


 204
204 186
186 204
204从现在知道的信息来看,应该还是ARM架构,除了ARM也没什么适合移动端的新架构。

 登录|注册
登录|注册






微架构实现细节对比总结
我们采用 AIAD64 5.8 4072 版进行了 Zen(Ryzen 7 1700X,这个微架构通常也被称作 ZenVer1)的指令时延、吞吐率测试,上表中的 MOV r32 到 VPCLMUL 等 20 条指令就是从其中 2000 多条指令中取出具有代表性的指令的测试结果,时延和吞吐率分别位于竖线的两侧,单位为周期。
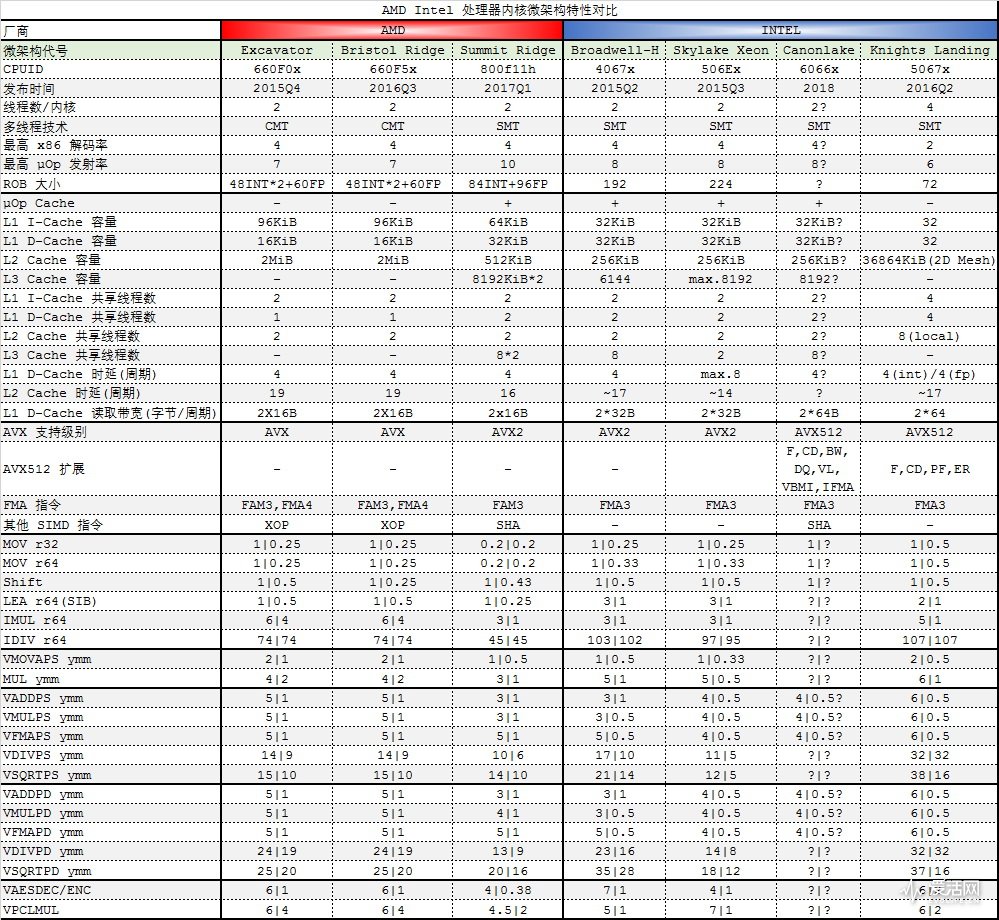
时延,就是指一条指令所需的数据如果是需要等待另一条指令计算出来的,那么这个等待的周期数就是指令的时延(latency)。例如,如果一条指令的时延是 6 个周期,则意味着它需要等待另一条指令 6 个周期才能获得所需的数据。吞吐,就是指一条指令需要花多少个周期来执行。如果吞吐是 3 个周期,那就意味着这条指令所需要的计算时间是 3 个周期,大家平时常说的每秒多少条指令,就是用处理器的频率除以这个指令吞吐周期数获得的。上表中涉及到 ymm 寄存器的测试都是 AVX 指令,有 PS 后缀的表示单精度紧缩方式,有 PD 后缀表示双精度紧缩方式。
从测试结果,我们得出以下结论:
1、Zen 的 MOV 指令比 Skylake 略快
2、整数除法(IDIV)指令只需要 45|45 个周期,而 Excavator 需要 74|74,英特尔这边的 IDIV 落后不少。
3、AVX 加法、乘法、FMA 指令吞吐性能要比 Skylake 慢 50%。
4、AVX 除法指令和 SRQT 速度不错。
5、AES 指令比 Intel 更快。
接下来,让我们看看 Zen 和 KabyLake 在 x87 和 SSE 指令方面的时延、吞吐对比:
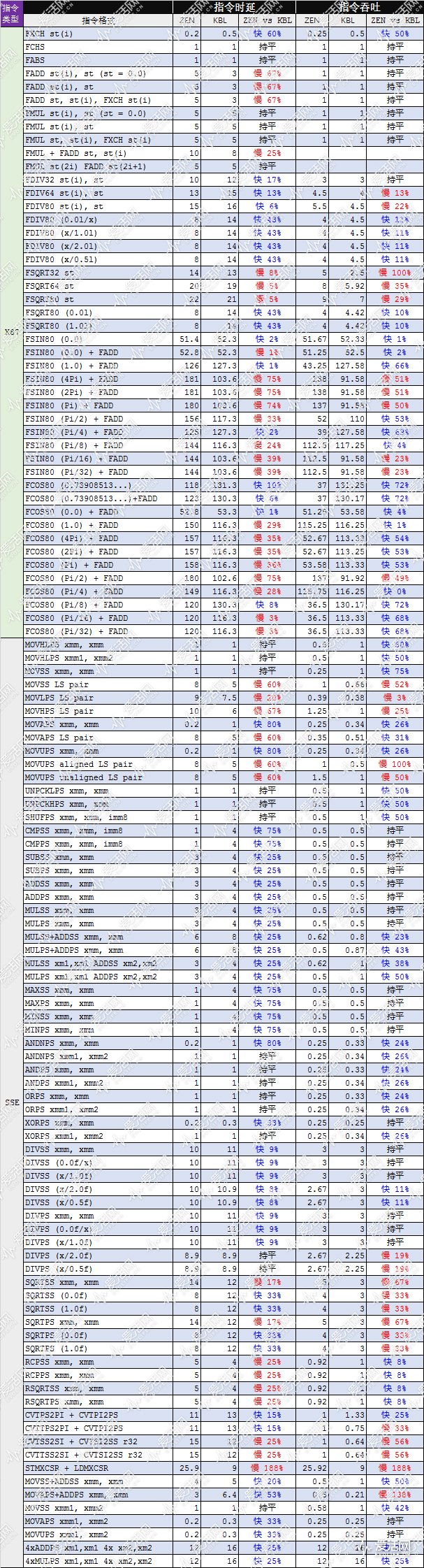
SSE 是游戏中比较常用的多媒体指令,从测试结果来看,SSE 加法、乘法指令两者相当,在有些情况下还有点优势,是在 SQRT 指令方面,Zen 要比 KabyLake 慢不少。
在 Pentium 4 或者说 Netburst 时代,大家经常提到的一个名词就是流水线深度,也就是流水线中细分了多少个工位,NetBurst 当时采用了 20 级流水线了,相较于同期也就是 10 级左右的其他处理器来说,采用这么长的流水线可以做到快很多的频率。
不过随之而来的问题是,较长的流水线深度对于乱序处理器而言,在遇到分支预测失败的时候,需要整个流水线清空,20 级流水线的分支预测惩罚一般是 20 个周期。
我们使用 Zen、KabyLake 以及 Broadwell 进行了分支预测失误惩罚的测试,结果如下:

上表中的左侧是以伪代码方式提供分支程序测试片段,以第 7 个测试(Test 6)为例:
从上图中可以看到,这个 Test 6 的 Zen 测试结果是 12.36 个周期,加上 MOVZX 的 5 个周期,那这个测试的有效结果 17 个周期。
从测试结果我们得出以下结论:
1、Zen 的分支预测惩罚在 17 到 21 个周期左右,KabyLake 是 16 到 20 个周期,Broadwell 是 15 到 21 个周期。总体来说 Broadwell 的分支惩罚普遍更低些,大概是 15 个周期左右,KabyLake 略高,为 17 个周期左右,Zen 的预测惩罚值普遍在 19 个周期左右。
我们通过测试推断 Zen 的流水线工位数应该是在 19 个左右,不过由于 µOp-Cache(微操作高速缓存)等因素,最低可以低至 17 个周期左右。
Zen 的 CPU 复合体(CPU Complex) 真假八核疑云? 2017年3月4日修订
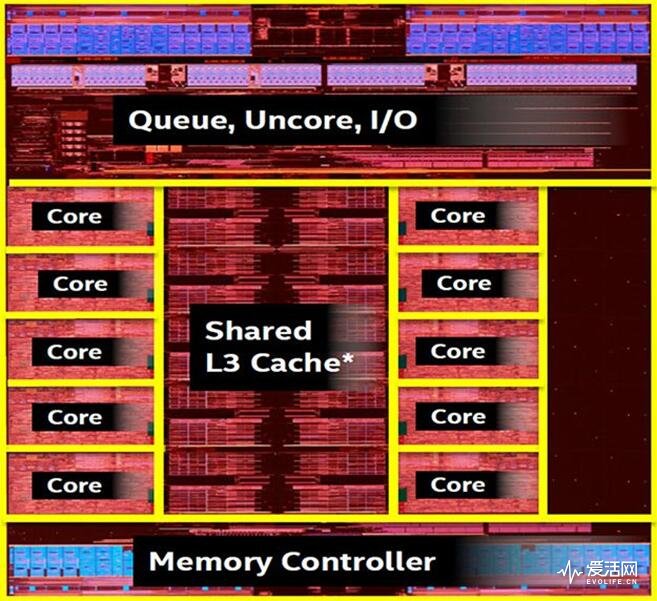
![]N%Z)3MEV~38W1_04H6E2@K](http://file.evolife.cn/2017/03/NZ3MEV38W1_04H6E2@K-666x449.png)
来自后藤弘茂的芯片架构分析指出,中间两大块是2组CCX核心,而左下和右上对头的是两组内存控制器。这样分析我们认为是相当合理准确的。Zen 采用名为 CPU 复合体(CPU Complex,简称 CCX)的形式进行内核组成,每个 CCX 包含有 4 个内核以及一块 L3 高速缓存,L3 高速缓存的容量是 8MiB,采用 16 路组相联和独占(相对 L2 高速缓存)设计。L3 高速缓存以低序交错地址的方式被切为 4 块,每个内核配有 2MiB L3 高速缓存,内核在访问各个 L3 片块的时候时延都是一样的,不过 Zen 的 L3 采用的是牺牲式(类似于 K8)。
就具体的处理器型号而言,一个 8 核处理器,是由两个 CCX 结合而成。需要注意的是,在 Zen 中,L3 高速缓存并非最后一级高速缓存(Last Level Cache,LLC),因为 16MiB L3 高速缓存是由两块分离的 L3 高速缓存组成,两个 CCX 之间不存在统一的 L3 高速缓存。

锐龙RYZEN 7两个CCX是独立的,其之间是采用Infinity Fabric进行连接,Infinity Fabric是AMD的次世代片上通信方案,不仅会用在ZEN上,还会用于VEGA和未来的ZEN架构APU。
Infinity Fabric 由两部分组成,分别是 Scalable Control Fabric 和 Scalable Data Fabric,其中 Scalable Data Fabric 是用于互联AMD处理器和存储器的数据总线,RYZEN 7互联两个 CCX 的就是 Scalable Data Fabric,其频率和内存时钟频率一样,例如搭配 DDR4-2400 的时候,SDF 的频率就是 1200MHz(AMD 在 GDC 2017 期间所做演讲的中提到的平台配置就是 DDR4-2400)。
根据德国硬件网站 pcgh.de 的报道,他们曾经就 SDF 的带宽询问过 AMD,AMD 的答复是 22GiB/s,据此推测,Ryzen 7 的 SDF 带宽应该是每个周期大约 18 字节,也就是 16 字节数据 + 2 字节校验(18 字节 * 1.2GHz =21.6GiB/s)。
毫无疑问,SDF 的带宽并不算高(低于双通道 DDR4-2400 内存带宽 38.4GiB/s),导致 8个内核不能像Boardwell-E那样直接互相通讯,两个不同CCX的内部内核通信无法达到CCX内部那样高效。
