
追光者 NVIDIA GeForce RTX 2080 Ti图灵架构浅析

 登录|注册
登录|注册






自从 2006 年 11 月发布 G80 至今,NVIDIA 已经推出了多代支持 CUDA 的 GPU 微架构,它们分别是 Tesla 特斯拉、Fermi 费米、Kepler 开普勒、Maxwell 麦克斯韦尔、Pascal 帕斯卡、Volta 伏特,以及在半个月前才刚刚发布的 Turing 图灵。
如果大家有关心前两年 NVIDIA 发布的架构路线图的话,应该都知道,当时的架构路线图最后一个代号是 Volta,在这之后 NVIDIA 的路线图一直未更新。
按照 NVIDIA 以往的做法,在 Fermi 之后的每代微架构,都会衍生超算、高端、中端、低端/入门四个产品线,例如 Pascal 微架构下,有 GP100、GP102、GP104、GP106、GP107、GP108 等六个芯片。
其中 GP100 是面向超算为主,只存在于 NVIDIA 的 Tesla 产品线里,余下的其余 GP 系列 GPU 都能在 GeForce 游戏产品相中找到对应的型号,例如 GeForce Titan Xp 是足本的 GP102;GeForce GTX 1080 采用的是 GP104,面向高端玩家;基于 GP106 的 GeForce GTX 1060 系列面向中端玩家;基于 GP107 的 GeForce GTX 1050 系列面向主流玩家以及游戏笔电。
不过到了 Volta 这一代,NVIDIA 目前为止只做了一枚芯片:GV100。GV100 提供了高性能双精度、多达六条 NVLINK 2.0 通道等游戏卡市场用不上的特性,完全针对超算市场,具体产品目前只有 Tesla V100、Quadro GV100、Titan V、Titan V CEO 四款卡,此外还有以整机服务器提供的 DGX-2。如果说衍生内核的话,倒是有一个针对嵌入式市场的 Tegra Xavier 小芯片集成了 Volta 架构的缩水版。
在 8 月 14 日的 Siggraph 计算机图形学顶级年会上,NVIDIA 正式公布了 Turing 微架构,一并发布的是基于该架构的 Quadro 8000/6000/5000 三款专业显卡,它们都是针对图形工作站或者渲染农场为主的应用。
在不到一周后的德国,NVIDIA 公布了基于 Turing 微架构的游戏卡产品线 GeForce RTX 2080Ti、GeForce RTX 2080 以及 GeForce RTX 2070:

我们都知道,GeForce 这个名称最早是在 NV10 开始启用的,Ge 的含义就是 Geometry 几何的含义,GPU 的说法也是从那时候被 NVIDIA 给出明确定义的:每秒至少能处理 1000 万三角形的图形芯片。
RTX 这个产品名称后续是 Turing 架构首次出现,其中的 R 就是指英文里 ray 即光线或者射线的意思。
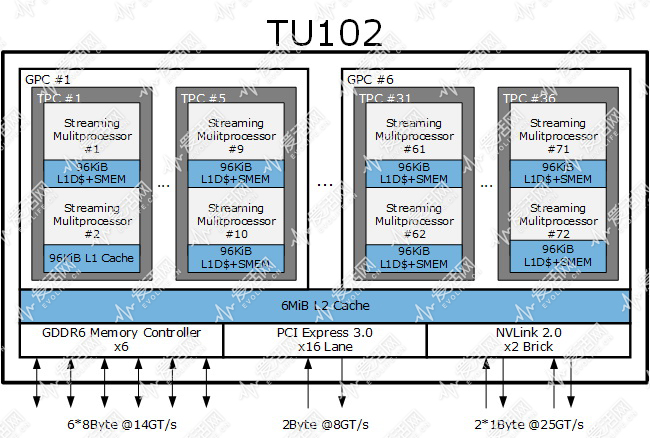
