
单卡4K时代降临 安培架构暨华硕TUF RTX 3080 GAMING首测

 登录|注册
登录|注册







家用机论坛特别喜欢讨论算力多少T,这个其实就是FP32的理论运算能力,我们也来简单算算。其实这个理论运算能力很容易算,直接拿流处理器数量乘以核心频率再乘2就出来了。因此在核心频率差不多的情况下,这个算力就完全和流处理器数量成正比。并且这个算力可以在很大程度反应光栅化的游戏性能水平。RTX 3090/3080流处理器数翻翻,再加名义上的Boost高频率,这样就使得FP32的算力可以轻松翻翻再转个弯。

将在今年年底发布的次世代主机Xbox series X和PS5两者即使是按灰烬频率也仅仅是10T出头,其还是又再次的被RTX3080/3090远远抛离,主要还是两三千的SP还是不能和上万的流处理器的暴力媲美。硬件未发售就落后,弟弟永远还是弟弟。
这次安培最让人惊奇的是NVIDIA是怎么把流处理器堆到10000多的。要搞清楚这个问题要从SM层次说起。
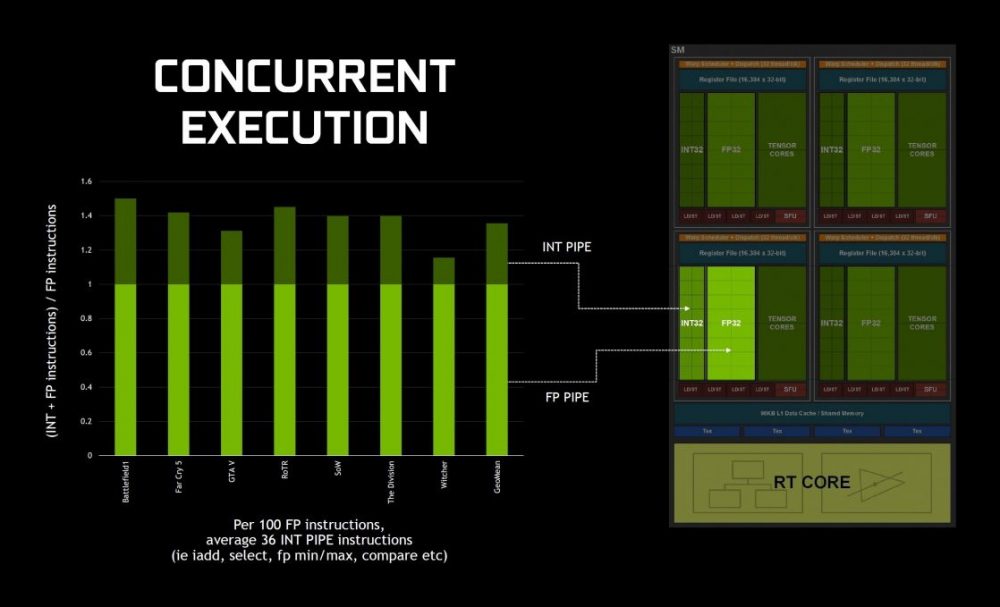
先来回顾下图灵的SM结构,一个图灵的SM有4个块,每个块有16个FP32和16个INT32。INT32单元是在图灵架构时候引入,是用来处理占比大概1/3的INT32任务。

