
追光者 NVIDIA GeForce RTX 2080 Ti图灵架构浅析

 登录|注册
登录|注册






前面我们介绍过,2017 年 5 月发布 的 Volta 开始引入了名为 Tensor Core(张量内核)的新单元,这个东西的引入主要是因为当前深度学习如火如荼,大量相关应用被开发出来了,而深度学习有大量计算涉及的数据并不需要很高的精度,因此,许多深度学习加速处理器都采用了混合精度,以追求尽可能高的运算吞吐量,Tensor Core(张量内核)的设计也是基于同样的理念。
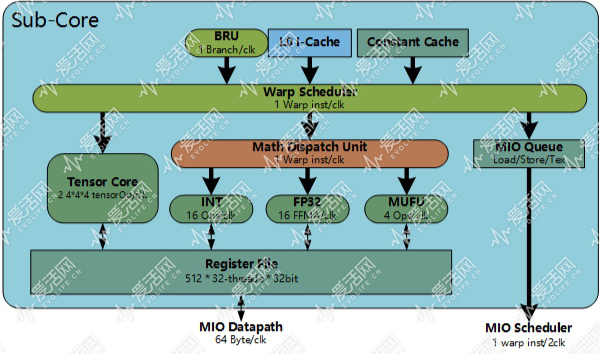
Turing 的 Tensor Core 和 Volta 的 Tensor Core 是不一样的。Volta 的每个 Tensor Core(张量内核) 可以一个周期完成 16 位输入的 4*4*4 个操作,每个 SM 一个周期可以跑 1024 个张量操作,GeForce RTX 2080 Ti 可以每秒跑 107.6T TensorOp。
而 Turing 在这个基础上,还引入了 INT8 和 INT4,INT8 的吞吐是 FP16 的两倍:215.2T TensorOp,INT4 是 430.4T TensorOp。
正如前面介绍 RT Core 提到的那样,凡是机器做的事情,必定是重复、耗时的,Turing 是主要针对游戏市场的架构,引入 Tensor Core(张量内核) 显然不是因为 Turing 晶体管用量嫌太少了随便塞一些充数。
首先,在 Volta 发布一年多后,Tensor Core(张量内核) 目前已经获得了业界的广泛支持,包括 NVCaffe、Caffe2、MXNet、微软 Cognitive Toolkit(CNTK)、PyTorch、TensorFlow 以及 Theano 等目前重要的深度学习框架,只要设定了以 16 位精度存储的话,Tensor Core(张量内核) 就会自动开启(…Torch 这家伙怎么还没支持 Tensor Core 呢)。
然后,NVIDIA 推出了名为 NGX(神经图形加速)的 API,它提供了多个深度学习功能供游戏和应用程序使用,这些功能都是经过 NVIDIA 预训练的。
比较特别的是这个框架要求 GPU 必须是 Turing 起步,连 Volta 都不支持,这是 NGX 因为用到了 Turing Tensor Core 新引入的 INT8、INT4 加速做深度推理加速。
NGX 是透过 GFE(GeForce Experence)和 QXP(Qaudro Experence) 来管理的,当 GFE 或者 QXP 侦测到当前系统有基于 Turing 的 GPU 后,就会下载安装 NXP Core 功能包。
NXP Core 会侦测系统中的游戏和应用程序 ID,将它们关联到 NGX。不同的游戏和应用会使用不同的深度神经网络(DNN)。
NGX DNN 可以和 CUDA 10、DirectX、Vulkan 驱动连接,利用 NVIDIA TensorRT 在深度推理上的低时延、高吞吐优势,提供包括游戏渲染、视频、图片等应用的合成加速。
NGX 中一个和游戏直接相关的功能叫 DLSS,它的名字是深度学习超取样的英文首字母缩写。
NVIDIA 使用自己的超级计算机以极高(64 倍于标准分辨率)的分辨率运行游戏,得出数千张以黄金分方法渲染的画面作为完美渲染品质的参考标准,然后使用 DLSS 神经网络将这些图片和标准分辨率画面对比,让 DLSS 生成一张画面,再次与 64X 超取样画面对比,测量出其和 64x 超取样画面的区别,根据这些差别,透过反向传播算法调整其在神经网络中的权重。