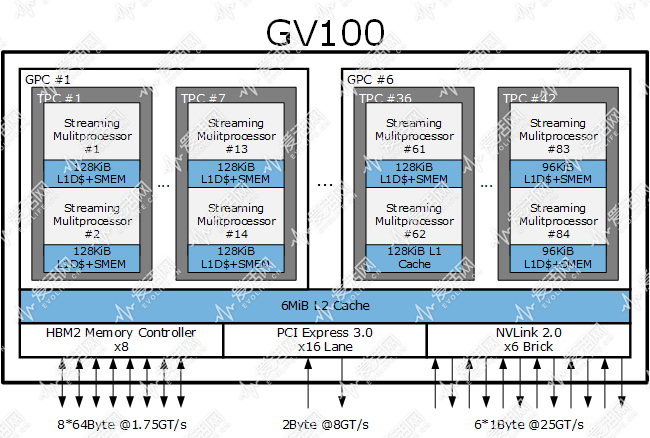
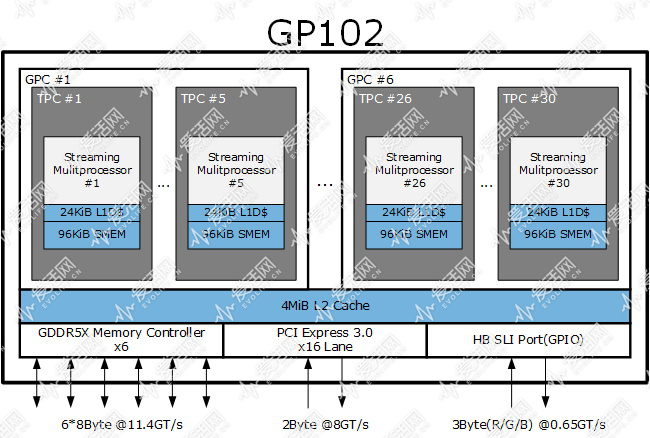
上面三张图是目前图灵架构 TU102、Volta 架构 GV100以及 Pascal 架构 GP102 的架构简图,更多具体的细节我会在稍后给出,这节里我们先从芯片的宏观角度看看。
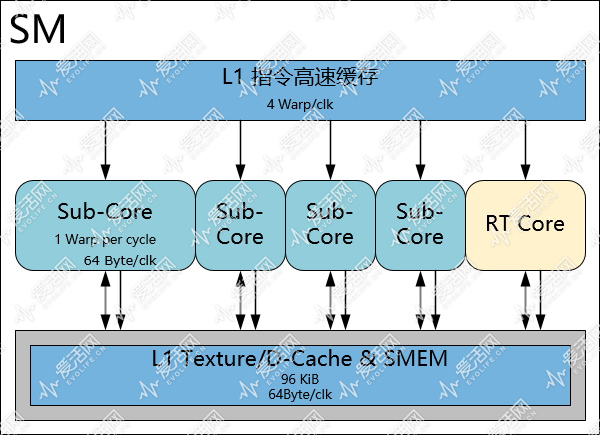
首先,TU102 一共有 6 个 GPC(图形处理簇),每个 GPC 里包含有 6 个 TPC(纹理处理簇),每个 TPC 里有两个 StreamingMultiprocesor(流式多处理器,SM,对应 OpenCL 中的概念就是 CU,Computing Unit),每个 SM 里包括若干个 CUDA Core。
现在的 GPU 都是类似的多层阶式多核设计,而 GPC 的划分基础是它有一个光栅处理引擎。
对于编写 CUDA 通用计算或者说深度学习之类应用的人来说,GPC 甚至 TPC 都是不需要去了解的概念,绝大部分情况下,编程人员需要关注的是 CUDA Core,如果需要进一步优化代码的话,可能还会考虑 SM 层面的东西。
但是对于游戏来说,在传统光栅化渲染的时候,每个 GPC 可以跑一个三角形,因此六个 GPC,意味着在三角形不相依的情况下,TU102 最高可以同时跑六个不同的三角形。这相当于着 TU102 内有 6 个小 GPU。所以从硬件光栅加速渲染的最高层级角度看,TU102 就是一个 6 核处理器,这 6 个内核都需要透过 L2 Cache 完成所有的访存操作。
GPC 使用光栅处理引擎作为划分基础,而 TPC 或者说纹理处理簇“现在”是以 Tesslation 引擎(NVIDIA 称之为 PolyMorph 引擎)为基础划分的,每个 TPC 里都有一个 PolyMorphy 引擎。
每个 TPC 根据架构和 GPU 实现的不同,其中包含的 SM 数也不一样。在 Fermi 之前的 GPU,例如 G80,每个 TPC 里包含有两个 SM,GT200 包含有三个 SM。这些 Fermi 之前的 GPU 只是以几何控制器和 SM 控制器为基础划分 TPC 的。
而在 Fermi 出来后的一段时间里,TPC 以 PolyMorph 引擎划分,几何控制器则部分下沉到 SM 里。由于NVIDIA 在 Fermi 到 Maxwell 这段期间的微架构,TPC 只包含一个 SM,TPC 和 SM 在概念上是重叠的。
因此 NVIDIA 基本不再提及 TPC,因为对编程人员来说,TPC 相当于是透明的概念,而 SM 在多阶层线程编写中是一个非常重要的映射单元,所以 SM 的概念必须存在。
在这时候开始, SM 的名字出现了各种变化:SM->SMX(Kepler)->SMM(Maxwell),名字的变化并非没事乱改,而是这些不同的 SM 在控制单元上发生了重大变化。
