
AMD锐龙第三代处理器+ROG C8H首测:寻根Zen 2性能本源

 登录|注册
登录|注册






在当年 Ryzen 发布会的时候,AMD 已经向媒体公布了 Zen 的接替者 Zen+、Zen2 等后续微架构,和初代的 Zen 或者说 Zen 1 相比,Zen+ 在微架构上的改动非常小。
目前所知的,Zen + 的改进主要是 CPU 的二级高速缓存时延从 17 个周期缩短为 12 个周期以及提升了预拾取,其他的就是靠制程提升频率以及在内存控制器上改进实现更快内存的支持,IPC(每周期指令性能)的提升只有大约 3%。
相当于 Zen+ 而言,Zen 2 是 Zen 的真正微架构改版,在流水线的前后端都有大幅度的修改,涵盖了高速缓存、分支预测、新指令支持、执行端口和内部总线的扩充以及外部总线的升级。
按照 AMD 的说法,相对第一代的 Zen 而言,Zen 2 IPC 提升可以达到 15%,作为一个改进型的微架构,这样的幅度在摩尔定律日益失效的今天而言,是非常可观的。
接下来的内容可能会有些枯燥、晦涩,但是如果你能静下心来看的话,还是会比较有趣的,因为我们将探究 Zen 2 这个微架构到底在哪些地方做了改进,而它们又将对哪方面产生影响。
说到这,我觉得需要说明一下,所谓的微架构,是指指令集的逻辑实现,例如功能组织、逻辑设计,一般由架构师来进行这个工作,架构师将研发人员提供各种功能模块摆在面前,然后考虑到各种(成本、功耗、可用性)妥协的情况下,将它们依据合理的规格组织在一起。
对于我们这些局外人来说,微架构就是一张张的微架构图,而 Zen1 和 Zen 2 的微架构是长这样的:
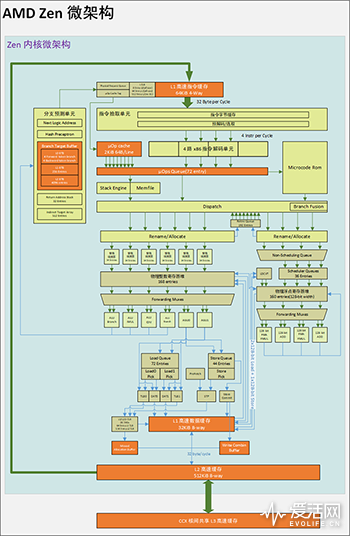
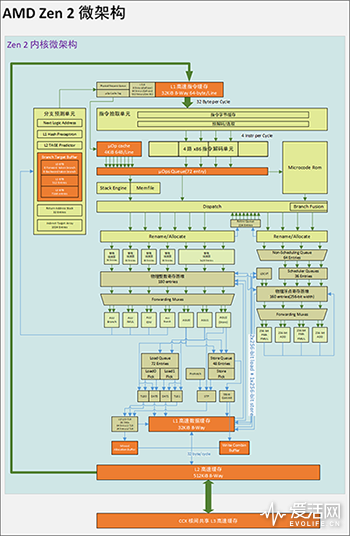
我们都知道,Zen 采用了 CCX 内核复合体的多层次多核技术,每个 CCX 内有 4 个上图中的 Zen 内核,四个 Zen 内核之间透过一块 CCX 内的三级高速缓冲实现数据同步、共享,而 CCX 之间的数据同步和共享必须透过名为 IF 的系统总线跑到主内存上进行。
因此,程序和操作系统必须确保相尽可能都在一个 CCX 内进行数据交换才能达到性能最佳化,当然,这个问题其实在 Intel 的一些 Xeno MP 上也是存在的。
我们下面讨论的主要集中在 CCX 内部或者说 Zen 2 内核的微架构情况,因为这才是 Zen 2 真正实现更高 IPC 的所在。
Zen 2 微内核和 Zen/Zen+ 都同属一个家族,但是在细节上有很多不一样的地方:
1、制程:Zen 2 采用了 CPU 内核和北桥片上分离的设计,CPU 内核采用台积电 7 纳米制程(Zen+ 是 12 纳米),服务器版(EPYC Rome)的北桥采用格罗方德 14 纳米,桌面版(Ryzen 3000)的北桥是台积电 12 纳米。
2、内核:
前端:
改进了分支预测器;
改进了预取器;
改进了微操作标签;
改进了微操作高速缓冲;
更大的微操作高速缓存(从 2K ops 到 4K ops);
增大了派发带宽;
后端:
更大的回退(retire)带宽;
浮点单元:
数据通道提升至两倍宽(从 128 位增加到 256位);
