
追光者 NVIDIA GeForce RTX 2080 Ti图灵架构浅析

 登录|注册
登录|注册






Turing 引入的 RT Core 和 Tensor Core(张量内核) 能用于实时光线追踪和人工智能画面增强,软件方面的配合也接踵而至,微软将会在 10 月份发布的 Windows 10 2018 10 月更新(Windows 10 RS5)将集成 DirectX Ray Tracing(DXR)以 Windows ML(ML 表示机器学习)。
软硬结合后,可以实现一个全新的混合渲染模型,在这个模型里,可以结合传统的光栅化渲染、新的光线追踪以及人工智能,以实时的方式生成令玩家惊讶的画面。
要了解混合渲染的可用操作需要对相关的工作负载有所了解。光线追踪和 AI 需要非常高的吞吐量,但是不可能整个时间片都用来跑光线追踪和 AI。所以,单纯将这些操作换算成着色操作数并非有意义的衡量指标。首先,我们需要了解每一个工作负载消耗多少时间。
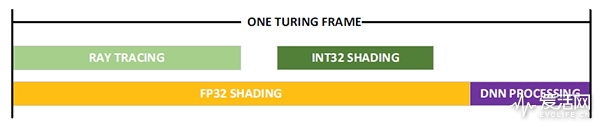
上图是 NVIDIA 根据在 Turing 上运行的应用程序录得的实测数据,阐释了在一帧时间上的工作负载分布,具体而言:
使用 DLSS 为代表的 DNN 工作负载(紫色),耗时占比大约 20%,余下的 80% 都是渲染(黄色)。
渲染耗时中的一部分时间是跑光线追踪的(绿色),虽然有些时间消耗在传统的光栅化或者 G-Buffer 评估上。耗时是根据渲染内容而有所变化的。NVIDIA 根据自己运行的游戏和演示程序评估,认为将时间片以 50/50 分开是合理的。所以在上图中,光线追踪的耗时大约是 FP32 着色耗时的 50%。在 Pascal 中,光线追踪是在 CUDA Core 上以软件方式运行的,每 GigaRay 需要大约 10TFLOP 性能,而在 Turing 这边,光线追踪是在专门的 RT Core 上运行,其性能达到 10GRPS,或者说光线追踪的浮点性能高达 100TFLOPS。
对 Turing 需要考虑的第三个因素是,在 Turing 上整数是可以和 FP32 浮点数并行执行的。NVIDIA 认为现在的游戏中,平均每 100 条 FP32 指令就有 35 条额外的指令运行于整数流水线上。对于单流水线架构来说,这些整数指令是需要在 CUDA Core 单元上跑的,但在图灵架构上,两者可以并行执行。所以,在上面这个时间片中,可以认为整数指令占了着色时间片的 35%。
NVIDIA 根据上面的研究,决定把上述四个底层测试结果综合为一个指标 RTX-OPS,用来反映混合渲染模型下的性能,其计算方式如下。
Tensor Core(FP16):20%
CUDA Core(FP32):80%
RT Core(RTOPS):40%(80% 的一半)
INT32:28%(80% 的 35%)
RTX-OPS = TENSOR * 20% + FP32 * 80% + RTOPS * 40% + INT32 * 28%
用 GeForce RTX 2080 Ti 来套这个公式就是:
RTX-OPS = 114 * 20% + 14 * 80% + 100 * 40% + 14 * 28% = 78 RTX-OPS

图灵最大的亮点是引入了 RT Core,这是桌面级 GPU 首次引入光线追踪加速专用单元,在过去人们为此奋斗了数十年,海量的研究以及半导体工艺的进步终于促成了此事,它既是人们久久期盼的,同时也是不期而至的。
光线追踪能在复杂物体上实现正确的物理渲染,开发人员不再需要为了椅子和地面阴影的正确连接而煞费苦心,玩家可以玩上有三维游戏以来画面品质飞跃最大的游戏。其实光是 RT Core 我觉得就可以点赞 1 万次。

另一个值得大力点赞的地方是 Tensor Core(张量内核)。我一直好奇人工智能在游戏渲染中到底能带来怎样的变化,集成了 Tensor Core(张量内核) 的 Turing 给我们带来了让人惊喜的答案:DLSS。DLSS 本质上是一种程序分析化抗锯齿技术,但是结合了海量的大数据后,其威力甚至可以做到实时达到 64x 超取样的画面品质,顿时觉得什么 MSAA、TAA、FXAA 简直弱爆了。
Turing 也不是没有让人诟病的地方,但是我翻来覆去后,觉得也就是价格相对以前的新品来说的确有点高了,但是我们要知道,目前市场上,只有这玩意提供了最强大的画质、性能,毫无竞争对手可言。在这里,我们望 NVIDIA 能将赚到的钱多投入到与游戏、软件开发上,将纸面的规格变成真正可用的特性。









 36
36 39
39
 39
39 36
36







这谁写的,还能不能让人开开心心的看了……
为啥不能开心看啊?
听说这次不怎么样?
教材级
这是英伟达的工程师退休后来爱活当编辑了么?
厉害了
纠个错,第二页最后一张图上面的“每个子核可以每个周期执行一个 Warp 或者说 32 个单精度 FMA 操作”应该是“32 个指令操作才对”吧,没SM只有16FP+16INT,要双周期才能跑一个Warp的fp32 FMA啊
第五页内容自适应着色部分的配图错了吧
感觉超过了anandtech
没看完先mark
666666
爱活网把开箱文写成了航空母舰,这是要上天啊
太可怕了
我不是针对谁,其他站的图灵文相比之下都是。。。。。
火钳刘明
爱活又出了一篇全网模板
炸裂了
ngx有意思
原来rtc和s“m”是一一对应的
原来rtc和sm是一一对应的
终于搞明白了smx tpc smm的区别,赞
我有个问题,以前把Pixel Shader和Vertex Shader合到一起都费牛劲,现在又分开成RT Core和CUDA Core,那不是又效率低了么 ?
因为是简单且”大量”重复的操作,做成硬线后,性能耗电比会高很多呀,你可以把 RT Core 想象成纹理单元之类的东西,更重要的是,raytracing 这个东西以后就是趋势,RT Core 不像着色器那样每个开发人员都有不同的想法,它集成的就是很简单的操作。
vs/ps分离设计也很有效率。rtcore应该打散融入smx,公用寄存器才是最理想的?
原来光追是集成在各sm里的?
Volta是NV竞标美国超算中标之后,专门为橡树岭SUMMIT做的,不用来给消费端很正常吧
文章规格上我有问题,之前我跑GP10x L1跑出来都是16k,哪有宣称的32k/64k?
值得其他媒体小编抄袭
不亚于当年的zen评测
跪着看完了,比学校讲的透
不明觉厉
我操,神作
哇,小纯觉得好厉害
沙发?
神作
重点是光线追踪游戏什么时候可以玩到
9999元的荣光
光学追踪这么厉害的吗?
卧槽,炸裂了