INT32整数任务虽然占比不高,并且相比FP32浮点运算量不大,但在图灵之前的GPU跑INT32还是要浪费宝贵的FP32单元时钟周期来处理。图灵增加了复杂度不高的INT32单元以后,INT32和FP32就可以并行运行。以古墓丽影暗影为例,之前单纯依靠FP32单元切换任务轮流跑FP32和INT32需要100个周期的任务,现在INT32和FP32并行处理就只需要62个周期。增加简化的INT32单元,就可以在增加成本不多的情况下,解放高复杂度FP32的性能,将其从INT32的琐事中解放出来。
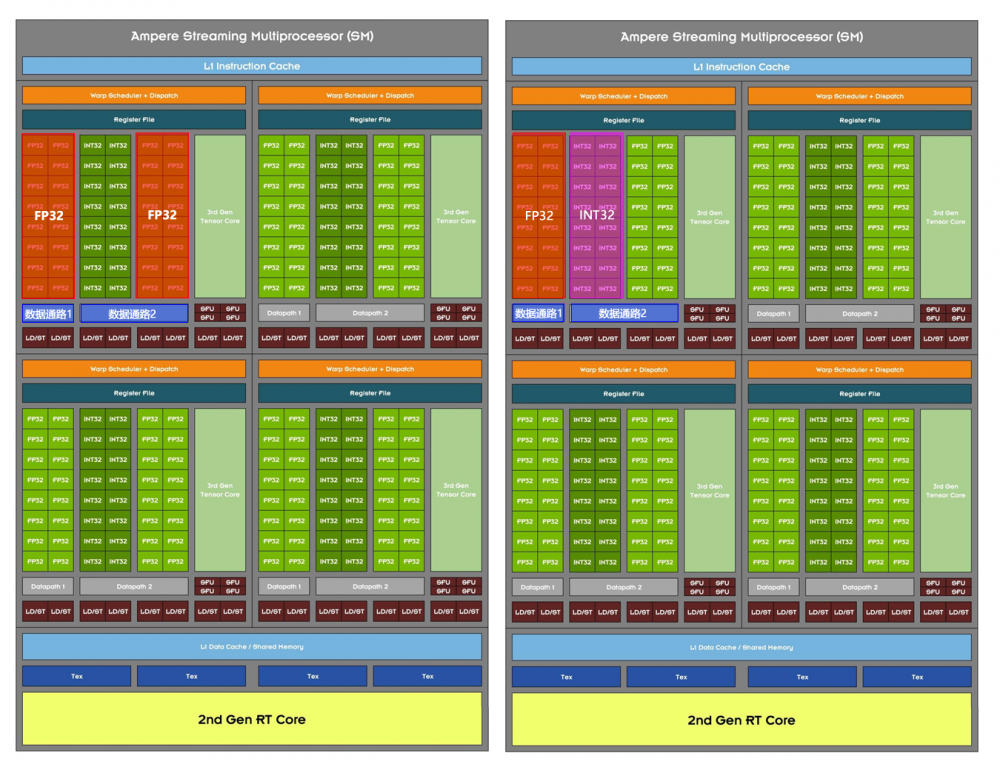 而安培在单个块里,有两组16个FP32和一组16个的INT32,但仅有2个数据通路,其中一组FP32独占一组数据通路,另外一组FP32和INT32共享一组,在共享的一组里FP32和IINT32不能同时执行,只能两者选其一。这样的设计在一个时钟周期内,要不跑16+16个FP32操作,要不跑16个FP32操作+16个INT32操作。
而安培在单个块里,有两组16个FP32和一组16个的INT32,但仅有2个数据通路,其中一组FP32独占一组数据通路,另外一组FP32和INT32共享一组,在共享的一组里FP32和IINT32不能同时执行,只能两者选其一。这样的设计在一个时钟周期内,要不跑16+16个FP32操作,要不跑16个FP32操作+16个INT32操作。
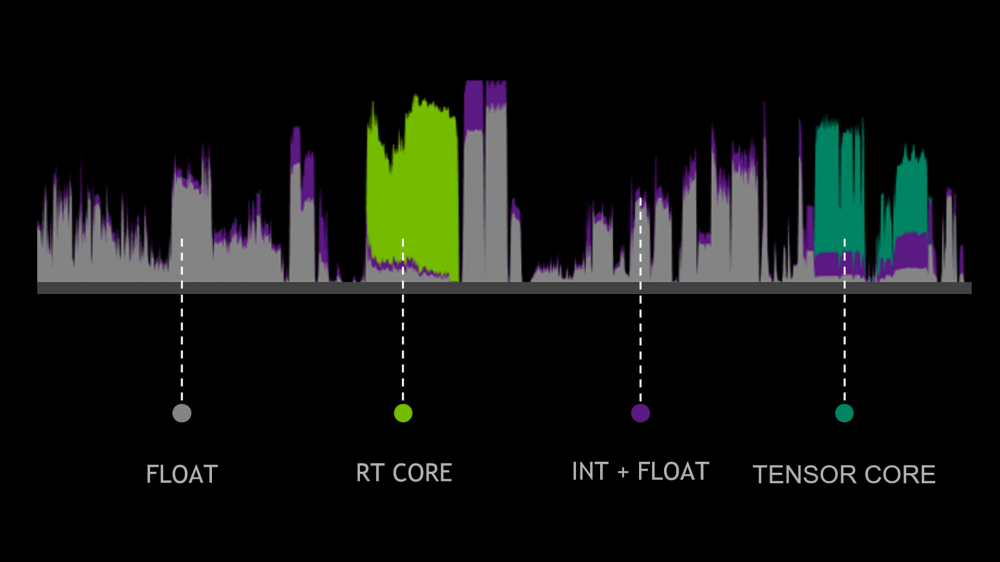