两倍执行单元(FMA 指令宽度从之前 128 位增加到 256 位);
位宽加倍的 Load/Store(加载/存储)单元(从之前的两个 128 位 L/S 两个 256 位);
整数单元:
寄存器堆从 168 个增加到 180 个;
增加了一个 AGU(地址生成单元),使 AGU 数量增加到 3 个;
更大的调度器(从 4 个 14 ALU 条目 + 两个 14 AGU 条目增加到 4 个16 ALU 条目 + 1 个28 AGU 条目);
更大的指令重排序缓存(I-ROB,从 192 个提升到 224 个);
内存子系统:
一级高速指令缓存从 64KiB 缩小到 32 KiB;
一级高速指令缓存从 4 路组关联提升到 8 路组关联;
二级数据地址转译缓存(DTLB)容量提升到 1.33 倍,达到 2048 个条目(Zen/Zen+ 是 1536 个条目);
存储队列从 44 个增加到 48 个;
3、CCX:
三级高速缓存从 8MiB 提升到 16MiB;
三级高速缓存时延性能下降,从 35 周期增加到 40 个周期;
4、安全性:
硬件级抵御幽灵攻击;
密钥/虚拟机的支持数量增加;
5、I/O:
PCIE 4.0;
Infinity Fabric 二代:
每通道传输率提升到 2.3 倍(10.6 GT/s -> 25.6 GT/s);
内存时钟 MCLK 与 IF 时钟 FCLK脱耦,可以实现 2:1 和 1:1 的倍频率;
支持 DDR4-3200(之前是 DDR4-2933)。
7、指令集:
CLWB:对修改过的高速缓存块(Cache Block 或者说 Cache Line)进行回写操作,同时可以将该高速缓存块保留在高速缓存层次结构中。
WBNOINVD:将内部高速缓存所有修改过的存储块写回到主内存中,但是不将高速缓存标记为无效(也就是不刷新)。
RDPID:读取处理器 ID。
从列表来看,Zen 2 的变化是几乎全方位的,前后端、内存子系统、总线系统以及指令集,都为这个微架构注入了新的魔法,其中的三条新增指令对性能的影响不会很大,FMA4 指令也未被重启,所以我们更多的是关注 Zen 2 微架构的前后端部分。
Zen 的微架构在很多方面都和 Intel 的 Core 系列 CPU 非常类似,例如微操作高速缓冲(μops-Cache,Intel 也称之为 Decoed Stream Buffer 或者 DSB,AMD 对微操作的简称是 OC,而 Intel 对其简称是 UC)。
Zen1/Zen+ 的微操作高速缓存大小都是最高 2K 指令,如果按照 AMD 的软件指南,提到微操作高速缓存的大小是 2KiB(第 2.1 节,p18)。
这个 2KiB 的说法似乎是有点让人感到疑惑的,因为解码后的指令或者说微操作都是固定长度的,而微操作的长度不可能只有 1 个字节(8 位)。
相比之下,Intel 的 Coffee Lake(CFL,2017 年第三季发布,就是现在的 9000/8000 系列)微操作高速缓存大小是最高 1.5K 指令,一般认为 Intel 的微操作长度大约是 3 个字节左右。
微操作高速缓存里放的都是循环程序中已经解码过的指令,这些已经解码过的指令称作微操作。
