
AMD锐龙第三代处理器+ROG C8H首测:寻根Zen 2性能本源

 登录|注册
登录|注册






NB的回归

前面部分是微架构部分,后面就是相对宏观的平台架构部分。
NB是什么意思?就是North Bridge的回归,北桥的回归。年轻的朋友可能不知道北桥是什么?现在一般把PCH叫做南桥,是因为很久以前还有个芯片叫做北桥。上面的965芯片组的华硕P5B-Deluxe,和供电散热片由热管相联的芯片就是北桥。(为什么选这个主板?因为我十几年前我自己用的这个)

上面就是个典型的北桥芯片布局图,CPU通过FSB前端总线连接北桥,而内存和PCI控制器这些高速接口都在北桥里,而南桥主要负责串口,USB、SATA这样的低速设备。此外白桥还有个特征,就是北桥是通过Front Side Bus前端总线和CPU相连,并且之间的连接速率并不是全速,而是和外频成倍数关系。如我之前的Core 2 E6300外频是266,FSB是X4 1066MHz,倍频是7,那处理器频率是266×7=1.86GHz,而我超频可以将外频提升到500,达成500×7=3.5GHz。
Intel这边最后保持完整北桥的芯片组是Core 2的P45/X48这代,之后的X58虽然保持北桥,但其实主要是控制PCIE,而内存控制器已经集成到CPU内部了。而AMD这边则更早,Athlon 64就已经开始在CPU内部集成了内存控制器,北桥主要是连接高速PCIE。
![D7]5{LUKA)C(6HGPZLN7{JE](https://file.evolife.cn/2019/07/D75LUKAC6HGPZLN7JE.png)
而到Sandy bridge的P55这代,内存控制器和PCIE控制器都集成到了CPU内部,全集成相比独立的北桥速度更快,延迟更小,北桥和前端总线似乎就要彻底的离开历史舞台了。
![Q4(GT`L6BACI3$C]BLV(WHM](https://file.evolife.cn/2019/07/Q4GTL6BACI3CBLVWHM.png)
但到了Zen 2,北桥似乎就回归了,内存控制器和PCI控制器和CPU虽然还是在一个基板上,但是分开封装,并且通过异步的总线进行连接。就是说Zen 2又回归到到K8以前传统的架构。

Zen 2的设计将内存控制器,PCIE控制器等部分从核心中拿出,核心/缓存被集中在Chiplet芯片里,而互联部分的IF总线,内存控制器、PCIE/NVME/SATA、时钟生成器和其他IO部分则被放在名为cIOD的芯片里(北桥),其通过Infinty Fabric总线进行连接(FSB)。

