


 9
9 6
6 9
9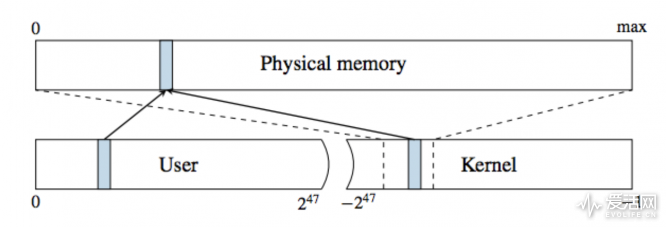



从现在知道的信息来看,应该还是ARM架构,除了ARM也没什么适合移动端的新架构。

 登录|注册
登录|注册






上述 FLUSH+RELOAD 攻击实际上就是这次 Meltdown 和 Spectre 攻击最终环节的组成部分,也是这两个攻击被称为边信道攻击的原因:敏感信息的获取,靠的是检查读取某条 cache line 的时间,这已经是比较典型的边信道攻击了,虽然好像感觉不够神奇。不过在 Meltdown 和 Spectre 的攻击链条中,FLUSH+RELOAD 并非唯一实施方案,还有各种变体,比如 Prime+Probe 也是可行的,这里就不做展开了。但这部分构建了攻击链中的 convert channel,也就是最后获取到敏感数据的一个秘密通道。
因为 ARM 虽然也有擦除 cache line 的指令,但这些指令仅可用于高权限模式,ARM 架构不允许用户进程选择性地擦除 line;对 AMD 处理器攻击也无效,作者推测 AMD 处理器的缓存结构可能是非包含式的,即 L1 的数据不需要存在于 L2 或 L3 中,所以擦除 L3 cache 的某行 line,并不对 L1 构成影响。
在 Spectre 攻击的 paper 中[4],研究人员提到他们不仅采用 FLUSH+RELOAD 攻击方案,另外还融合了 EVICT+RELOAD 方案——这本质上算是前者的一个变体,只不过后者对 line 的擦除方法更复杂,这可能是 Meltdown 和 Spectre 得以在不同处理器平台上实现的一部分原因,有兴趣的同学可以去深挖后一种方案[5]。