采用微操作高速缓存这样的好处是在可以简化解码器设计的同时维持尽可能高的指令并行度。
要知道 x86 作为一种复杂指令集,其指令长度不是固定的(1 到 17 个字节),所以像 Intel 的多路 x86 解码器都是采取一个复杂解码器搭配几个简单解码器的方式。
在微操作高速缓存发挥作用的时候,标准的指令拾取和解码处理会被绕过。按照当年 Intel 提供的数字,微操作高速缓存的平均命中率可以达到 80%,这意味着在 80% 的时间里,x86 解码器的耗电都可以节省掉。
Zen 的微操作高速缓存带宽最高可以做到每个周期 8 条指令,相比之下,Zen 的传统取指和解码器只能做到每周期 4 指令。
Zen 2 的微操作高速缓存大小增加到了 4K 指令,两倍于上一代,这意味着可以提高微操作高速缓存的命中率,改善循环的性能。
不过作为代价,Zen 2 的一级指令高速缓存被减半位 32KiB,作为补偿,一级指令高速缓存的组相联从之前的 4 路或者说 4 组提升到了 8 路,作用是提高一级指令高速缓存的命中率。
相对于微操作高速缓存,Zen 2 在分支预测上的改进带来的性能提升可能更大。
现在的处理器都采用了超流水线和超标量设计,流水线上有多个工位负责不同的工作,例如取指、解码、执行、写回以及为了提升频率而加进去的驱动工位,每个内核内都有多条这样的流水线。
以 Zen 1 为例,它的整数流水线长度大约是 17~19 级工位(17 是微操作高速缓存命中后的情况),如果放在以前的话,这算是很深的流水线了(当年被诟病流水线深度太长的 Pentium 4 大约是 22 级或者 31 级工位)。
更长的流水线好处是缩短每个指令的处理时间,便于实现更高的频率,但是为了让流水线保持满载,必须找出可以在流水线中重叠的不相依指令流,只有这样才能实现指令并行。
例如流水线中存在条件跳转指令的时候,由于相依性不确定的缘故,处理器必须等待其通过执行工位后,才能让下一条指令进入取指工位。
下图所示的,就是经典的四级工位流水线(取指、解码、执行、写回)在遇到分支时遭遇到的流水线工位停摆动画示例(垂直方向是流水线工位状态,水平方向是时间周期):
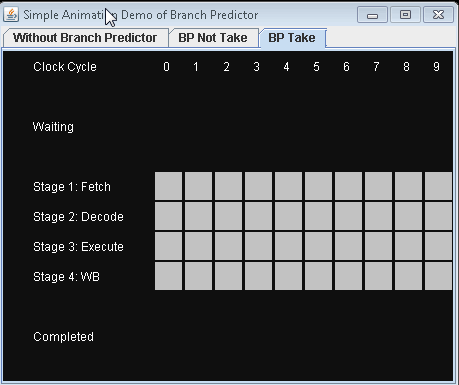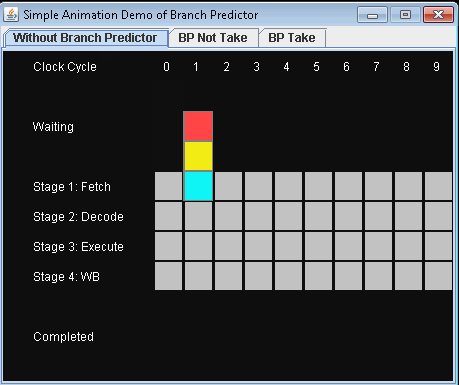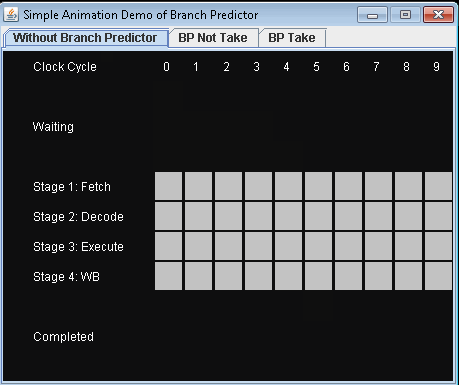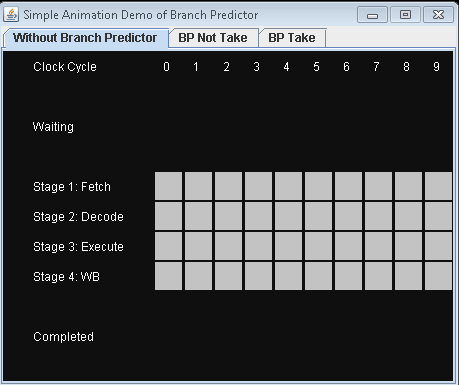
动图来源:https://github.com/Eugene-Mark/BranchPredictorDemo
如上图所示,这是一条可以每个周期执行一条指令(1 IPC)的四级工位流水线,当出现条件分支指令的时候,第一条指令和第二条指令之间的流水线停摆周期会达到两个周期,相当于损耗了 50% 的性能,流水线中出现停摆工位的情况,有时候被称作“气泡”,这里就是有两个气泡。
为了降低分支导致的性能损失问题,人们提出了预测分支行为的技术,而在处理器中实现这个功能的单元就是分支预测器(Branch Predictor)。
依然以上面的四级工位流水线为例,看看有了分支预测器后,条件分支不被选中的情况:

可以看到,流水线保持着充盈运作状态,3 条指令用了七个周期来完成,而之前是需要 9 个周期,第一条指令和后续指令是紧挨着运行的。
不过分支预测也不是每次都准的,像静态分支预测也就是 80% 的命中率,即使如此 20% 的预测失败率对性能也是有巨大影响的,因此人们又提供了动态分支预测,例如 2-bit 状态机,就是使用单个分支的最近行为来预测该分支的未来行为。
由于流水线工位越来越多(越来越长),分支预测失败造成的性能影响与日俱增,因此动态分支预测器的开发一直是微架构比较重大的研发课题,但是这方面进展其实比较慢。
时至今日,人们还在为最后的 3% 成功率拼尽全力,因为现在想要提高 1% 的命中率往往意味得在前人的基础上再减少 30% 的误预测率,这是一个巨大的挑战。
Intel 公司最近发表了一篇名为《Branch Prediction Is Not A Solved Problem: Measurements, Opportunities, and Future Directions》的论文,开篇就提到:
“For example, we show that correcting the mispredictions made by the state-ofthe-art TAGE-SC-L branch predictor on SPECint 2017 would improve IPC by margins similar to an advance in process technology node.”
大意就是,在 SPECint 2017 这个业界认可的基准测试中,采用最新式的 TAGE-SC-L 分支预测器达成的误预测纠正能力,可以达到的每周期性能提升幅度相当于提前使用了下一代节点制程。
Intel 就是这么认为的,并且很可能已经在其处理器中采用了类似于 TAGE 的概念,相关的论文也表明,Intel 在 TAGE 有一定的参与度。
TAGE 预测器的全称是 TAgged GEometric history length branch predictor,直译过来就是标记几何历史长度分支预测器,由两级分支预测器组成。一个是常见的基本预测器,用于提供默认的预测,另一个其实一组标记预测器,提供一个只符合一个标记的预测结果。
TAGE 分支预测器及其衍生的设计自从 2006 年的 CBP-2(第二届分支预测冠军赛)以来,一直都位居冠军榜单上,从未丢过桂冠,其优势就是成本效益比,在 06 年推出的时候,就凭借同样的芯片面积预算,以显著的优势击败了 04 年 CBP-1 里出现的所有分支预测器。
分支预测器很重要,而 TAGE 分支预测器是目前最好的分支预测器,如今 Zen 2 也引入了这个最好的分支预测器。
Zen 1 的分支预测器沿用自针对低功耗处理器 Jaguar 的分支预测器,AMD 对其命名为神经网络感知分支预测器,不过 Jaguar 的流水线深度只有 14 级,Zen 是 17-19 级流水线深度。按理说流水线越深,分支预测失败的惩罚就越高,因此对分支预测器的性能就越高,事实上除了流水线深度外,Zen 2 的超标量能力也是远高于 Jaguar 的,这会进一步增大分子惩罚的幅度,故此神经网络感知分支预测器对 Zen 来说是有点拖后腿的。