这是一个典型的光线追踪单桢的渲染时间,我们可以发现紫色的INT32虽然几乎全程都有参与,但其实占比很少,真正大头还是FP32。之前安培的FP32和INT32单元数量是1:1的比例,这样其实INT32的利用率并不高。而安培这样的一组FP32和INT32共享数据通路的设计,GPU可以依据应用需求,自由调节工作模式,在典型的游戏应用,可以在更多的块跑FP32,而仅用少数的块跑INT32。这样的设计虽然并不能使得所有的FP32都能同时工作,但可以在芯片复杂度提高不太多的情况下,大幅提升占比最大的FP32的性能,而次要的INT32也可以按需分配满足需求。使用不高成本提升最为经常性工作的效率,无疑是很聪明的做法。

由于FP32规模翻倍,也使得对缓存结构带来更高需求。安培SM里的L1缓存从图灵的96KB提升到128KB,单周期传输容量从图灵的32B提升到64B,这样RTX 3080 L1带宽就高达219GB/S,而之前的2080S仅为116GB/S,差不多翻番了。
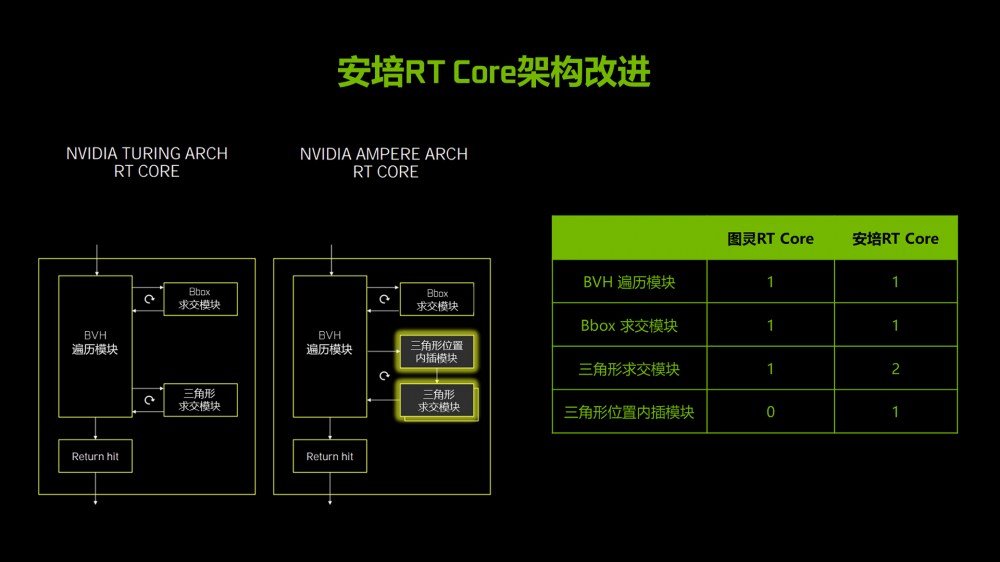
再来说说反传统性能部分。安培的RT Core相比图灵增加了一组三角形求交模块,然后添加了全新的三角形位置内插模块。特别是后者可以在求交计算时候预判目标三角形的位置来提升求交计算的效能,这样可以明显改善运动模糊场景的光追性能表现。