到了 Pascal 后,TPC 又在架构图中出现,命名的混乱消除了。
去年 GTC 2017 上发布的 Volta 架构和新发布的 Turing 架构里,TPC 中包含的 SM 数量增加到了两个。
通常来说,在同一个层阶里容纳更多的下级单元规模,一般是为了提升该层级的吞吐量。
对于 Volta 来说,节省的晶体管用在了双精度和张量内核,而对于图灵来说,节省的晶体管就用在了光线追踪和张量内核。
其中,两个新架构都集成了张量内核,说明 NVIDIA 认为不管是超算、游戏或者工作站领域,人工智能加速已经是不可或缺的东西。
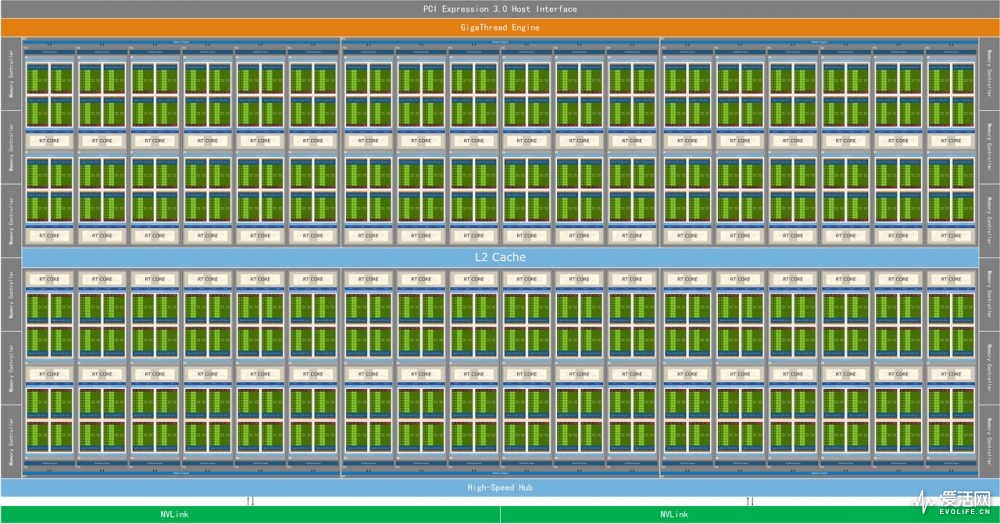
TU102 芯片物理上一共有 72 个 SM,但是目前的 GeForce RTX 2080 Ti 只有 68 个 SM,这意味着 2080 Ti 里有 4 个 SM 或者说两个 TPC 被屏蔽了。
单论单精度浮点性能的话,GeForce RTX 2080 Ti 和 GeForce GTX 1080 Ti 差别不是很大,前者也就是比后者快大约 10%,但是如果你看看纹理性能、内存带宽等指标,都可以发现,前者具备比后者快得多的局部性能,而它们在目前的游戏性能影响还是着举足轻重的。
在制造工艺方面,Volta 和 Turing 都采用台积电 12 纳米线宽制程(12FFN,N 表示专为 NVIDIA 定制)生产,这个制程属于 16 纳米工艺节点。

上面分别是 TU102 和 GP102 的管芯图,图片已经按照尺寸比例进行了缩放。大家可以看到,TU102 的管芯面积达到了 754mm^2,长宽分别大概是 30.7mm 和 24.6mm,比全画幅相机的传感器只是略小一点,不过 NVIDIA 目前最大的芯片依然是数月前发布的 GV100,GV100 的管芯面积是 815mm^2(晶体管数量 21B)。
如果按照晶体管密度来看的话,TU102 密度其实要比 GP102 低,这可能是因为 TU102 的逻辑电路比例更多导致的。
虽然晶体管密度降低了,但是可能因为 12nm 制程以及 GDDR6 内存更省电的缘故,官方给出的 GeForce RTX 2080 Ti 全卡耗电和 GeForce GTX 1080i 保持在一个水平上,都是 250 瓦特,需要配合怎样的电源以及进行散热管理才是用户真正关心的。
前面说过,Turing 基本承继自 Volta,主要是强调了游戏性能,下面就让我们来看在具体的架构细节上 Turing 是长成什么样子吧。
首先,我们来看看 SM 部分。
完整的 TU102 有 72 个 SM,GeForce RTX 2080 Ti 是 68 个,目前只有 Quadro RTX 8000/6000 是具备完整 72 个 SM 配置的。
如果说从光栅图形渲染的角度看,一个 GPC 是一个小 GPU,那么在通用编程中一个 SM 就相当于一个硬件内核,可以同时跑一个或者多个宽度为 32 的 SIMT 指令(NVIDIA 称之为 Warp)。