经过多次重复迭代后,DLSS 就知道如何生成尽可能近似于 64X 超取样的画面。一旦人工智能弄清楚后,修改画面的规则就会透过驱动或者配置文件提供,Turing 的 Tensor Core(张量内核) 会运行这些代码,尝试修改画面使其尽可能地近似于 64 倍超取样的效果,而且还能避免使用着色器跑 TAA(时间域抗锯齿)时会产生的模糊、断裂、透明等问题。
DLSS 在玩家端都是先渲染一个“基本”画面,然后由图灵的 Tensor Core(张量内核) 做一个最佳的猜测,尝试为这个画面生成更高品质的画面。
在标准模式或者说高性能 DLSS 下,”4K” DLSS 画面效果可以达到两倍取样 TAA 抗锯齿的水平,而且性能高一倍。标准模式 DLSS 的“基本”画面有可能是用低于最终输出画面分辨率渲染的。
NVIDIA 还提供了 DLSS 的高画质版:DLSS 2X。
在 DLSS 2X 模式下,DLSS 的输入画面是以最终输出分辨率渲染的,然后结合一个比标准 DLSS 更大的神经网络生成达到 64 倍超取样级别的输出画面,这种效果对传统渲染来说是根本不可能实时达成的。
另一个 NGX 提供的功能是 InPainting(画面修复)。
InPainting 可以让程序对现有的图片进行内容清除,然后结合 NGX AI 算法对清除的地方用基于计算机生成的画面进行替换。
例如,InPainting 可以去掉风景照片中的电线,然后使用天空背景实现无缝的替换。
这有点类似于 PhotoShop 中的修补工具,但是修补工具是需要画面中有能用于填补的内容才行,如果没优化好可能产生视觉上明显的平铺模式。

相比之下,NGX InPainting 是依赖于从一大堆真实世界的图像进行训练来填补画面空隙,生成更具视觉意义的图片(见上图)。
此外,NGX 还提供了 AI Slow-Mo 以及 AI Super Rez 两种功能,前者是基于人工智能的慢镜,对现有视频插帧生成平滑无失真的慢镜,后者是基于人工智能生成两倍、四倍、八倍的超分辨率画面,能以实时(大约 30fps)的速度实现 1080p 到 4K 的放大处理,其生成画面的质量(PSNR)要比采用传统双三次滤波高一到两个分贝。
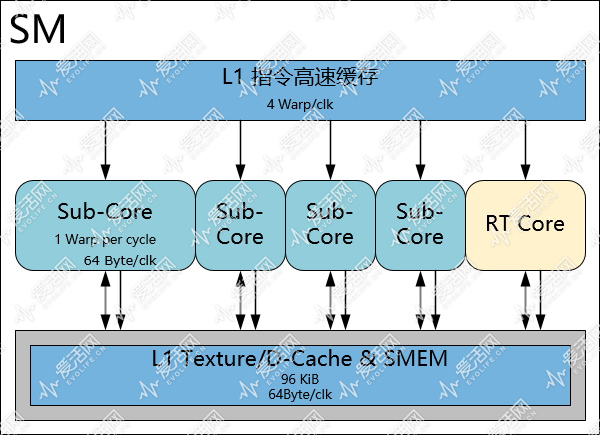
图灵 SM 的内存子系统有 16 个 load/store 单元(LSU),每个 LSU 可以每个周期实现 32 位数据的存取,合共每周期 64 字节的带宽,从这个理论值来看,图灵 SM 的存取带宽要比 Pascal 和 Volta 低 50%。
在图灵架构中,每个 TPC 包含有两个 SM;
而在 GP102 中,每个 TPC 只有一个 SM,因此图灵每个 TPC 的 LSU 数量和 GP102 一样都是 16 个。
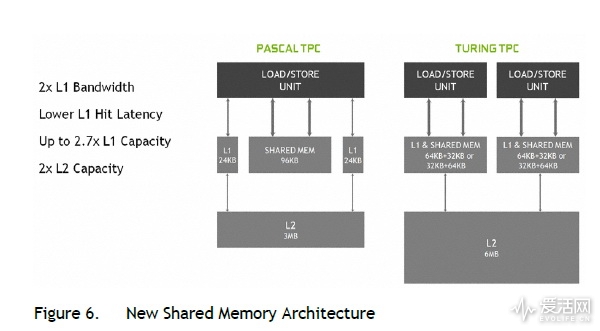
图灵 SM 的 L1 纹理、数据 Cache 和 Sharedmemory 采用一体式可配置结构,L1 和 SMEM 可以共享每个周期 64 字节带宽的 LSU 通道,在 TPC 维度看来,就是每个 TPC 128 字节每周期。
相比之下,GP102 SM(TPC) L1 和 SMEM 是独立的各 64 字节每周期。
因此,从 TPC 的维度看,图灵 TPC 的 L1 Cache 带宽是 GP102 的两倍。
TU104 的 L2 Cache 是 6 MiB,是 GP102 3 MiB 的两倍,带宽也显著增加,更大的 L2 Cache 有助于提高随机存取的命中率,更快的 L2 Cache 能提升运算单元的效率。
完整的 TU102 有 6 个 64 位 DDR6 内存通道,合共 384 位内存总线,速率为 14GT/s,这个速率是 GDDR5X 的 1.27 倍左右。
每个内存通道都和 16 个 ROP(光栅操作处理器)单元绑定在一起,因此完整的 TU102 有 96 个 ROP。
基于 TU102 的 GeForce RTX 2080 Ti 的内存总线是 354 位,缩减了一个内存通道,但是内存带宽依然高达 616 GiB/s,比 GeForce GTX 1080 Ti 高 27.2%。
除了内存带宽提升外,新的 GDDR6 内存也比 GDDR5X 省电 20%。
现在的 NVIDIA GPU 集成了一个内存压缩引擎,根据画面特征侦测结果使用不同的无损压缩算法,降低帧缓存写入压力、减少内存、L2 Cache 以及纹理等用户单元的数据传输量。
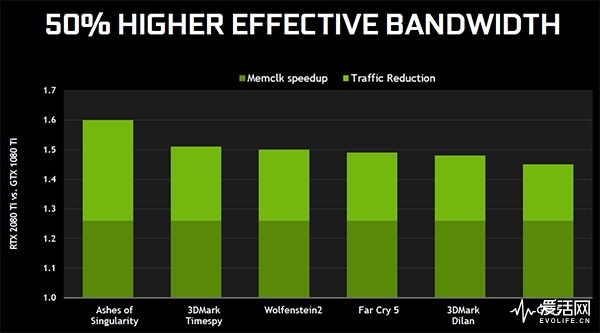
Turing 的内存压缩引擎在 Pascal 的基础上作了进一步改善,能在游戏中达到比 Pascal 高 50% 的有效带宽提升。
 36
36 39
39
 39
39 36
36






