
追光者 NVIDIA GeForce RTX 2080 Ti图灵架构浅析

 登录|注册
登录|注册






微软公司在今年的 GDC (游戏开发者峰会)上公布了 DX12 DXR(DirectX Raytracing)技术,让开发人员可以透过该接口比较方便的实现游戏实时光线追踪渲染开发,至此,光线追踪终于从过去基本只在离线渲染中看到转为实时渲染的可选项了。
和微软的其他 DirectX API 一样,DXR 并没有明确硬件应该如何运作,只是指明了硬件应该具备哪些特性,允许让厂商将函数功能以黑盒子硬件的方式实现,这样的做法让 GPU 厂商有了可以用自己的方式来实现这个功能的可能。当然,具体的一些要求细节可能还是有的,例如输入、输出的要求、限制等,应该都是有保密协议,一般来说都是软件开发人员自己尝试了后才知道:哦,原来有这些限制。

其实早在 2004 年(GeForce 6800 时代)的时候,当时的 NVIDIA 首席科学家还是 David Kirk,他与德国萨尔大学(也有称作萨尔布吕肯大学)的 Philipp Slusallek 教授有过一场关于光线追踪和光栅化渲染的激烈辩论(Philipp 在此之前也曾经在 NVIDIA 公司工作过,所以两人的观点比较能擦出火花)。
当时 ,Slusallek 教授正在做光线追踪的相关研究,甚至做了一个光线追踪加速芯片,提出了实时渲染未来应该选择专用的光线追踪芯片。而 Kirk 除了强调光栅化非常快外,也没有否认光线追踪的好处,但是他特别指出定制硬件无法维持维持庞大的处理器研发费用,每 6-9 个月性能倍增的 GPU 才是实现 Ray Tracing 的正确途径。

在三年后也即是 2007 年,NVIDIA 还真的伴随 G80 发布了采用 Ray Tracing 技术的 D3D 演示程序——Luna,Luna 演示场景中有一个超大的眼球物体使用了 Ray Tracing 技术。
所以,很早之前的 GPU 已经具备了足够的通用性来实现光线追踪了,当然,性能是另一回事。
这次 DXR 也提供了两种执行方式,分别是 Compute-base Path 和 DXR API Path。前者就是在 DXR 框架内的使用 GPU 已有的通用计算单元来跑光线追踪,而后者,就是在具备遵循 DXR 框架的硬件加速电路的 GPU 上执行光线追踪,DXR 中负责判断交给谁来跑的部分被称作 Feedback 层。
例如,对于 Pascal 架构的 GPU,DXR 是完全软件方式执行的,Volta 的情况有些特别,它可以使用 Tensor Core(张量内核) 来实现光线追踪的去噪处理,真正第一款遵循 DXR 硬件加速要求的,也就是新的 Turing,只有它具备 RT Core。
在 Turing 之前,也有一些光线追踪的硬件,例如前面 Philipp Slusallek 教授在 2002 年的时候就搞出了名为 SaarCOR(Saarbrucken’s Coherence Optimized Ray Tracer)的硬件架构,最初是在 FPGA 上实现的,后来也拿到了 IBM Cell 上跑了一下。在SaarCOR 后,萨尔大学在 2005 年还弄出了 RPU,同样是基于 FGPA 实现的。
在 RPU 之后,另一个重要的光线追踪硬件是来自 Caustic Graphics 在 2010 年推出的的 CausticOne,可以在和 CPU、GPU 结合的情况下,用作光线追踪全局光照以及光线相关的加速计算。在同年的 12 月,开发 PowerVR 的 Imagination 公司收购了 Caustic Graphics,推出了集成可以每秒跑 50M 条光线的 RT2 的 RT2500 和 RT2100 光线追踪加速卡。2014 年。
Imagination 发布了名为 PowerVR GR6500 的 GPU,这是全球首枚集成了专用光线追踪硬件加速单元(RTU,Ray Tracing Unit)的 GPU,在 600MHz 的频率下能做到每秒跑 300M 条光线(MRPS,million rays per second),采用 GLSL 为编程语言。
PowerVR GR6500 是一枚 GPU,其中集成了 1 个光线追踪加速单元,而 NVIDIA Turing 架构则是每个 SM 内都集成了一个 RT Core,一个完整的 TU102 一共有 72 个 SM,也就是有 72 个 RT Core。GeForce RTX 2080 Ti 的光线追踪性能号称可以达到 10 GRPS(我们并不清楚 NVIDIA 这个指标是如何衡量的,只知道是在场景中只有一个三角形的情况下的理论值),相当于 PowerVR GR 6500 的 33.3 倍。