为此,AMD 在 Zen 2 上采用了两级分支预测机制,原来的神经网络感知预测器依然保留作为一级分支预测器,而 TAGE 则被引入作为二级分支预测器。
我们在上面啰嗦了一大堆东西,到底在实际应用中会有多少的性能变化呢?我们在这里使用 Fritz Chess benchmark 也就是大家众所熟知的国际象棋来做一个对比。
国际象棋是一个有密集分支指令的应用,当初我使用这个测试软件的,目的是为了对比流水线 31 级的 Pentium 4 和流水线 12 级的 AMD Athlon X2 5000+(K8 系列 Windsor 微架构,90 纳米制程)的,下面这个图表可以让大家回忆一下当初这两个产品的性能对比:

Pentium 4 家族使用的甚深流水线设计使其分支预测失败导致的性能损耗远高于 K8,在 Fritz Chess Benchmark 中,这个问题会被显著放大,上面的测试结果表明这是一个比较适合用于测试分支预测损失的测试。
为了确定流水线深度的影响,我觉得有必要看看 Zen 2 的流水线深度到底是多少级的。
AMD 和 Intel 没有公布过新近处理器的流水线深度,不过我们可以透过测试分支预测失败的惩罚来获知。

上表中的左侧是以伪代码方式提供分支程序测试片段,以第 7 个测试(Test 6)为例:
Test 6, N= 1, 8 br, MOVZX XOR ; if (c & mask) { REP-N(c^=v[c-256]) } REP-2(c^=v[c-260])
这段内容包含了一个 MOVZX 内存载入操作指令,它需要额外的 5 到 6 个周期来执行,在支持乱序执行、乱序 L/S 的处理器中,这个动作通常会被掩盖掉。
从上图中可以看到,这个 Test 6 的 Zen 2/Zen 1 测试结果分别是 12.22/12.30 个周期,加上 MOVZX 的 5 个周期,那这个测试的 Zen 2/Zen 1 有效结果就是 17 个周期。
从测试结果来看,Zen 2 的分支预测惩罚都在 17-19 个周期左右,Zen 1 则是 17-21 个周期左右,Coffee Lake 和 Kaby Lake 都是 16-20 个周期左右。我们认为 Zen 2 在流水线长度上和 Zen 1 都是类似的,即 19 级工位(stage),由于微操作高速缓存的原因,有时候可以视作等效 17 级工位。
Zen 2 和 Coffee Lake 的流水线深度也非常接近,也就是一个工位的差别,因此,只要我们测试的时候,两者的频率尽量设置到一致(锁定 4GHz,减少频率波动干扰,内核数设定为一个,关闭硬件多线程),运行 Fritz Chess 的结果就可以高度反应两者的动态分支预测性能差别。
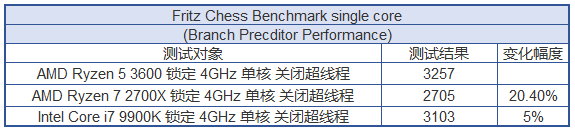 高速缓存正如你所看到的,采用了 TAGE 分支预测器的 Zen 2 在同频下的 Fritz Chess 性能快了 20% 以上,和 Core i7 9900K 相比,也快了 5% 左右,回想上一次 AMD 在这个测试中领先 Intel,一晃已经过去了 12 年。