当然 光线的模拟追踪计算并不是RTX的全部,后续还有降噪的问题,RTX显卡是依靠独立的Tensor Core硬件来实现,而安培配备的是第三代的Tensor Core处理器。
 之前图灵的Tensor Core在处理FP16的情况下,可以看成4×4和4×4的矩阵,一共64个乘法单元核心,但到了RTX 30的安培,就变成了8×4和4×4的矩阵,这样就有128个FP16乘法单元核心。单个Tensor Core的性能实现了翻倍。
之前图灵的Tensor Core在处理FP16的情况下,可以看成4×4和4×4的矩阵,一共64个乘法单元核心,但到了RTX 30的安培,就变成了8×4和4×4的矩阵,这样就有128个FP16乘法单元核心。单个Tensor Core的性能实现了翻倍。
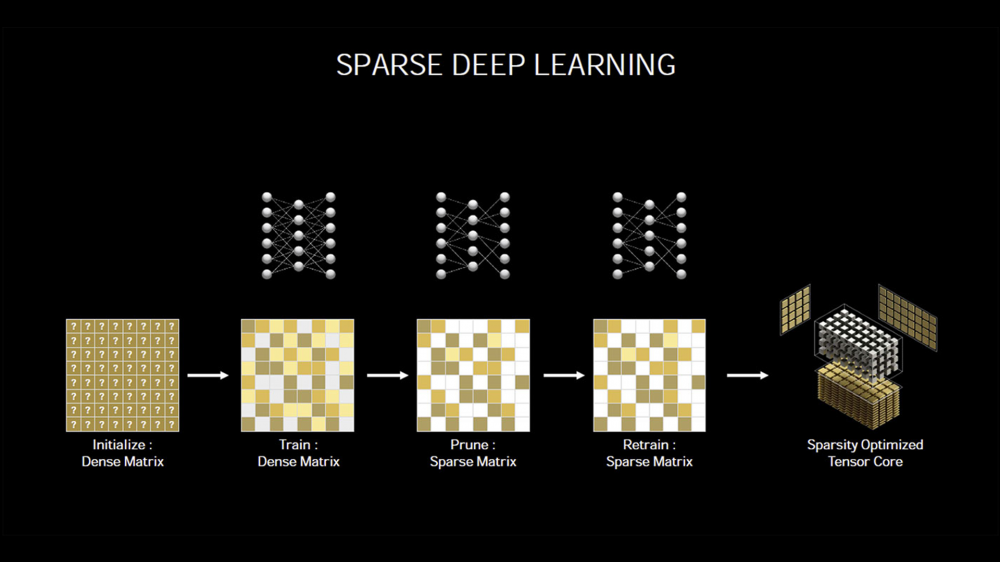 当然,除了单个Tensor Core规模的翻倍,安培的第三代Tensor Core在算法上也有很大的优化,其主要改进是稀疏化,稀疏化打个比方, 就是做模拟试题,不做全套,选择性的挑着有代表性的做,这样可以节约时间,但最终又可以得到八九不离十的训练效果。稀疏化就是通过这样取巧的方式来提升效能。
当然,除了单个Tensor Core规模的翻倍,安培的第三代Tensor Core在算法上也有很大的优化,其主要改进是稀疏化,稀疏化打个比方, 就是做模拟试题,不做全套,选择性的挑着有代表性的做,这样可以节约时间,但最终又可以得到八九不离十的训练效果。稀疏化就是通过这样取巧的方式来提升效能。