那么,既然像 Pascal 用通用计算单元的方式也能跑光线追踪,为什么 Turing 不直接增加通用计算单元来实现更快的光线追踪性能呢?
答案很简单,光线追踪涉及的某些操作非常耗时而且动作重复。
机器最适合做重复的事情,目前发明的机器,主要都是用来干又脏又累又重复的活,对图形渲染来说,就是典型的重复、耗时操作,光线追踪更是如此。
Imagination 介绍 PowerVR GR6500 的时候提到,在 AABB(轴对称包围盒)测试的时候,涉及到 26 条指令,如果将这个操作做成专门的固化电路,面积可以缩小到由通用计算单元来实现的 1/44。
光线追踪可以拆分为三个动作,分别是:
射线的生成
找出射线与场景物体交汇点的求交测试
对交汇点进行着色计算
其中,求交测试或者说第二步是最耗时的操作。
身为电子工程师和计算机科学家的 John Turner Whitted 在 1979 年发表了一篇名为 《An improved illumination model for shaded display》的论文,这是首次在计算机图形引入递归式光线追踪,如今 John Turner Whitted 是 NVIDIA 研究事业部的一员,8 月份的时候还在 NVIDIA 官网发表了一篇使用光线追踪实现全局光照的文章。

按照 Whitted 的说法,对于简单场景来说,75% 的耗时都花费在了光线和场景物体的求交计算上,在更复杂的场景中,这类操作的耗时会高达 95%,
求交计算的耗时与场景中涉及的物体数量直接相关。
怎么理解这句话?
假设你手头一张拼图,拼图有大约 1000000 个毫无规则的图块组成,现在你需要将这些图块复原,那你就是逐个尝试了。
我们人脑虽然具有丰富的想象力,但是其实记忆力一般,1000000 个图块,说不定需要数年时间才能拼完整。
光线追踪也是类似的情况。
场景的三角形存放在内存中,射线从眼球发射到像平面穿过像素后,需要从内存中存放的场景中包含的数以百万计的三角形中查找到可能刚巧被击中的三角形。实际的情况其实更复杂,因为光线追踪碰到的三角形很可能存在折射、反射、阴影等情况,这也就有了次生或者衍生射线(Secondary Ray),次生射线还得继续做求交测试。
所以这样的处理过程相当耗时。
那么,如果拼图出厂的时候,已经预先按照原图中的对象关系将图块打包为若干份(例如拼图里有自行车、汽车、人物,就按照这样的对象,一个大致的对象打包为一份),那拼图的速度也自然能提升。
如果能尽可能地减少求交测试的物体,求交测试的时间自然可以减少,从而提升性能,例如对于复杂的场景减少 50% 的物体,那么性能差不多能提升一倍。
为此,人们又提出了所谓的加速结构(acceleration structure)或者说加速结构体,希望透过某种数据结构实现尽可能快地找出场景中哪些物体可能会被某些射线击中,以及扔掉那些包含有永远不会被射线击中的物体的包围盒。