我们为了验证这个问题,进行了不同内核缓存通讯一致性性能测试。这个测试通过对两个不同的内核线程分别对两个数据块运算,然后反馈给另外一个线程以保证不同内核缓存的数据一致性,并且反复这个过程(也就是所谓的乒乓测试),我们记录这个过程耗时进行比较,来衡量不同内核的通信性能。
以下是Intel Boardwell-E各个核心之间的通讯延迟。
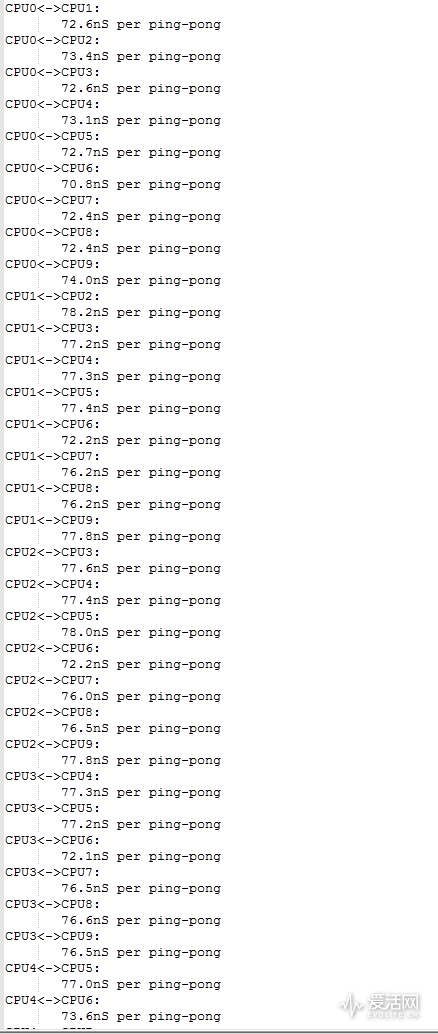
在具体测试我们中关闭了所有处理器的SMT超线程,Boardwell-e的6950x所有核心的L3缓存由于是共享的,其相互通信延迟为7x ns水平,十分平均稳定。
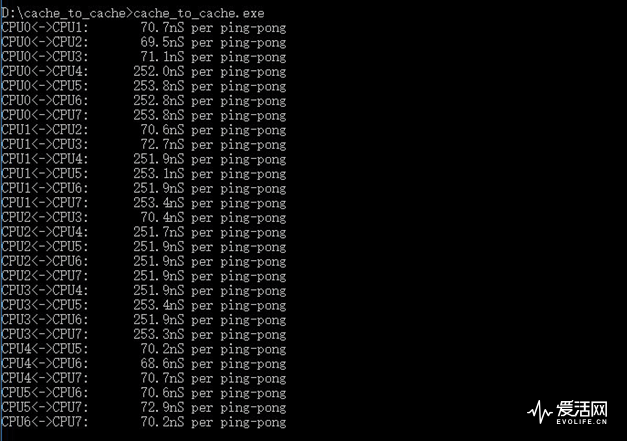
而RYZEN 7的0-3和4-7同CCX内核共享的片内缓存一致性通信耗时为7x水平,和Boardwell-E差不多,而0-3和4-7二组CCX直接的内核缓存相互的一致性传输耗时就高达250ns以上,这说明两个CCX之间的通信效率还是差于Boardwell-E平等分布结构。这个测试我们使用的是DDR4 2666内存,如果内存频率降到2133MHz时,一致性传输耗时会进一步减慢到280-290ns水平。这就基本证实了SDF的带宽和内存频率是有关的。
CCX之间的SDF的通信效率问题在线程间数据无需交换的时候问题不大,但是当线程数据需要交换的时候就会有不可忽视的负面影响。因此两个CCX独立L3缓存的效能还是明显差于Boardwell-E完全共享L3缓存架构。Boardwell-E的内核组织形式如下图。
我们认为AMD目前这个设计是出于对成本的妥协。英特尔主流架构和HEDT是独立开发,Boardwell-E共享L3缓存结构使得整个CPU架构都需要重新设计。而AMD也想要推出HEDT这样性能皇冠级别的产品,但在研发成本(Lisa Su 在接受专访的时候表示,AMD 砍掉了了许多项目以确保 Zen 和 Vega 可以研发成功)上并不允许他这样做,因此就想出 4 个内核绑定为一个 CCX的结构,两者用专门的高速总线进行连接。虽然这样的连接带宽和延迟不同于传统的胶水(也许就像Fabric字面意思那样叫 胶布?),但在性能表现上还是逊色于Boardwell-E那样真正全部内核共享L3缓存可以直接通讯的架构。
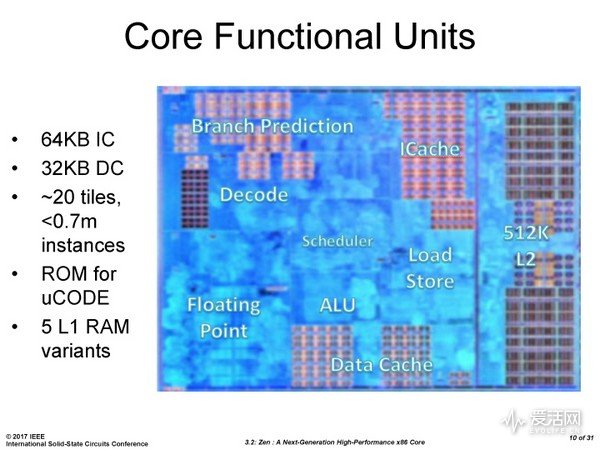
上图是 Zen 管芯图中单个内核的布局图,它的面积是 7 平方毫米,其中 L2 高速缓存大约是 1.5 平方毫米。图中标注了分支预测器、指令高速缓存、解码器、调度器、浮点单元、整数单元、载入/存取单元以及 L1 数据缓存以及 L2 高速缓存。
CCX 的面积是 44 平方毫米,其中 8MiB L3 高速缓存面积是 16 平方毫米,由 14 亿晶体管组成。与之相比,Intel 同样是 14 纳米工艺制程节点的 SkyLake 内核部分(不考虑 Uncore)的面积是 49 平方毫米。如果这样比较的话,Zen 四个内核的 CCX 比 Skylake 四内核小大约 8.3%。理论上 Zen 内核部分成本也会低 10.2%,但是这样的比较其实并没有多少意义(如果说这是为了表明成本更低,但是芯片的成本绝对不是这么简单的事情,例如销量,冗余分装等都是丝毫不亚于面积的因素,此外两个处理器本身在功能实现上也有很大差别,例如 Intel 的 CPU 还支持 Zen 目前尚未完全对等特性的 vPro)。

