader的需求较低,但在纹理方面的需求却大幅提升,其实这个变化是有个标志性的阶段, 就是2014年年底发行的刺客信条大革命和使命召唤高级战争,开始高分辨率材质贴图的应用,使得游戏对于TMU和显存容量有了更高的需求。而这两作是游戏主机进入本世代之后的首次迭代更新。GTX 1650的纹理单元从GTX 1050 TI的32增加到了48,更多的纹理单元就能够更好的应对本世代的游戏需求。
显存方面1650虽然还是继续维持4GB DDR5 128Bit的规格,但频率从7GHz提升到了8GHz,这样使得显存的带宽更大。
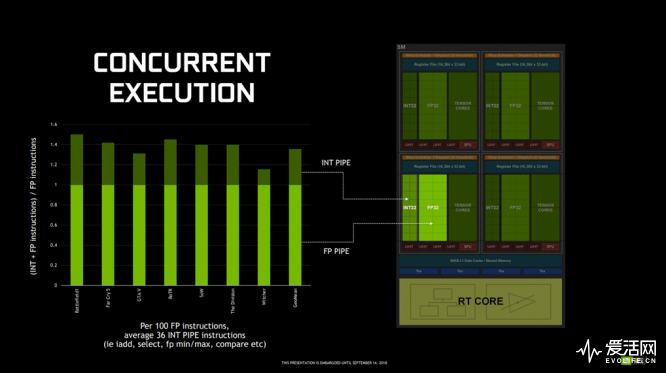
Turning相对Pascal最大的改变是增加了RT Core和Tensor Core,但在GTX 1650/1660上这两个部分都是没有的,但Turning还是相对Pascal增加了单独的INT单元。

以古墓丽影暗影为例,·100个指令之中有62个是浮点指令,38个是整数指令,在之前的Pascal架构,由于没有单独的整数单元,只能停下浮点指令来运算整数指令,而Turning架构就可以并行处理FP和INT,在62个指令周期就可以完成,性能提升了38%。
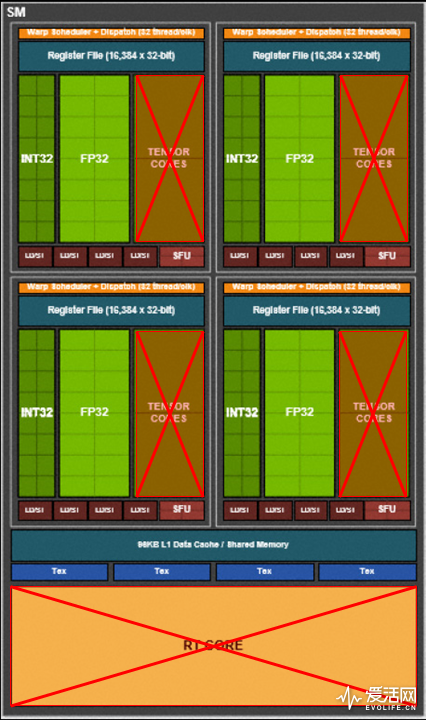
当然GTX 1650的核心架构和GTX 1660一样,去掉了Tensor Core和RT Core,这样使得其就缺失了硬件级的光线追踪和DLSS功能,但这样也降低了核心面积,据reddit分析,单个TPC可以节约1.95mm2的Die Size,而TU117有8个TPC,就可以降低15.6mm2的核心规模。

Turing的缓存结构也发生了很大的变化,改成了统一的的共享存储架构,每个LOAD/STORE UNIT对应一个64KB L1 Cache,每个TPC有32Bx4的带宽,是Pascal架构的4倍。Turing的L1 Cache是可以灵活配置的,每个TPC有两个SM,每个SM有32KB L1 Cache,这可以当成64KB统一使用,也可以当场两个32KB使用,相比Pascal架构有更低的延迟和更高的带宽。

Turning还支持自适应着色器,它可以对场景进行分析,依据场景的复杂程度和变化率给不同区域设定不同的着色率,这样 可以减少40%的工作量来实现几乎一样的输出品质。

可变着色率是和上面的自适应着色器差不多的技术,可以依据场景的复杂程度和变化率调节着色精度来节约资源。这个功能在之前RTX2080TI首发的时候就吹的很多,但实际这个功能在GTX 1650首发430.39才兑现。
理论性能方面我们使用3Dmark来衡量,DX11的Firestrike的图像分提升了20%不到,而DX12的Timespy提升了44%,采用新技术的游戏和测试能够从Turing架构的改进中获得更多的收益。
要发表评论,您必须先登录。



1650性价比不高啊 还是1660ti好
还是1660ti好
感觉可以升级了