高速缓存正如你所看到的,采用了 TAGE 分支预测器的 Zen 2 在同频下的 Fritz Chess 性能快了 20% 以上,和 Core i7 9900K 相比,也快了 5% 左右,回想上一次 AMD 在这个测试中领先 Intel,一晃已经过去了 12 年。
TAGE 分支预测器对 Zen 2 的性能提升毋容置疑,但是另一方面,所有的处理器都非常依赖高速缓存。
所有的处理器都采用了多层次内存子系统,而靠近内核的则是高速缓存,Zen 2 和 Zen 1 一样采用了三级高速缓存设计(微操作高速缓存如果算是零级的话,那可以算是有四级高速缓存),每个 Zen 内核都有自己独立的 L1/L2 高速缓存,CCX 内的四个内核透过 L3 高速缓存共享、交换数据。
首先让我们来看看带宽部分:



我们的内核微架构测试,都是在 BIOS 内设置单内核、关闭多线程,关闭电源管理,强制 4GHz,内存设置为 DDR4-3200 的情况下测试,目的尽量直接探究每个内核的微架构细节。
说明一下的是,由于受到 Excel 的限制,横坐标的数字格式不支持二进制(如果你有办法实现的话不妨留言告知),你在图表看到的横坐标值都是十进制值,所以单位标注都是 KB、MB 这类十进制单位,而非二进制的 KiB、MiB,图中的 33KB 标注,相当于 32KiB,34MB 相当于 32MiB,如此类推不一而足。
从测试结果来看,Zen+/Zen 2 这边的 L1/L2/L3 高速缓存读取带宽可以一直保持在每周期 32 字节的水平,而 Coffee Lake 虽然纸面上说 L2 Cache 的 Load 带宽是每周期 64 字节,但是我们并未从测试中看到这样的情况出现。
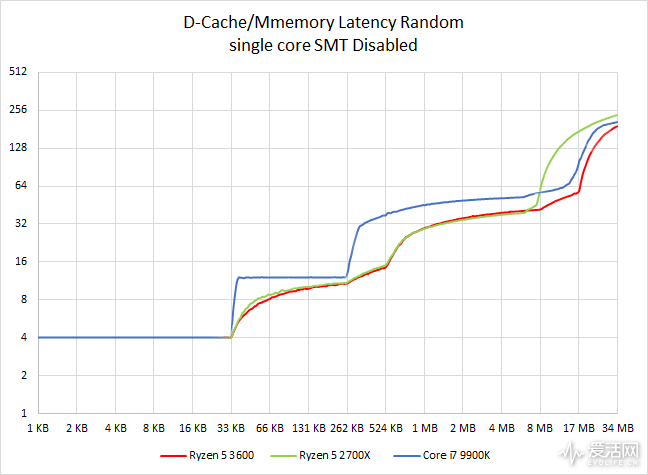
Zen 2 和 Zen+ 数据高速缓存的时延曲线非常类似,不过 Zen 2 由于更大的三级高速高速缓存而在 8-16MiB 的位置有更好的表现。
Coffee Lake 在 32KiB 以内都能保持 4 周期的时延,但是在之后到时延表现都不如 Zen 2。
Zen 系列的 L2 Cache 的时延无法维持在一个稳定的平台,但是可以在 256 KiB 前都维持比对手更低的时延曲线。
众所周知,x86 是复杂指令集架构,但是和精简指令集相比,区别并非什么指令数量的多寡,而是其指令长度格式不一。
以最简单的 NOP 空指令为例,它的 x86 编码长度是一个字节,加法指令 ADD、乘法指令 MUL 等则是两个字节,最长的 x86 指令有 17 个字节。
我们采用了部分有代表性的 x86 指令进行指令解码测试,测算出解码带宽信息(结果受微操作高速缓存、指令高速缓存、解码器、执行单元、回退等工位影响):
正如你所看到的测试结果,Zen2/Zen + 都具备每周执行 5 个单字节指令的能力,而 Coffee 则是只有每周期 4 单字节指令的能力。
Prefixed CMP 其实是针对 x86-64 指令的测试,可以看到,在微操作高速缓存范围内的指令流能够为处理器维持每周期 4 条 8 字节指令的执行能力。
如果单纯从表格来看的话,Zen2 似乎和 Zen+ 一样,但是我们将收集的数据整理为图表后,看到了更多的细节:


我们选取了 NOP 指令(x86 指令长度 1 个字节)以及 Prefixed 的 CMP 4(x86 指令长度 8 个字节)的测试结果做了上面的两个图表。
可以看到 Zen 2 在 NOP 的时候,每周期 5 指令的峰值数据可以维持到 3KiB 以上,而Zen+ 只能维持到大约 0.2KiB 左右。
在长度为 8 字节的指令时,Zen2 每周期两指令的峰值数据可以维持到 16KiB,而 Zen + 只能维持到 8KiB。
从目前的测试结果来看,我们估计 Zen2 的微操作高速缓存容量按照字节衡量的话,应该不低于 16KiB。
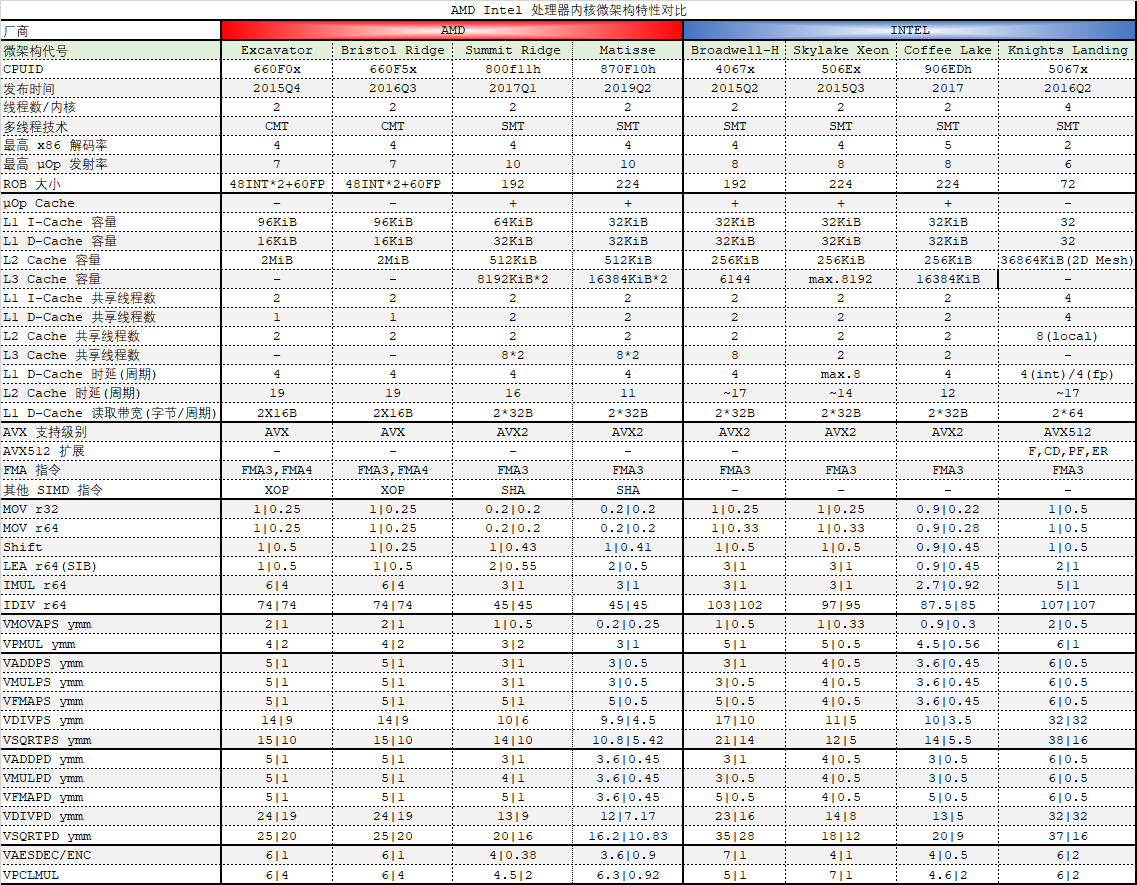
我们使用 AIDA64 v6.00.5122 Beta抓去了 Zen 和 Zen2 的指令时延、吞吐率,其中 Matisse 就是 Zen2 的桌面版内核微架构版本代号。
上表中的 MOV r32 到 VPCLMUL 等指令就是从其中 4000 多条指令测试项目中提取出来的有代表性的测试结果,竖线的两侧分别是时延和吞吐率,单位是周期,因此吞吐率其实是 CPI 值,即周期/指令,是 IPC 的逆向表示方式。
其中涉及到 ymm 寄存器的测试都是 AVX2 256-bit 指令。
从测试结果来看,Zen 2 的 AVX2 ADD/MUL/FMA 等指令的吞吐性能较 Zen 提升了一倍,证明 Zen 2 的确在 AVX2 实现上有做改进。
从微架构角度看,Zen 2 的最大改进是对前端单元的加强,包括引入了目前几乎最强大的动态分支预测器 TAGE 分支预测器作为第二级分支预测,使得 Zen2 可以在分支密集型的应用中比上一代的 Zen+ 快 20%。
即使和 Coffee Lake 相比,同频下的 Zen 2 在分支密集应用中也能快 5%,这是多年未曾出现过的现象,上一次在这类测试中出现 AMD 比 Intel 快的时候是因为比对手短 50% 流水线深实现的。
而这次是双方流水线深度相当的情况下,凭借动态分支预测器实现,对于未来数年 AMD 的竞争前景意义更大,现在的情况就好像两个枪手对决,拔枪速度相当,但是 Zen2 的枪法很可能更准。
Zen 2 的微操作高速缓存达到 4K(微操作),从上面的解码带宽测试来看,我们认为这个改进对于有大量循环的应用会有一定的改进。
由于两个向量单元引入了 256 位 AVX2 指令单周期执行能力,Zen2 在计算吞吐能力比上一代微架构提升了一倍,达到了和 Coffee Lake 相当的水平,x265 这类引入了 AVX2 优化的应用将会受益。
Zen 为 AMD 从颓势中重新找回与对手竞争的信心,Zen+ 为 AMD 取得了市场,而 Zen 2 则是 AMD 让我看到了真正翻身的希望。
这次应该可以至少坚持到 Intel 的 Comet Lake,嗯,时间窗口有半年,能爽半年还是不错的。
 328
328 9
9
 9
9 328
328






顶顶顶一下~~~哈哈哈
现在可以评论了? test
老大 他们都说你这篇文章和youtube评测不符,是A黑文章
膜拜大佬
老哥有没有兴趣来海光指导我们工作????
Pro-A应该是没有兴趣的
膜拜大佬
zen和zen2架构那张图看不清啊。。。
来了,来了,自从上次那篇Zen的评测后又一篇值得好好拜读的文章