上图是 Zen 处理器 8 核版的管芯图,面积大约是 195 平方毫米,英特尔 14 纳米的 Broadwell-E(包括足本的 10 核版 i7-6950X 以及屏蔽两核的 8 核版 i7-6900K/i7-6800K 等)管芯面积是 246.3 平方毫米,后者的原生内核规模是 10 内核并且是 4 内存通道,所以如果考虑功能特性的话, 8 核版 Zen 在芯片成本潜力上并没有特别的优势。
要发表评论,您必须先登录。



好精细的文章 。
1700X屏蔽成4C8T是屏蔽一组CCX吗?
贴吧过来围观神文,太牛逼了,1年前就精确推测到后面的8700和2990wx,作者是amd的把
1年后再看,确实是厉害,后面的发展也和这个文章写的差不多
broadwell是15级流水线?kabylake是17级流水线?对应惩罚周期来看,是这样吗?
牛逼,牛逼,牛逼,这文章太他妈牛逼了
关于1700默认电压是1.35之高,在BIOS中关闭 自动睿频的功能 就会变成在1.03附近,之前在官超软件里观察,在单核到达最高加速频率3.7的时候 才会到达1.35V的电压。软件中超频到3.7G 电压1.25 ,满载功耗在105W附近。网上许多在1.2V的电压下就可以稳定3.7,可是我这个1.2V在X264编码中 会黑屏
电压太低了,系统不稳定,要么加压要么降频。
1.25 3.7大众体质。
你把防掉压等级 提升到最高 你就可以 1.21V 超频到3.7了
爱憎分明,好似cho大还魂,gz风采依旧
最后的价格有问题,这价格是microcenter的价格,全美仅仅十几个或者二十几个店铺,绝大多数的美国人是不能够以这价格买到的,因为intel不给microcenter在网上卖。我建议还是以亚马逊或者新蛋的价格为准。(ps我才不会说两年前295买的5820k 上周以312价格卖走)
所以我们依然要选择I5/I7 。农企翻身,不存在的
服气
看了大炮村的i3秒1800x文章,说是抄这里的,一上午看完,只能膜拜大神
请问内存3000下的L3延迟是多少
RYZEN暂时无法再DDR4 3000 2CH下稳定工作。
PRO-A大神能不能提供个LLC延迟测试脚本?我们在设计的一款CPU也有LLC,想测试下
文中有个错误,SSE类指令集和AES指令集都是128bit,而AVX和AVX2都是256bit,64bit的是已经被淘汰的MMX。
SSE是32bit单精度,4d向量是128bit。
没听说过SSE是32bit单精度的说法。
SSE支持32bit、64bit浮点的向量操作,SSE2扩展了对8bit、16bit、32bit、64bit整数的向量操作,而SSE的XMM向量寄存器的宽度是128bit。
相对应的,AVX支持浮点的操作,AVX2扩展了对整数的操作。
请复习IEEE754
我从事这个行业这么多年,第一次听说SSE是128bit
居然认真地看完了……我是A粉么?!