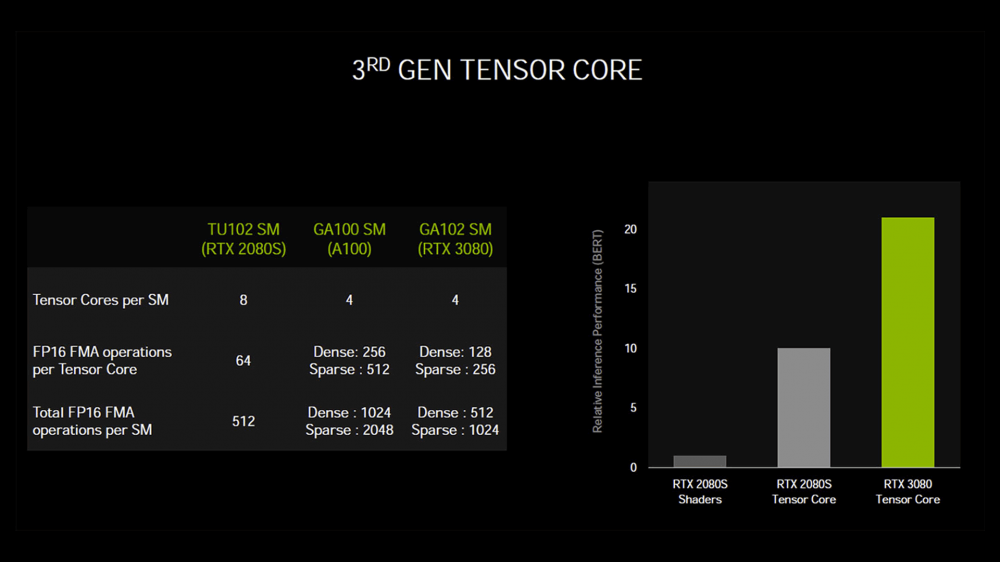
安培单个Tensor Core在未稀疏化的情况下,一个周期可以进行128次操作,是图灵的2倍,在稀疏化以后性能是图灵的4倍。虽然安培的单个SM的Tensor Core数量从图灵的8个减到4个。但在未稀疏化的情况下还是可以维持之前的性能,而在进行稀疏化之后,安培相比图灵还是性能翻翻了。并且这个还是单个SM的情况,我们还是需要考虑安培比同级别的图灵有更多的SM。

游戏中的每一帧都是各个部分分工协作完成,黄色的FP32负责传统光栅化,绿色的RT Core进行光线追踪的模拟计算,紫色的Tensor Core用来降噪,当然也可以用来处理DLSS,用较低分辨率这样不仅可以大幅提升光栅化的性能,还可以大幅降低光线的计算需求。以重返德军总部为例,没有Tensor Core参与大概只有50FPS,而通过Tensor Core来进行降噪和DLSS,就可以达到80FPS以上的性能。

从Xbox Series X的PDF初探RDNA2的光线追踪部分,其一个CU在一个时钟周期可以进行4次纹理或者光线操作,先不说其具体理论性能,需要注意的是“OR”,就是说纹理单元和光线追踪并不能同时进行,贴图和光线追踪会互相挤占性能。此外也没类似Tensor Core的专用单元,只能使用FP32来进行后期降噪,这也将挤占传统的光栅化性能。因此RNDA 2的光追性能现在看并不太乐观。