再来看看具体的设计。单个核心的封装名为CCD,每个CCD里面有2个CCX,每个CCX里面可以有4个核心,16MB L3缓存。每个CCD同cIOD的连接位宽为32B/周期。cIOD里的Data Fabric到内存控制器的位宽也是32B,这和到核心的位宽一样。
Fabric总线的速度和内存控制器可以同步和异步,在1200-1600MHz范围是同步,如果用户内存是2133MHz,那内存控制器速度就是1066MHz,但Fabric总线还是会保持1200MHz的最低速度,如果在内存在2400-3600MHz范围,Fabric总线的速度和内存控制器同步就是内存速率的一半。内存单通道是8B,双通道就是16B,但由于DDR Double后频率翻翻,但位宽只有Data Fabric到内存控制器的位宽一半,这样带宽刚好保持一致。
![[GQ6BYQI_~5A6PK]9K}CQ8Q](https://file.evolife.cn/2019/07/GQ6BYQI_5A6PK9KCQ8Q.png)
如果内存速度高于3600MHz,那Fabric总线的速度和内存控制器就最高固定在1800MHz。默认设置Fabric总线最高可以运行在1866MHz,如果内存频率高于1866X2,那Fabric总线和内存控制器就是异步模式,内存控制器的速度减半,如4000或者4266,内存控制器频率就是半速的1000/1066,那Fabric总线就会是异步模式,保持1800的频率。
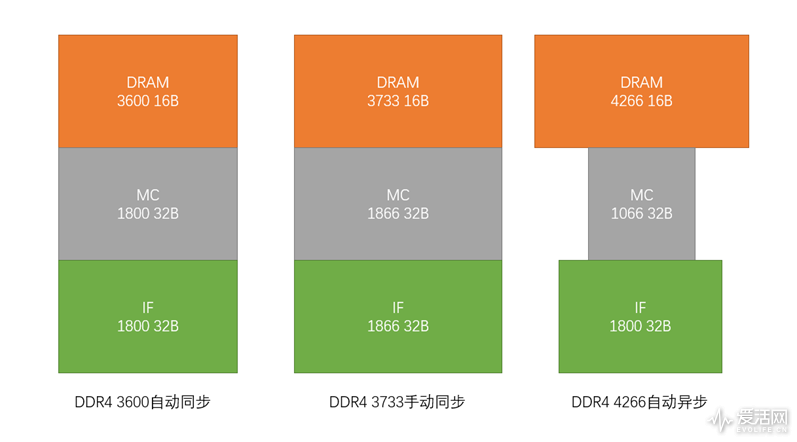
例如内存频率在4266 MHz,16B带宽就是68GB/S,内存控制器的频率是半速,才1066MHz,32B带宽是34GB/S,异步的IF总线是1800MHz,32B带宽是57.6GB/S,明显内存控制器会成为瓶颈。这个时候内存延迟就会反而增加,并进一步影响到带宽(后面会有具体测试)。内存的延迟增加,其实也减轻了内存颗粒的负载,反而使得Zen 2内存比较容易上高频。但这样的高频并没有什么意义,带宽和延迟反而会变差。对于Zen 2而言,3733MHz就是甜点频率,如果可以达到这个频率,就应该考虑的是缩小参降低延迟,综合考虑性价比,AMD官方推荐是3600C16的内存规格。