技术兵力一个层级?小编你真敢吹!!!!
以前是父与子,现在是大哥与小弟,虽然还是不及,但至少是“同辈”了。
后藤那个图是不是有问题?看起来左上角那块更像MC,而标注MC的部分反而是IO
6666666666
基本参考wikichip翻译。。。
文章比cpu本身有趣多了,这是至今中文cpu评测最强无疑
要是能出四核心八线程版本对应i3的价格区间那还是不错的选择
核心数量太多并没有太大用处
前来膜拜神文
從超頻結果可見,GF仍然是AMD最大的拖後腿
要不要考慮去抱INTEL大腿,INTEL代工招商中,ZEN配INTEL 14NM還不屌炸天? XD
三星和台積電不知道有沒有機會代工了
回归神来这篇评论已经爆满了啊
小编,文中Ryzen 7 1700X模拟Ryzen 5的同频4GHz测试,是屏蔽一组CCX而来的吗?
周末再来读一次
跪拜。好文!
写的太棒了~!
编辑搜集了相当多的数据资料,整理论述的相当专业和详实,菜鸟膜拜!
特地为了点赞和评论注册!
跪拜,好文。
新注册,来顶。
这篇文章太有深度了。我完全可以说我不需要跪舔作者了。从昨天晚上看到就一直研究到今天中午,看了不下五遍。想不起来已经多少年没有看到这样的好文章了。下面是我自己的私货:
以下是我个人的一些结论,有许多有问题的地方,恳请作者指正:
1、本代ryzen的SMT对单核性能的较明显的影响是硬伤,不是可以通过优化、升级bios等可以解决的。
2、zen相对于目前kabylake/broadwell-E在指令集上的优势是SHA
3、ryzen的下一代可能会着重解决SMT的效率问题,也就是CCX的问题
4、如果ryzen的流水线是19级,那可能是amd为了能拉高频而妥协的。理论上应该能比skylake/kabylake更能超频。然而被垃圾14nm坑了(也许早就料到了所以设计的长流水线?)
此外也可以得出intel一方的一些结论:
1、skylake/kabylake并不是简单的挤牙膏。从之前我了解到的从四发射改为五发射(1复杂4简单),到现在流水线也可能增加了(haswell是14级,skl的增加是为了应对intel初期的14nm的难超频??)导致分支预测的惩罚周期增加,最终导致额外增加的1个发射数并没有理论中对性能的明显提升
2、如果按泄露的skylake XEON的L2从每核心512k增加到1M,以及AVX512的加入。如果HEDT的skylake-X使用同样的设计,相对于broadwell-E,性能会有飞跃式的提升。到今年Q3发布时应该会有好戏看了
3、intel下代的coffeelake(cannonlake?)可能会引入SHA、降低流水线长度。到时候跑分(撸大师?)可能又会有很大提升
SMT、单核性能问题已经增补跨CCX延迟测试。RYZEN的19级流水线确实弥补了GF14nm的短板,但付出了巨大的代价。在我看来第一代Zen在Core部分不过不失,而uncore部分短板明显。Intel如果后续SLX、KBLX同步登场,且在主流引入6C16T,对AMD影响巨大。
GZ上的主帖怎么不去回了?
这都预测到了。 牙膏厂8700k确实给锐龙带来了巨大冲击
单纯从理论性能上而已,RYZEN 7多线程性能要高于Kabylake,定价也仅仅是持平或者稍高。不认同这句话。
这文章我喜欢,这评论更喜欢,作者很专业的道出本真,读者没有跟风无理谩骂,很有气氛
八核到底适不适合一般人家用途,想起联发科的10核cpu了,很好玩
PC和手机不一样,手机是若干个高功耗核心+若干个低功耗核心,无法同时打开。
写的确实是好啊,在我看来除非是那帮搞龙芯的人,或者intel amd的内部人士。
amd是做的不错,大架构有牛人,但成功很在乎细节。这就是amd的弱项了,毕竟
人手不够啊
台積電的16NM還是要比samsung GF的14NM要好的
zen可以直接用服務器上面的內存么?
還是專用條?
RYZEN默认就支持ECC RAM,但不支持ECC+REG。
還記得K10各核心的異頻運作嗎,其實到FX亦沒問題,可能Ryzen可以也不一定,而且M$一直也沒有移除異頻支持
當初XP那個更新不過是注冊表補丁,所以反向而行就好
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\Throttle]
“PerfEnablePackageIdle”=dword:00000000
現在你的CPU就像手機處理器般可以異頻啦
當然,因為工作量橫跨各處理器後導致閾值不達標而不作升頻又是另一回事了。
看手機處理器異頻工作、甚至大小核也沒問題,不是M$不作為的話是什麼
可能會更好超呢XD
以前工作量橫跨各處理器,或工作量在各處理器間走來走去似乎是為了降低發熱(以前的CPU沒深度睡眠什麼的),平衡CPU的老化可能也是個考量?