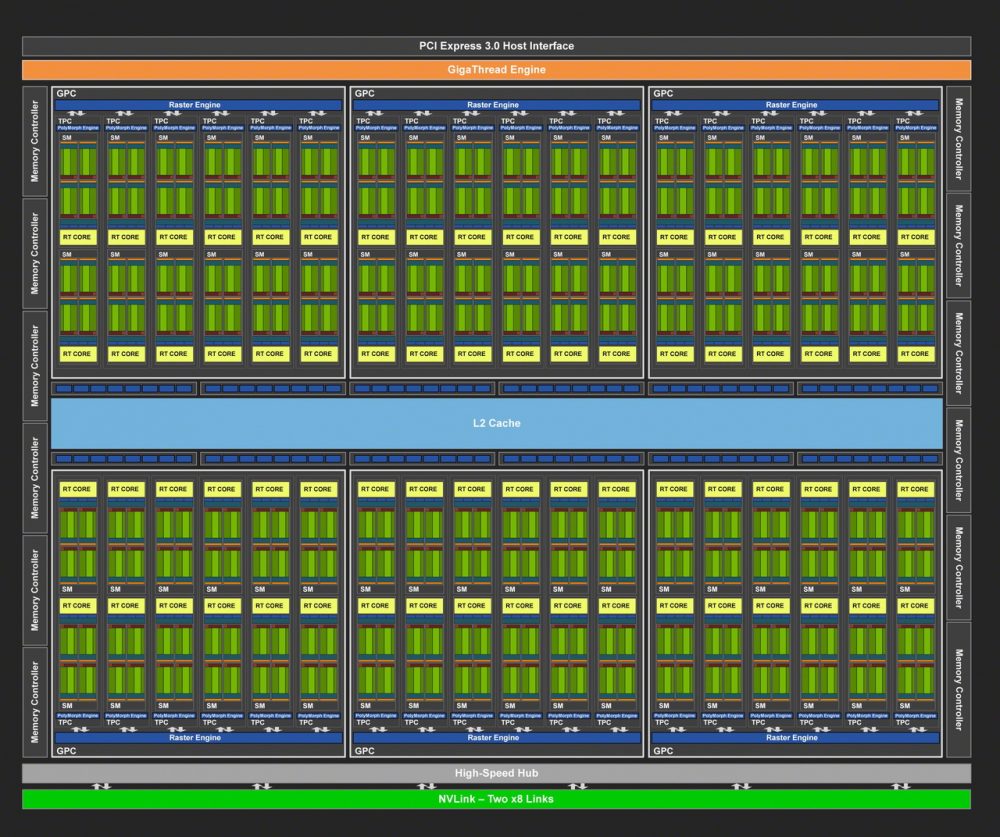
再来看看整体架构。满规格的TU102有6个GPC,每个GPC有12个SM,总计有72个SM。单个SM有64个SP。RTX2080TI实际屏蔽了4个SM,剩下的68个SM就是4352个SP。
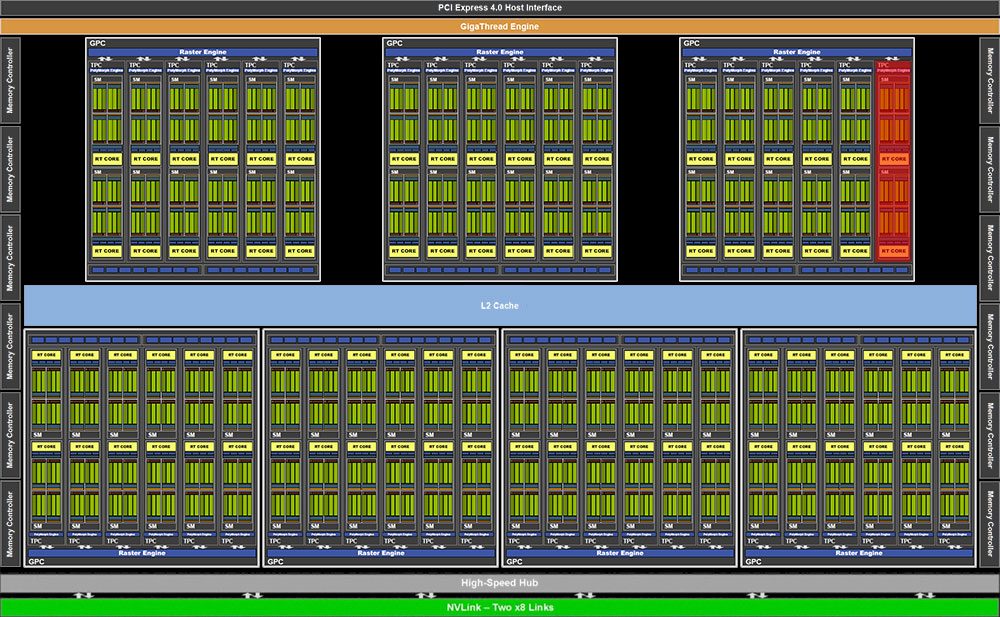
而GA102有7个GPC,每个GPC和图灵一样也是12个SM,7个GPC满规格就84个SM,但实际RTX3090屏蔽了2组SM,就有82组。单组SM安培从图灵的64个FP32翻倍到了128个,这样总计就有10496个FP32流处理器。此外每个GPC有一个光栅化引擎,里面有2个区域,每个区域有8个ROP,这样一个GPC有16个ROP,7个GPC一共有112个ROP。

这个是GA102的核心,我再这胡猜乱画的分布,红色的是7个GPC 蓝色是12个32bit内存控制器,黄色的是ROP,紫色的是L2缓存,绿色的是PCIE NVLINK等IO部分。

而RTX 3080屏蔽一组完整的GPC加4个SM,这样就是68个SM,这个SM数字和RTX 2080Ti一样。但单个SM的FP32从64翻翻到128,那整体的SP数量也从4352翻翻到8704个。完整的GA102有12组32bit的内存控制器,合计384bit,RTX3080屏蔽了2组,这样就剩下320Bit。此外RTX 3080还屏蔽了NVLink,使得其不具备SLI的能力。