这谁写的,还能不能让人开开心心的看了……
为啥不能开心看啊?
听说这次不怎么样?
教材级
这是英伟达的工程师退休后来爱活当编辑了么?
厉害了
纠个错,第二页最后一张图上面的“每个子核可以每个周期执行一个 Warp 或者说 32 个单精度 FMA 操作”应该是“32 个指令操作才对”吧,没SM只有16FP+16INT,要双周期才能跑一个Warp的fp32 FMA啊
第五页内容自适应着色部分的配图错了吧
感觉超过了anandtech
没看完先mark
666666
爱活网把开箱文写成了航空母舰,这是要上天啊
太可怕了
我不是针对谁,其他站的图灵文相比之下都是。。。。。
火钳刘明
爱活又出了一篇全网模板
炸裂了
ngx有意思
原来rtc和s“m”是一一对应的
原来rtc和sm是一一对应的
终于搞明白了smx tpc smm的区别,赞
我有个问题,以前把Pixel Shader和Vertex Shader合到一起都费牛劲,现在又分开成RT Core和CUDA Core,那不是又效率低了么 ?
因为是简单且”大量”重复的操作,做成硬线后,性能耗电比会高很多呀,你可以把 RT Core 想象成纹理单元之类的东西,更重要的是,raytracing 这个东西以后就是趋势,RT Core 不像着色器那样每个开发人员都有不同的想法,它集成的就是很简单的操作。
vs/ps分离设计也很有效率。rtcore应该打散融入smx,公用寄存器才是最理想的?
原来光追是集成在各sm里的?
Volta是NV竞标美国超算中标之后,专门为橡树岭SUMMIT做的,不用来给消费端很正常吧
文章规格上我有问题,之前我跑GP10x L1跑出来都是16k,哪有宣称的32k/64k?
值得其他媒体小编抄袭
不亚于当年的zen评测
跪着看完了,比学校讲的透
不明觉厉
我操,神作
哇,小纯觉得好厉害
沙发?
神作
重点是光线追踪游戏什么时候可以玩到
9999元的荣光
光学追踪这么厉害的吗?
卧槽,炸裂了