但現在再這麼做不過是增加功耗和發熱量。
看見什麼w7跑得比w10快,不要神化什麼调度器,可能那只是Core Parking的問題
w7的Core Parking是預設一核心開一個(實體cpu0)停一個(虛似cpu1),而w10是兩個都停掉,在注冊表PowerSettings那裏w8原本有一個隱藏的新選項可以選擇停一個定兩個一齊停掉,但w10不知道為什麼又移除掉
Core Parking是根據閾值壓制CPU核心的使用,一點也不智能,那些隱藏的閾值選項可以在注冊表PowerSettings那裏自己開來改,「壓制」和「調度」八字也扯不上吧
扒去Core Parking的外皮後即和XP的调度方式沒大區別
最好笑還有對雞血補丁的神化,M$不過將推土機當HT處理器一般的識別,將Core Parking套上去而己吧
希望M$不要再交行貨了(小修小補),認真整一個新的調度器出來,不要再戰十年
難道要等核心發展到過百才醒悟嗎
另外,这几年CPU/SoC的设计都是尽量的在功耗控制方面与系统去耦合。这主要是因为处理器并没有办法选择执行什么代码,而总是有弱智代码会请求远高于需求的资源。
Windows for IA64是重构的调度器,也是一次彻底放弃x86历史包袱的机会,然而被X64取代了。
你看到的WIndows CPU Usage其实只是图形化的表述,从core i7 4xxx开始就已经引入了粒度非常小的供电控制平面和负载控制平面。简单地说,你可以关闭所有省电功能,而在相同负载下CPU的功耗并不会显著上升。
;要在平衡計劃關Core Parking?
;在「電源選項」內打開控制Core Parking的開關吧
;Processor performance core parking min cores
;設置100%等於關閉Core Parking
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Power\PowerSettings\54533251-82be-4824-96c1-47b60b740d00\0cc5b647-c1df-4637-891a-dec35c318583]
“Attributes”=dword:00000000
;自主模式那麼先進的東西,可能只有SkyLake以上才支持
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Power\PowerSettings\54533251-82be-4824-96c1-47b60b740d00\8baa4a8a-14c6-4451-8e8b-14bdbd197537]
“Attributes”=dword:00000000
;另一個先進的東西,可能也是SkyLake以上才支持
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Power\PowerSettings\54533251-82be-4824-96c1-47b60b740d00\be337238-0d82-4146-a960-4f3749d470c7]
“Attributes”=dword:00000000
沒有Core Parking這個外掛根據閾值壓住CPU不給你用後,調度上其實和XP沒多少區別,只是一個喜歡將新線程從最後的CPU激活起來,一個不是,但他們的共通點就是喜歡將工作量橫跨所有CPU,完全違反近代CPU當越少內核被激活,運行頻率則越高的大原則,由Turbo Boost/推土機MAX Turbo出現到現在都好幾年啦,這就是M$在調度器設計的不作為吧。
>这样的软肋并非像昨天LISA SU电话会议宣称那样可以通过软件解决。
M$可以將兩個CCX借鑒雙路CPU的處理法,線程盡量不橫跨去另一個CCX?
每想到C6深度睡眠配合差異過大的升降頻而導致音效輸出出現的噪音…你真的要關Core Parking嗎
可谷狗c6 noise sound之類,簡直歷史由久,希望Ryzen的主板不會再有,難受。
在SMT情况下要确保线程全部处于单个CCX而不交互,难度非常大,可能需要编译器支持。
某些大大可能亂改那些隱藏設置後會想還原
例如平衡計劃的處理器設置「54533251-82be-4824-96c1-47b60b740d00」就到
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Power\User\PowerSchemes\381b4222-f694-41f0-9685-ff5bb260df2e\54533251-82be-4824-96c1-47b60b740d00
取得所有權和權限後將它「54533251-82be-4824-96c1-47b60b740d00」整個刪掉即可
知乎上看到过来看全文,请问作者是否能开通知乎认证号?是否允许全文转载?
简直是史诗级的文章,能否转载?比我们现在学的大学教材强太多了
不同cpu所针对的应用方向肯定不同。
纯游戏玩家高频7700k intel占优势 游戏推荐 7700k>1800x>1700x
平时喜欢一边办公,一边看看电影,一边又上着上网、一边直播等多任务进行,zen的多线程优势非常明显。
非纯游戏玩家推荐 1800x>1700x>7700k
zen的意思“禅”,zen设计初期估计也是想要各方面均衡,性能与功耗不能同时兼顾。所以zen各方面即不突出也不落后。更适用于家庭和办公使用及各类设计工作站。
敌在PR部
真的很精彩,收藏了、慢慢嚼
1800X看起来也就是3代i7 3770K的水准,多了四个核心而已
6950X看上去就像是3代3770K的水准,多了六个核心而已(滑稽
厉害了,这篇文章写得真的很好很详细,干货也很足,感觉别的网站小编都要学习一个啊!