其实这次安培的市场布局,对于老玩家而言,很容易让人想起14年前的G80,当时旗舰8800GTX是384bit 768MB,下面是320bit 320MB/640MB的8800GTS,这次3080 10GB规格完全对应8800GTS 320MB,当然不出意外稍后还会发布一个3080 20GB,那规格布局就一模一样了。

这次显存频率从原有的14Gbps提升到19.5Gbps,是因为采用了全新的美光GDDR6X,其相比之前的内存,一个周期高低电压电平传送1个bit 2个状态,变成4个0.25v间隔的电压位的PAM4信号,这样在一个时钟周期就可以传送2个bit 4个状态,这样一个时钟周期的传输速率就翻倍了,这样的差别比较像SSD SLC和MLC的差别。
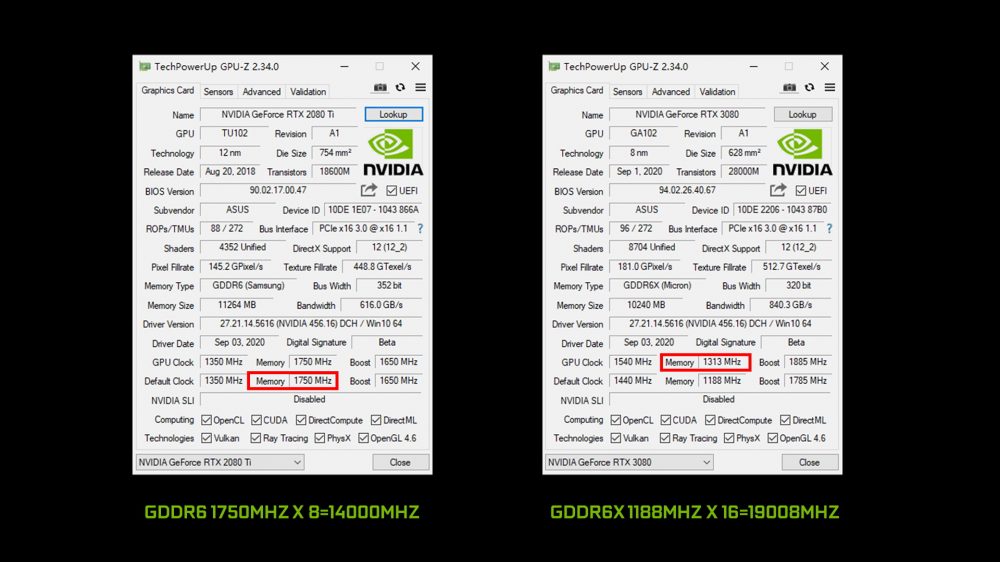
从GPU-Z 看,GDDR6的实际工作频率需要在频率上x8,而GDDR6X则需要X16,1188×16就是19GHz,GDDR6虽然等效频率很高,但实际工作频率反而很低,因此依然有比较大的超频空间,上到21GHz还是很轻松的,不过对于RTX 3080显存带宽并不是瓶颈,超显存并不能带来明显的性能提升。
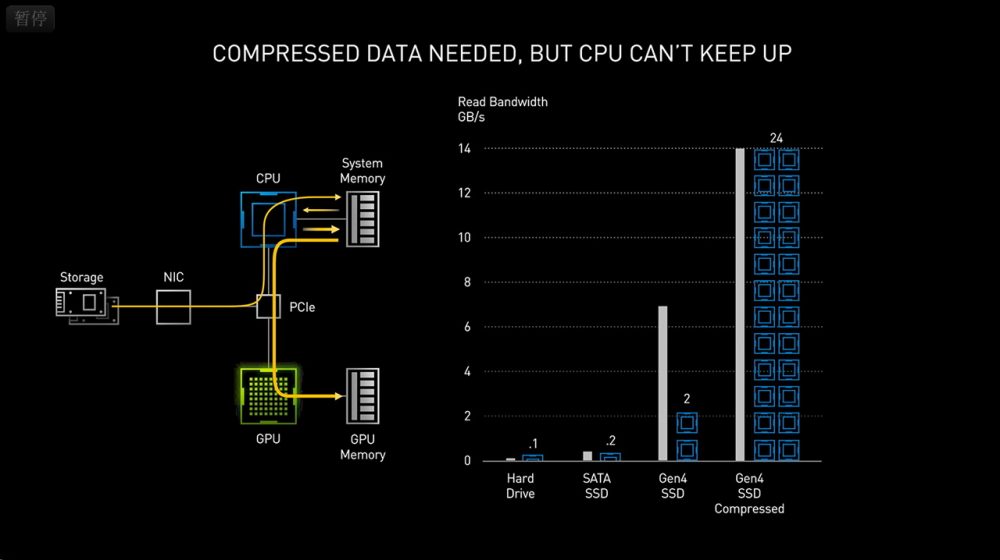