但更为细致的手工调节,我们可以在同步模式将IF频率拉到1900,内存运行在3800,这个时候内存控制器依然是同步模式。其实更为准确的说,只要是内存频率/2等于IF频率的同步模式,内存控制器依然是全速,因此追求最佳效能,可以同步拉高IF和内存频率。但从现在的情况看,IF可以提高的余地大概只有33MHz,从1866到1900MHz。
![EK(H]EJLN9`272_36V~M)LC](https://file.evolife.cn/2019/07/EKHEJLN9272_36VMLC.png)
我们使用AIDA64 6.0测试不同内存频率的延迟,内存频率高于3733以后,内存延迟就会大幅升高。Zen 2的内存延迟要高于Zen/Zen+,不过这在预料之中,内存控制器在iCOD里,需要通过IF再到MC,路径更长,符合预期。
![Z$B1{J4W9I]@)QPFMBPHHP0](https://file.evolife.cn/2019/07/ZB1J4W9I@QPFMBPHHP0.png)
内存读带宽在3733之前是逐步走高,但超过3733,内存带宽会断崖式下跌,在3733之前实际带宽是理论带宽的87%,而超过3733,带宽效率也大幅下降。
另外一点就是写带宽,对于只有一个CCD的型号,如3600/3600X/3700X/3800X,其写带宽大概只有读带宽一半多一点的水平,而2CCD的3900X/3950X内存写带宽则是正常平衡水平。AMD给出的解释是:
Zen2中执行的区域和性能优化之一是将写入带宽从CCD->IOD从32B/cyc降低到16B/cyc,而读取带宽保持在完全32B/cyc。由于客户机工作负载不需要做很多编写工作,所以不需要指定宽度为32B的链接。这节省了在其他地方进行有用的优化所需的面积和能量。
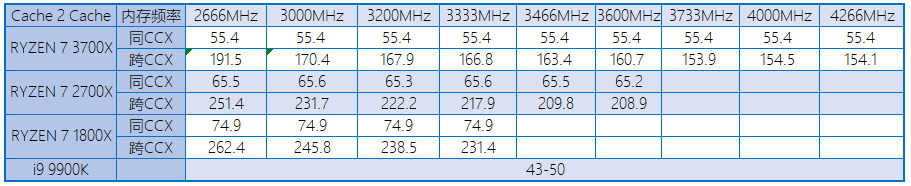
我们依然用Cache 2 Cache测试单CCD的3700X L3一致性耗时,IF频率还是和远端核心L3耗时相关,IF频率越高,远端耗时就越短,内存频率超过3733进入异步模式,耗时还是和IF频率相关,和MC无关。Zen 2的耗时相比Zen和Zen+还是有一定幅度的进步。