N年前看过关于手机CPU的一片文章写的也很好,在爱活网,今天注册了个账号。
通篇看完,发现有很多错别字,希望可以修正。
今日完成了对RYZEN7处理器CCX组织的验证,本人发现RYZEN7这代是4+4架构,并且L3延迟一致性差异巨大。
AMD胶水8核被PRO-A大师揪出来一剑封喉了Orz
关于苹果收购P.A. Semi那段,特意去搜了下,是2.78亿美元。
感谢提出,已修订。
我非常赞同你对apple的ARM芯片研发的评论,apple目前的微架构设计能力不在intel之下,也许再过几个月,比Ryzen更令intel焦虑的是apple的A11。
把苹果的架构设计能力和英特尔比?呵呵。
你难道没发现Jim这帮人搞K7 K8时AMD就和intel一个水平,一旦他们离开就是AMD的推土机垃圾? 他们再次回到AMD,又是ZEN这种与intel相当的水准。 那么Jim及其师傅在AMD之外搞的项目就”大失水准”了吗? 肯定不是。2006年PA的pwrfficient就和core 2一个水平,apple Mac是计划要使用pwrfficient的,后来乔布斯转向core2,其真正原因是乔布斯想让PA陷于绝境然后吞并之, 在apple金元滋润下A系芯片都搞起人工布线。目前 A10的perf/Mhz都已经接近 x86桌面产品,不服就跑个SPEC 06看看。以apple的控制癖,将intel u请出Mac 产品线只是时间问题,PA的pwrfficient是玩了一次曲线救国而已。
pwrfficient是Core2水平?呵呵,PWF后面基本就是Apple A5,不懂别乱YY
处理器设计领域,本人最佩服Dobberpuhl和Pat Gelsinger
本人认为在这个时代讨论ISA而忽略实现是无意义的。Apple确实拥有ARM ISA阵营里最强的架构和实现。
PWRficient 的SPEC你可以去查,考虑到功耗,和core2媲美完全没问题。另外,乔布斯收购了PA等公司之后, 把cpu设计团队分成2支, 一支去搞公版cortex,A4=Cortex A8,A5=CortexA9,另一支则在A4A5应付的两年内研发出自主微架构A6,乃至A7A8A9A10,这自主微架构的ARM才是这帮人的真实水平,说白了,intel的atom/coreM在移动领域算是遇到StrongARM 2.0了,intel力不能支啊。
从Cyclone(A7),Apple就已经有业界Top 5的CPU架构和设计团队了。Dobberpuhl也是在此时退休的。
照你这么说三星猎户座准备也要吊炸天了呢
安卓阵营ARM的IPC只有A10的一半左右,你开什么玩笑。
猎户座也有设计?不是1:1的ARM标准实现吗?楼主真的懂?
今天看国内外媒体都说Ryzen有19级流水线,点引用发现都是这篇文章。能否给出更多验证过程?
分支预测失败惩罚循环测试中已经有充足数据验证。
深度好文章!感谢作者这么用心!
跪着读完
看完这篇文章,注册个账号
通篇读完觉得作者的评价还是具有一些主观的痕迹,您对产品的技术方案选用和销售策略的推定我看不大懂,里边似乎有一些前后矛盾的地方,比如不用“钎焊“是因为自信,而用了是“勤能补拙“,这个说法让我有些不明就里。另外关于反垄断法案,可能我和您的理解有一些偏差,我不认为intel作为技术企业会因为技术上的领先导致该方面的法务纠纷。抛开测试数据,不少评价文字让人觉得:恰恰是amd带来的压力成为了Intel继续成功的条件,因而大家应该对intel当前和今后的产品更有信心,比如降价的7700k和日后不知什么型号的i357。。。我觉得把数据摆上就够了,评价的事交给读者自己去做就好。作为一名从事相关专业多年的工作者同时也是一名普通消费者的一点个人看法。
用硅脂封装还是钎焊主要建立在Intel 14 vs GF14基础上。本人认为GF14不适合用来生产高性能桌面处理器。AMD被迫使用GF14后已经把1800X性能推向了工艺极限。
补充:首发产品就逼近工艺极限,对任何半导体来说都不是好事。
下一代ZEN+应该还会有工艺改进吧?
另外那些12nm 4nm都是些什么鬼
确实,首发就推到工艺极限确实不是好事,例如黄老板的呆瓜处理器。本来是坑的高通骁龙不要不要的。结果一下子自己坑死了。变成平板CPU
前排围观神文
炮村的顾大师消失之后,很少能有媒体能达到这样的深度。
顾X这种是就比提了,YY成分比较高 ,时常写出来批判amd一番搞得自己要比厂商牛逼一样,各种私底下各种讽刺amd怀着偏见写出来的的东西就吧amd说得一文不值,去看看当年他写的7970各种表达对amd失望,设计各种不合理,现在不是打脸了吗
看了两年爱活 看到这篇文章特意注册个账号支持一下
别人都能看懂的文章。。我看不懂。。。
炸裂
为啥温度这么高
本人认为GF14nm并不是制造高频率桌面处理器的最佳选择。
特意注册一个帐号,回复一下。
目前中文最好评测。
写的好! 求更多
很久没看到这种好文了,确实不错!
这哪是AMD翻身,分明是爱活评测翻身了
爱活评测本来就很有水准,高通塞钱之前的手机cpu评测简直是所有网站里最详细的。
evolife原本就是3C业界的dalao们搞出来的,很多作者都是从上个世纪写到现在。
翻身了!!!!
目测爱活硬起来 硬起来
大神啊,我一个字一个字,读完了。精品评测文,比超能写的好太多了,那些大炮村、大炮洋,我是一目一段,蛆家评测一目十行,写的什么玩意儿!AMD Ryzen评测这篇是最深入的,国外的Anandtech网站都望其项背啊!神,大神啊!