在最初的 NVIDIA 微架构 Tesla 中,每个 SM 有 8 个 CUDA core(CUDA Core 在 OpenCL 称作 PE),一个 Warp 指令或者说 Warp 线程中包含有 32 个 CUDA thread(Open CL 称作 work-item),因此 Tesla 的 SM 需要花 4 个周期才能完成一个 Warp。
从 Tesla 的下一代架构 Fermi 开始,SM 中出现了两个调度器和两个指令分发器,每个调度器/指令分发器下对应有 16 个 CUDA Core,因此 Fermi 的 SM 可以一个周期跑完一个 Warp。
到了 Maxwell 后,NVIDIA 为 SM 引入了 Sub-Core(子核,又被称作 Processing Block 处理块)的概念,每个 SM 依然具备共享的 L1 Cache 和 SharedMemory(或者说 SMEM),但是内部的资源被划分为 4 个各含 32 个 CUDA Core 的子核,这些子核每个都有自己的调度器和指令缓存,NVIDIA 对 Maxwell 的 SM 命名为 SMM。
Turing 和 Volta 的 SM 基本沿用了 SMM 的基本框架,其中也是有 4 个子核,SM 内的每个子核可以每个周期执行来自同一个 Warp 的指令:
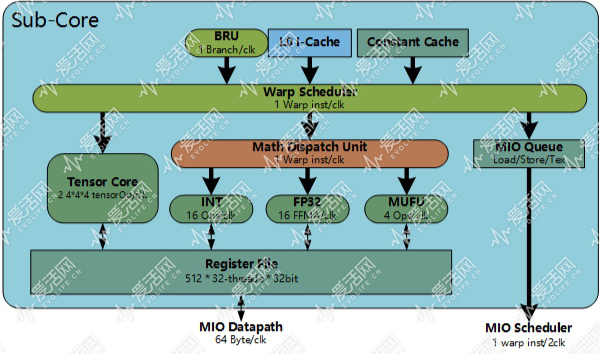
和 GP102 不同的是,如上图所示,TU102 的 SM 中每个 Sub-Core 都引入了两个 Tensor Core(张量内核),这些 Tensor Core(张量内核)可以每个周期跑 64 个混合精度张量操作,因此 TU104 的每个 SM 集成了 8 个 Tensor Core(张量内核),可以每个周期跑 1024 个混合精度张量操作。
Tensor Core(张量内核) 是 Volta 或者说 GV100 才首次引入到 GPU 的,它的作用是加速人工智能运算。
人工智能是当下最热门的科技前沿学科,像自动驾驶、动态捕捉合成、改头换面等等,都是现在大家耳熟能详的应用。
在游戏领域,NVIDIA 已经有了若干项能结合人工智能加速的应用,例如光线追踪去噪、深度学习超取样抗失真混淆等等,随着人们进一步的研究,必定会有游戏与人工智能结合的应用场景产生。
在整数运算方面,Turing 也和 Volta 一样,将整数运算单元拥有自己专门的指令发射端口,浮点运算和整数运算可以并行执行。
按照 NVIDIA 提供的资料,现在的游戏着色器程序,每 100 条浮点指令,就会伴随有平均 36 条整数流水线指令。很显然,两者并行执行的话,指令吞吐率将得以提升,游戏速度自然也提升了。
Turing 的每个 SM 还集成了两个 FP64 单元(上图中并未画出),和 FP32 单元的比例 1/32,集成 FP64 单元的目的主要是为了确保兼容性。