安培除了提升图形性能和深度学习性能,现在还狗拿耗子帮忙提升了下磁盘性能。现在GPU读取游戏数据,需要从SSD读取,通过PCIE总线,再到CPU,写入内存,再从内存读到CPU,再次通过PCIE传送到GPU,最后还需要写入显存,这样绕一大圈才完成操作。上面这个还是理想情况,实际情况是大多游戏为了控制容量,都会采用压缩数据,这样在到达内存之后,CPU需要再次读取解压再写入内存,还需要多一个来回,并且这个解压对于处理器的负载很高,甚至需要使用24个核心。
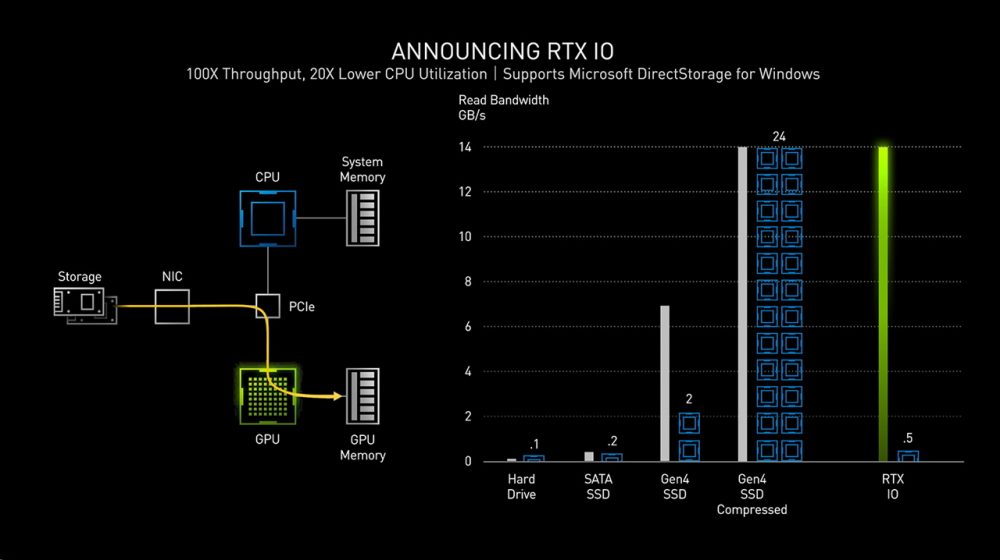
而RTX 30系列支持RTX IO,可以无需CPU和内存的干预,SSD的数据可以直接由PCIE总线传到GPU,并完成解压写入显存。这样大大简化了流程步骤,提升了性能,同时大幅降低了处理器的使用率。
现在3A游戏越来越多是大沙盘,视野距离越来越大,同屏物件也越来越多,因此RTX IO这样技术可以以串流的方式,无需CPU干预必然可以大幅提升游戏体验。当然为了实现RTX IO,还需要系统和游戏的支持,Windows 10估计需要等到下版甚至下下版才会实装Direct Stroage。而游戏支持方面,大多3A都是要登录Xbox series X,游戏支持方面应该也应该问题不大,估计年底以后新发布的大多数3A都会支持。
 3
3 0
0
 0
0 3
3