现在计算机的接口,本质都是PCIE的各种转接。USB 3.0是,SATA3是,M.2是,DisplayPort也是,TBT3同样是,差别就是占用的带宽和物理定义不一样,但底层都是PCIE。Zen 2的IF频率按1600MHz计算的话,到IO Hub的位宽是64B/周期,这样就是102GB/S的总带宽。PCI-E 3.0 1X的带宽是1GB/S,X570支持PCIE 4.0,那一个Lane就是2GB/S,102GB/S带宽就可以满足50个PCIE 4.0 Lanes的需要,这样就使得Zen 2+X570有人以往HEDT平台才有的扩展性能。

这样大的带宽分配起来就更加自由,以ROG CROSSHAIR VIII HERO (WI-FI)为例,CPU有组直连的16X PCIE 4.0(可以分拆成2个8X),一组直连的4X NVME和4组USB 3.2 Gen2。4X PCIE带宽从ICOD连到南桥,再对各种USB、SATA,WiFi,PCIE 1X 4X的扩展就更为从容不迫了。
在这强大的扩展性能之中,最为关键的就是PCIE 4.0,Zen 2平台配合X570芯片组主板的PCIE 4.0可以提供两倍于PCI 3.0的带宽。目前支持PCIE 4.0的设备主要有两个类别,第一是AMD自家的Radeon 5700显卡,第二类是PCIE接口的SSD。其实现在阶段我个人并不看好PCIE 4.0的应用,主要理由如下:
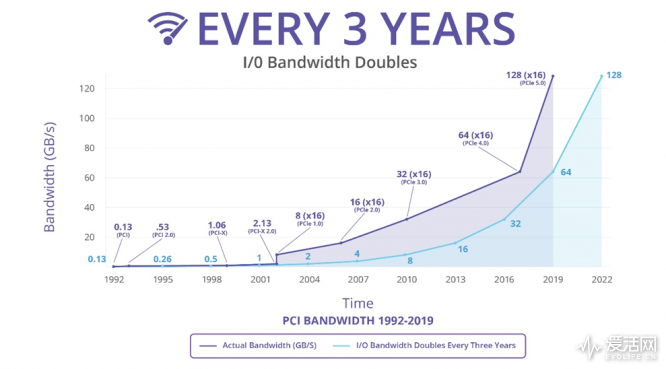
Intel几乎没有计划支持PCIE 4.0(特别是在消费级),而是准备跳过直接在2021年后直接上PCI-E 5.0,并且主要是在服务器领域,而非消费级,AMD方面也只有高端的X570支持,这样使得PCIE 4.0平台在未来一段时间不可能形成足够的市场保有量,下游厂商就会缺乏动力,形成不了生态,PCI-E 4.0虽然是PCIE-SIG的标准接口协议,但在缺乏Intel支持的情况下,依然只是AMD的私有协议;
![~I@CIASGG[)`3[7]JN6XG%U](https://file.evolife.cn/2019/07/I@CIASGG37JN6XGU.png)
显卡方面目前只有AMD 5700系列支持,我们对5700/5700XT的PCIE 3.0和0进行了对比测试:
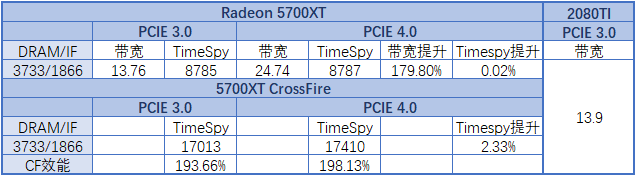
我测试PCIE 3.0到4.0带宽从13.76提升到了24.9,提升幅度基本有81%,这个数据比AMD官方PPT的21.8要高14.2%,估计是我这边IF频率高的关系。但具体性能我们使用3Dmark timespy的图形分进行对比,提升仅仅只有0.6%,这点差距仅仅是误差范围。并且在之前我skylake-X Refresh的测试中,性能更好的RTX2080TI PCIE 3.0 8x相比16x的性能损失微乎其微,现在对于RTX2080TI这样的显卡PCIE 3.0 16X并不是瓶颈,再把带宽翻翻实际上也边际效益也不会明显,更不用说RTX060 Super性能级别的5700XT了。
不过PCIE 4.0对于5700XT CrossFire还是有一定的收益,在双卡情况单卡降低到PCIE 4.0 8X,但这个带宽依然相当于PCIE 3.0 16X。3Dmark图形分PCIE 4.0双卡提升98.13%,大门PCIE 3.0双卡提升93.66%,PCIE 4.0在CF效能下还是有接近5%的优势。‘
![AEF(D_P]WHW1U`IF5ADU~CA](https://file.evolife.cn/2019/07/AEFD_PWHW1UIF5ADUCA.png)
储存方面虽然群联的PS5016-E16主控方案能够支持PCIE 4.0 4X,并且借此可以获得更高的顺序读写性能。但对于SSD而言,顺序性能却不是性能痛点,痛点在于低队列深度 的4K性能。并且目前计划采用PS5016-E16主控方案的都是如技嘉、影驰、威刚,海盗船这样的二三线SSD品牌,一线的如Intel,三星、西数、东芝、镁光均没有推行PCIE 4.0 SSD的计划。
 而且这个PCIE 4.0的价格……
而且这个PCIE 4.0的价格……
![]FYNLSHX@RYELE]KTR6M3DW](https://file.evolife.cn/2019/07/FYNLSHX@RYELEKTR6M3DW.png)
另外再提一下,PCIE 4.0也并不是Zen 2首发,IBM 早在2017年的Power 9就已经支持PCIE 4.0。