Turing 的 SM 集成了 96 KiB 大小的 SRAM,这个 SRAM 可以由驱动程序或者开发人员确定分配为 L1 数据缓存和 SharedMemory。SharedMemory 的存在是为了让一个 Thread Block 内的 CUDA Thread 可以共享数据,驱动程序一般可以为其确定最佳的大小,例如 Thread Blcok 内的 CUDA Thread 不需要进行数据交换的话,那么 SharedMemory 可能会被设置为 0KiB,这块 SRAM 就会被配置为 L1 D-Cache,改善随机数据存取性能。
理论上,L1 D-Cache 和 SharedMemory 最好独立分开,但是受制于晶体管和耗电成本,当我们需要尽可能多的实现随机存取加速的时候,在 Maxwell 上曾经采用的独立分开设计可能未必是最佳化的设计。
像 Turing 引入了硬件光线追踪,而光线追踪在遍历场景的时候,很容易发生大量的随机存储,一个可以配置的 L1 D-Cache 也许是一个不错的性能改善方案。
 36
36 39
39
 39
39 36
36






这谁写的,还能不能让人开开心心的看了……
为啥不能开心看啊?
听说这次不怎么样?
教材级
这是英伟达的工程师退休后来爱活当编辑了么?
厉害了
纠个错,第二页最后一张图上面的“每个子核可以每个周期执行一个 Warp 或者说 32 个单精度 FMA 操作”应该是“32 个指令操作才对”吧,没SM只有16FP+16INT,要双周期才能跑一个Warp的fp32 FMA啊
第五页内容自适应着色部分的配图错了吧
感觉超过了anandtech
没看完先mark
666666
爱活网把开箱文写成了航空母舰,这是要上天啊
太可怕了
我不是针对谁,其他站的图灵文相比之下都是。。。。。
火钳刘明
爱活又出了一篇全网模板
炸裂了
ngx有意思
原来rtc和s“m”是一一对应的
原来rtc和sm是一一对应的
终于搞明白了smx tpc smm的区别,赞
我有个问题,以前把Pixel Shader和Vertex Shader合到一起都费牛劲,现在又分开成RT Core和CUDA Core,那不是又效率低了么 ?
因为是简单且”大量”重复的操作,做成硬线后,性能耗电比会高很多呀,你可以把 RT Core 想象成纹理单元之类的东西,更重要的是,raytracing 这个东西以后就是趋势,RT Core 不像着色器那样每个开发人员都有不同的想法,它集成的就是很简单的操作。
vs/ps分离设计也很有效率。rtcore应该打散融入smx,公用寄存器才是最理想的?
原来光追是集成在各sm里的?
Volta是NV竞标美国超算中标之后,专门为橡树岭SUMMIT做的,不用来给消费端很正常吧
文章规格上我有问题,之前我跑GP10x L1跑出来都是16k,哪有宣称的32k/64k?
值得其他媒体小编抄袭
不亚于当年的zen评测
跪着看完了,比学校讲的透
不明觉厉
我操,神作
哇,小纯觉得好厉害
沙发?
神作
重点是光线追踪游戏什么时候可以玩到
9999元的荣光
光学追踪这么厉害的吗?
卧槽,炸裂了