好文章,学习了~
服了,其中还有好多看不懂
跪着看完了,服
贴吧过来都看哭了
作为混卡巴的小白表示这篇文章真的很强很详细有些根本看不懂。。
PRO-A是哪位大神编辑?竟能写入如此深度好文 有当年《微型计算机》的感觉
微机不就是intel御用枪手么
PRO-A是哪位大神编辑?竟能写入如此深度好文 有当年《微型计算机》的感觉
感觉亚洲也就后藤弘茂能比了
後藤なんか、Pro-A先生に比べるもんじゃないよ
扛鼎
难得的好文章,学习了
用测试把amd不想说的故意模糊的全部验证出来大写服
这文章缺少了编译器性能测试,还有就是specint测试,这两样是最体现理论性能的
农企岂不是要脸着地?
SPEC里面RYZEN的成绩很难看。但这主要原因可能是编译器。
phoronix 和 openbenchmarking 上有编译 linux 内核的测试,编译器参数都很全。
Ryzen需要Linux Kernel 4.9.10以上才能正常使用。现在还没有合适的开源编译器脚本进行测试。
phoronix 测试用的貌似是 ubuntu 自己编译好的 4.10.0-9-generic,gcc 有 -march=znver1 参数优化。
谢谢提出,稍后测试。
AMD貌似有了自己的GCC编译器?
手机上看坐过站了。。。精彩
真比那些什么小编高不知道哪里去了
2ch上居然有这篇文章的日文编译,日本人只编译了一半不过瘾,来看下全文
量大 没那么快
求个日文版传送门
Superpi测的是整数性能,全文很好,但犯这种低级错误只能说白璧微瑕。
别闹,确实有一些笔误但是Super PI测试的是浮点没错
SuperPi主要考察处理器的浮点性能。
太可怕了,是爱活么?感觉今天正面刚了其他站
目测爱活硬起来各类it门户都得跪
希望有一大波软件支持zen后的重新测试
看了半天,最后几段才是作者想说的。这么多线程日常是没用的,单线程性能好才是最有用的。intel构架的单线程比RYZEN好。。。同理就是要买intel的才是最佳的选择的。我也只能呵呵了
那么长的文章,我居然在手机上看完了,太精彩了
写的太好了,感谢
屏蔽线程测试。。。有误导。。。感觉整个测试就是向着iu有利的方面做。。
同感,amd真正优势在多线程
Zen的L3存在较大问题,多线程也不会有优势。
虽然长,但是全是干货没一句废话
小编,文中的Ryzen 4核 是屏蔽一组CCX而来的吧?
不是,AMD的8C和4C是两种不同的DIE,这是出于成本考虑的
高通GPU是ATI的 纳尼
这的确是真事,不然高通哪来这么给力的GPU?
从Adreno 300开始高通基本完全改掉了Imageon的架构,现在的更接近PowerVR
感觉是AMD中出了个叛徒
“AMD是说到做到的公司。” ——AMD时任CEO Rory Read 笑死我了
pro-a丢了黑人问号过来hhhhhhhh
一项集体诉讼已经把芯片制造商AMD公司告上加州法院,这项诉讼原告声称AMD涉嫌欺骗消费者,通过夸大推土机核心数量,误导消费者购买其推土机处理器。
当年判决是AMD赢
这样抖包袱晒资深有意思么?10年前Pro-A就被扒皮是AMD Austin的
Austin不就是设计了垃圾推土机么?呵呵,这也好意思叫大师?
proa丢了黑人问号过来hhhhhhhh
真恶心,捧杀AMD有意思么?
没有意思么?
看了其他网站的文章,确实和这个相比天渊之别
CTO叫Papermaster,这真的不是恶搞么?
AMD现任CTO确实是叫Mark Papermaster
太猛了,很多内容第一次看到,作者是AMD工作了很多年的吧?
原来AMD也要给GF分手费的,哈哈哈哈哈哈哈
这篇文章是否可以转载?
那个工艺对比……台漏电,哈哈哈哈哈
无论如何,AMD还是赢了,价格便宜,性能更强,这个结论并没有变化。
又一个没看懂就单方面宣布胜利的
赢在哪?哪里能看出AMD赢了?
贴吧观光团特来观摩
大炮村之流看上去就像是小学生写的作文,DIY后继无人了啊
同感,估计才刚学会跑分
太可怕了,这是直接扒皮裸奔
垃圾评测,活该你们用一辈子1万多的CPU
fx57用户表示这U可用一辈子.手动滑稽
震撼……
太牛了,看了那么多网站的Ryzen评测,只有这篇没用AMD的官方文档
终于看完了,AMD的功耗是虚标的啊?L3为啥那么慢?
这个问题已经验证完成写入本文内,AMD跨CCX之间连接的有巨大延迟。
博弈啊,AMD的HEDT平台胶水一下就可以了···
Pro-A憋了十年的毒奶助力农企成功360度翻身????
这位大牛以前在哪里发文章?10年前我还是小学生……
ATI没死GZEASY还健在的年代
原来PRO-A大师去了宁美国度!
原来农企假翻身
PRO-A大师,555555
PRO-A重现江湖
这是完全把RYZEN扒皮啊,AMD杀手已经上路
别人会写的内容,我不写。别人跑过的测试,我不跑。别人写透写明白的内容,我不写。太牛了
AMD要发律师函了
PRO-A大师,哭了……10年没出来了
爱活后台很硬啊