对于刚刚接触编程的人而言来说,数据结构和算法简直是梦魇般的存在,所以在我们这里不打算对光线追踪的加速架构作深入的分析,只是简单介绍一下,因为这对理解 RT Core 还是有帮助的。
Kay 和 Kajiya 在 1986 提出了使用 BVH(Bounding Volume Hierarchy包围盒层级)的数据结构作为光线追踪加速结构的技术,现在几乎所有的实时光线追踪技术都是采用了 BVH 作为加速结构。
BVH(包围盒层级) 的概念很简单,例如场景中有一辆自行车、一部空的汽车,其中自行车上还有一个骑车人,我们可以把这个自行车、骑车人、汽车都用一个包围框(A)框柱,然后自行车和骑车人也放在一个包围框中(B),汽车也给一个包围框(C)。
此时,我们看到场景中有三个包围框,分别是 A、B、C。其中,B 和 C 是 A 的子集,。
包围框 B 里有两个物体,分别是自行车和骑车人,我们可以继续给两者各一个包围框,分别是 D 和 E 吧。
如此类推,直到我们把这些对象拆成原子~~~噗。
如果这些对象都是用三角形构成并且我们用树状结构来存放这个 BVH 的话,那么这个 BVH 的根就是包围框 A 或者集合 A,而最底层根茎就是三角形了。
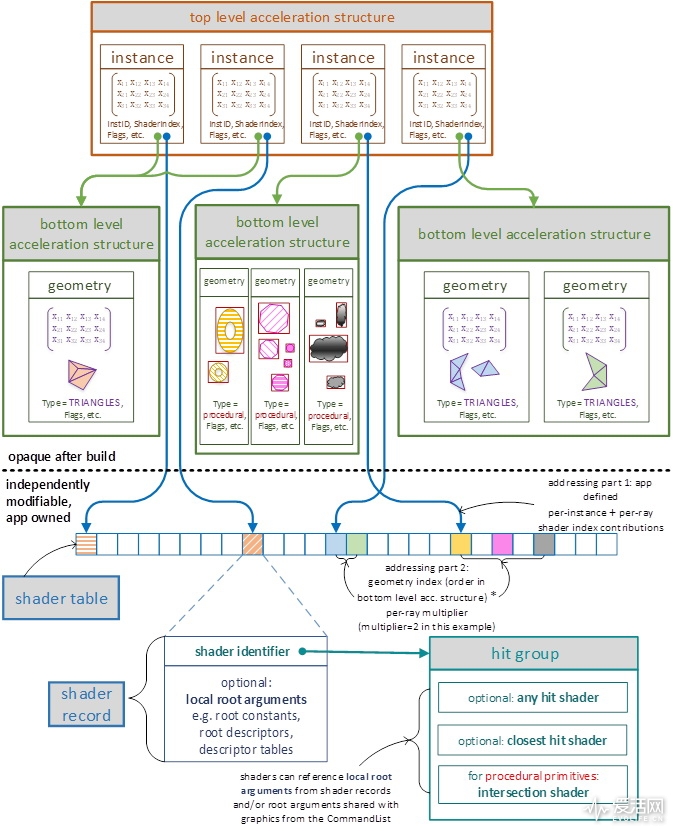
微软 DXR 的加速结构和 BVH 类似,采用了两级的加速结构。
具体的几何体被纳入到 Buttom Level AS(低层加速结构,简称 BLAS)中,在这个基础上,微软引入了名为 Top Level AS(上层加速结构)的数据结构,在这个 TLAS 里,存放有经过一些转换处理的 BLAS 几何体的引用。
如下图所示,蓝色的框框就是 TLAS,红色的就是 BLAS(图片取自 Remedy 今年 GDC 上的幻灯片)。
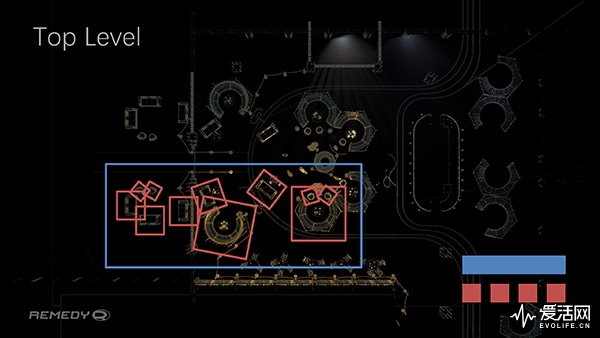
有了 BVH 后,进入场景后的射线首先会尝试看看是否有包围盒被撞上,有的话,那就继续找被撞中包围盒的子包围盒,如此类推,直到撞上最后的三角形。
至此,我们已经了解了,光线追踪最耗时的操作就是射线与场景物体的求交,使用加速结构可以有效减少求交的物体从而提升性能,常见光线追踪加速结构就是 BVH,微软 DXR 的加速结构属于 BVH,而 NVIDIA 的 Turing 微架构正是将三角形和 BVH 的求交测试遍历算法集成到了 RT Core 中。
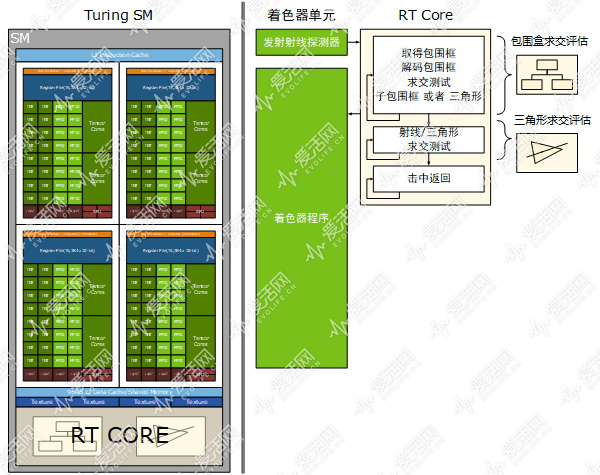
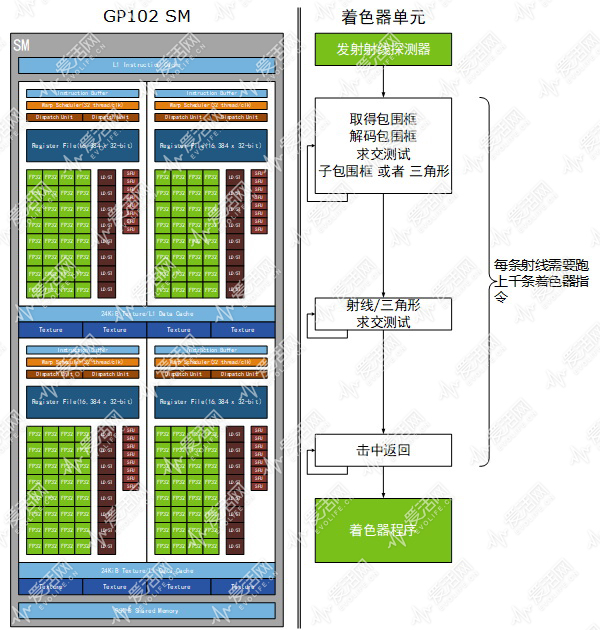
在没有 RT Core 的 GPU 上,BVH 的遍历需要使用着色器单元来执行,每次使用光线投射对 BVH 中包围盒执行求交测试直到最后撞上三角形确定交汇点(确定交汇点才可以知道应该给射线穿越的像素“画”什么颜色上去),需要跑上千条指令。