不过他主要是用在提升infiniBand互联的带宽,基本可以将带宽从200GB/S翻翻到400GB/S的水平,这对于依靠infiniBand节点互联的HPC可以说意义重大,是立竿见影的刚需,而Volta显卡连接则是用的NVLink。Intel在2020年以后PCIE 5.0首先上在服务器领域也是出于互联带宽方面的考虑。

Zen 2的Chiplet部分是采用的7nm工艺,面积为7.67×10.53=80.76mm2(官方数据为77mm2),是右侧比较小的那个芯片,左边比较大的是IO芯片,采用的是更为老旧的12nm工艺,面积为9.32×13.16=122.65mm2(官方数据是125mm2)。

做Chiplet的意义不在于性能,而在于成本,首先是研发成本,相同设计的芯片可以灵活组合满足不同规模的性能需要,生产上也同样简化。此外更大的影响在良品率,先不考虑CIOD的话,如果做一个包含8个CCX大核心的话,面积大概就需要148mm2(简单化估算),按照上面的经验模型曲线这个面积的单个大芯片大概只有27%的良品率,而做4个CCX的74mm2的小芯片大概是38%的良品率。假设一个晶圆可以切割50个大芯片,100个小芯片,那只有13.5个大芯片可以用,而2个一组的小芯片则有19个可用,相同成本的情况下,2个一组的Chiplet设计可以比单个的大芯片多40%的良品。
上面的情况只是简化的经验数据,实际上Zen 2还有分离的CIOD芯片,这部分对于性能要求更低,可以使用更为便宜的12nm工艺,再切Zen 2采用的7nm是新工艺在高性能领域的首次应用,实际的良品率情况比上面的经验模式更为糟糕,那做Chiplet的意义就更为明显。
![%ELKW0BEVG)UERR_]SSPUUG](https://file.evolife.cn/2019/07/ELKW0BEVGUERR_SSPUUG.png)
再来说说工艺问题,Zen 2是首个采用7nm工艺中央处理器,按照台积电的说法,7nm相比之前的16nm+(Zen+的12nm并不是指真的线宽,而更多是市场宣传的营销手段,只不过是16nm的加强版),功耗仅为60%,性能提升30%,芯片面积缩小70%,那工艺上是不是吊打Intel祖传的14nm++呢?
Zen 2的CCX面积是31mm2,相比Zen+的44mm2小了29%,这还是处理器规模增大,L3缓存翻翻的情况下达成的。2700X的核心面积大概是193mm2。6/8核心的单CCD型号,Chiplet 77+ iCOD的125=202mm2,如果是双CCD的12/16核心型号,那核心面积是。Chiplet 77×2+ iCOD的125=279mm2。9900K的核心面积大概是173mm2,单CCD型号在Chiplet使用7nm没有集成显卡的情况下,面积依然要大于9900K,而更不用说晶体管规模。虽然CIOD的12cm工艺比较便宜,但7nm的Chiplet生产成本应该会很高,因此Zen 2虽然采用了Chiplet这样降低成本的设计,但整体成本依然不低。
我们再来看看AMD和Intel各家对于自己工艺性能的描述:

AMD PPT里7nm的每W是差于Intel 10nm的。AMD在Zen 2评测指南里的具体说法是每W性能相比Zen+增加75%,相比Intel 14FF+的处理器提升58%。。

Intel自己PPT里,虽然首代10nm的工艺的密度更高,但晶体管性能14FF++比首代的7nm更好。我们可以注意AMD一直强调的是性能功耗比,而Intel强调的是绝对性能,这个性能就是上高频的能力。
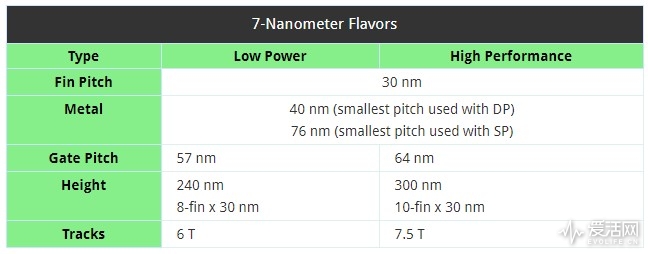
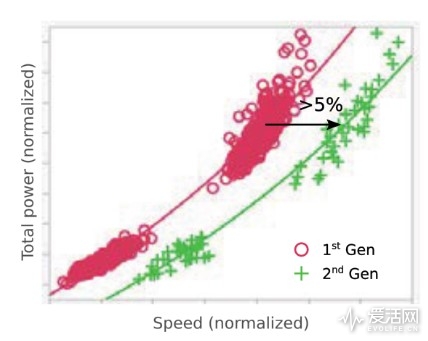
现在的TSMC 7nm只是采用Finfet+SAQP,充其量只能算是过渡工艺,其首先只是为密度和功耗优化,而不是性能,而后面7nm HP才是完全体,虽然晶体管密度有所下降但性能会大幅提升。想想Intel 5775C的14nm和9900K的14FF++的差别,你大概就能明白,虽然同是14nm,但不能同日而语。
 328
328 9
9
 9
9 328
328






{kind=link}
顶顶顶一下~~~哈哈哈
现在可以评论了? test
老大 他们都说你这篇文章和youtube评测不符,是A黑文章
膜拜大佬
老哥有没有兴趣来海光指导我们工作????
Pro-A应该是没有兴趣的
膜拜大佬
zen和zen2架构那张图看不清啊。。。
来了,来了,自从上次那篇Zen的评测后又一篇值得好好拜读的文章