EA 下属的研究机构 SEED 使用原型版图灵和 Volta(Titan V)进行的光线追踪性能对比分析,测试的项目名为 PICA PICA,项目是开源的。
PICA PICA 最初是在 Volta 上实现的,测试用的版本未经过代码修改,Volta 跑的代码和 Turing 跑的是一样的,未针对 Turing 作专门的优化。
测试结果可以看到,Turing 比 Volta 在 1 个 Primary Ray(主射线,也就是光线追踪从眼球发射到每个像素上的射线)的情况下,阴影和环境遮蔽的性能为 Volta 的 3 倍以上,随着 Primary Ray 的增加,性能的提升效果也越来越明显,在 16 条 Primary Ray 的情况下,Tunring 在阴影、环境遮蔽特效上可以达到 Volta 的 5 倍以上性能。而在大家比较关心的全局光照方面,Turing 达到了 Volta 的 4.8 倍性能。
按照 NVIDIA 的说法,TU102 的 GeForce RTX 2080 Ti 和 GP102 的 GeForce GTX 1080 Ti 纯光线追踪(射线求交)性能分别是 10 GRPS 和 1.1 GRPS,而 GeForce GTX 1080 Ti 的理论单精度性能是 10.6 TFLOPS,换算出来就是 10 TFLOPS/GigaRay,因此可以认为 GrFoece RTX 2080 Ti 的 68 个 RT Core 性能为 110 TFLOPS 左右。
按照之前 NVIDIA 给出的每条射线需要上千条指令才能完成一次完整的求交来看,GeForce RTX 2080 Ti 的 RT Core 部分等效 110 TFLOPS 也是可以对得上的。
如果按照 10 GRPS 来算的话,GeForce RTX 2080 Ti 的每个 RT Core 每个周期大约可以跑 0.1 条射线求交测试,或者说每个周期完成等效 100 条指令的左右浮点计算。

 36
36 39
39
 39
39 36
36






这谁写的,还能不能让人开开心心的看了……
为啥不能开心看啊?
听说这次不怎么样?
教材级
这是英伟达的工程师退休后来爱活当编辑了么?
厉害了
纠个错,第二页最后一张图上面的“每个子核可以每个周期执行一个 Warp 或者说 32 个单精度 FMA 操作”应该是“32 个指令操作才对”吧,没SM只有16FP+16INT,要双周期才能跑一个Warp的fp32 FMA啊
第五页内容自适应着色部分的配图错了吧
感觉超过了anandtech
没看完先mark
666666
爱活网把开箱文写成了航空母舰,这是要上天啊
太可怕了
我不是针对谁,其他站的图灵文相比之下都是。。。。。
火钳刘明
爱活又出了一篇全网模板
炸裂了
ngx有意思
原来rtc和s“m”是一一对应的
原来rtc和sm是一一对应的
终于搞明白了smx tpc smm的区别,赞
我有个问题,以前把Pixel Shader和Vertex Shader合到一起都费牛劲,现在又分开成RT Core和CUDA Core,那不是又效率低了么 ?
因为是简单且”大量”重复的操作,做成硬线后,性能耗电比会高很多呀,你可以把 RT Core 想象成纹理单元之类的东西,更重要的是,raytracing 这个东西以后就是趋势,RT Core 不像着色器那样每个开发人员都有不同的想法,它集成的就是很简单的操作。
vs/ps分离设计也很有效率。rtcore应该打散融入smx,公用寄存器才是最理想的?
原来光追是集成在各sm里的?
Volta是NV竞标美国超算中标之后,专门为橡树岭SUMMIT做的,不用来给消费端很正常吧
文章规格上我有问题,之前我跑GP10x L1跑出来都是16k,哪有宣称的32k/64k?
值得其他媒体小编抄袭
不亚于当年的zen评测
跪着看完了,比学校讲的透
不明觉厉
我操,神作
哇,小纯觉得好厉害
沙发?
神作
重点是光线追踪游戏什么时候可以玩到
9999元的荣光
光学追踪这么厉害的吗?
卧槽,炸裂了