就 Meltdown 而言,这种攻击方式主要利用的是当代处理器的乱序执行特性,可以在不需要进行系统提权的情况下,就读取任意内核内存位置,包括敏感数据和密码,甚至拿下整个内核地址空间。不过它对 AMD 和 ARM 的处理器也是无效的,但原因似乎并不像上面这样。研究人员在 paper 中提到[6],Meltdown 在 AMD CPU 上的攻击复现并不成功,但可能只需要对攻击进行一定优化,深入挖掘依然可能会成功,比如对竞争条件进行一些调整,所以 Meldown 攻击或许也并不仅限于 Intel。
“乱序执行”本身不是个生词了,当代的高性能处理器都有乱序执行特性:早些年 CPU 性能每年翻番都并不稀罕,通过增加核心数、时钟频率,加宽管线外加工艺迭代就能实现。但是在顺序执行架构达到瓶颈之后,架构的优化就成为一个重要方向:顺序执行架构中,指令完全按照一个不变的顺序执行,就算 CPU 运算单元的执行速度很快,CPU 却浪费大量时间在等待,许多单元处在闲置状态,所以乱序执行成为提升效率的重要解决方案。好比你攒台 PC,如果显卡还没到货,肯定不会守在门口傻等,而是把其余部分先组装好。
1967 年,Tomasulo 最早开发出了可用于动态规划指令乱序执行的算法,当时他就提出了一个叫 Unified Reservation Station 的东西。CPU 在不需要将某个值存储到寄存器并读取的情况下,就可以在这里使用值。此外,Unified Reservation Station 还通过一个 CDB(共用数据总线)把所有执行单元连接起来。如果某个操作数尚未准备就绪,URS 单元可以监听 CDB,获取里面的数据,然后就可以直接执行指令了。(请注意,这一段对于理解后面的 Meltdown 攻击流程很重要)
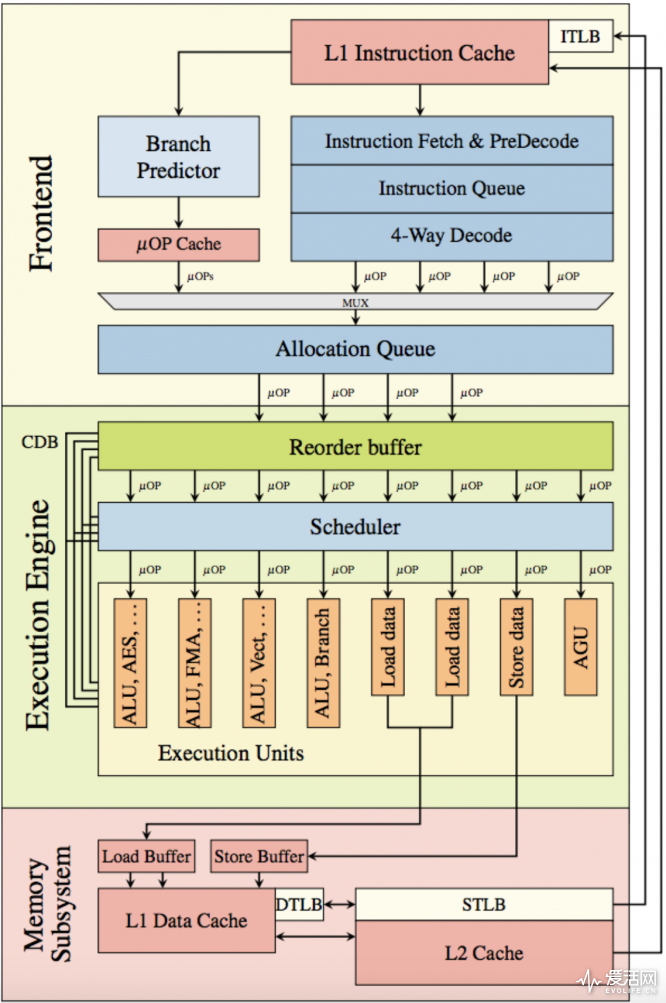
在 Intel 的处理器架构中,其整条管线包含了前端、执行引擎(后端)和存储子系统。前端会从存储系统中(包括 cache 和主内存)读取 x86 指令,随后分解成为 μOP(所谓的“微指令”,有些类似于将 CISC 转为 RISC 的过程),μOP 再发往执行引擎。乱序执行操作就是在执行引擎中发生的,如上图所示。
其中有个 Reorder buffer(重新排序缓冲器),负责寄存器分配、寄存器重命名和 retire。在经过此处之后,μOP 就转发到了上面提到的 Unified Reservation Station,此处对操作进行排序,排队完了就可以发往执行单元了;执行单元就能进行 ALU 加减乘除、AES、AGU 或者载入存储执行之类的操作了。AGU(地址生成单元)以及载入与存储执行单元直接与存储子系统相连,可以直接处理请求。
现在的处理器一般都已经不再直线型执行指令,比如分支预测单元可以猜测接下来该执行什么指令——分支预测器在某个 if then 语句中的条件语句还没有判断之前,就已经开始预测其中的分支运行结果了。在这条线路上,那些没有依赖关系的指令可以先执行,如果预测正确,运算结果就可以马上使用了。如果预测错误,Reorder buffer 清理回滚,并重新初始化 Unified Reservation Station。
选读:有关地址空间(可略过)
为了让进程彼此间隔离,CPU 支持虚拟地址空间,在此虚拟地址会转为物理地址。一个虚拟地址空间会被分成几个 page,这些 page 通过多层级页转换表(multi-level page translation)分别映射到物理内存。这里的转换表,定义了虚拟和物理间的映射转换,另外还定义了用于进行权限检测(可读属性、可写属性、可执行属性、用户可访问属性)的保护属性。现如今的转换表放在某个特定的 CPU 寄存器里面。
在每次进程上下文切换的时候,操作系统都会用另一个进程的转换表地址去更新该寄存器,所以每个进程都有个虚拟地址空间,每个进程只能参照其自有虚拟地址空间的数据。每个虚拟地址空间又切分成用户(User)和内核(Kernel)两部分。运行中的应用可以访问用户地址空间,但内核地址空间仅当 CPU 运行在特权模式下才可以访问。这一步是由操作系统决定的,操作系统在相应的转换表中禁用用户可访问属性即可。
实际上内核地址空间不仅包含内核自己用的部分,也需要在用户 page 执行操作,比如往里面灌数据。因此,整个物理内存在内核中都有映射。在 Linux 和 OS X 系统中,这种映射比较直接,比如整个物理内存直接映射到预定义的虚拟地址;Windows 的情况则比较特殊,Windows 系统维护分页池(paged pool)、非分页池(non-paged pool)以及系统缓存(system cache)。这些“池”就是内核地址空间中的虚拟存储区域,将物理页映射到虚拟地址,其中非分页池要求地址位于内存中,分页池由于已经存储在了磁盘上,所以可以从内存中移除。而系统缓存部分则包含所有文件备份页的映射。
一般的内存破坏漏洞利用,就需要某个数据的地址。为了阻止内存破坏一类攻击,就有了 ASLR 等技术。为了保护内核,KASLR(内核地址空间布局随机化)在启动的时候会对内核地址进行随机化,令攻击难度更大。微软和苹果在Windows 7和Mac OS X 10.8 中引入了kALSR并强制开启。Linux在2017年5 月于4.12 版本中默认开启kALSR。
实施 Meltdown 攻击,要克服 KASLR 就需要获取到这种随机偏移量。但要做到这一点也并不难。

这里我们看一个乱序执行的简单例子。这段代码第一行就产生了异常(不用管是怎么产生异常的),按照控制流来说,发生异常就该跳到操作系统的异常处理程序,应用终止,后面的代码就不会继续执行了。但因为有乱序执行的存在,第三行指令可能已经部分被执行了,只不过没有 retire,所以实际上并不会在架构层面产生可见的影响,即它对寄存器、内存都不会有影响。
这部分执行最终会被丢弃(恢复状态),寄存器和内存的内容也不会执行 commit。但它对微架构层面有影响——这里所谓的微架构也就是 cache 部分了。在乱序执行(第三行指令)过程中,引用的内存读取到寄存器上,也存储到了 cache 里面,即便最终 CPU 发现异常以后清空整条管线,cache 中的内容也依然会保留。这样一来,利用本文第一部分提到的 cache 边信道攻击就可以获知其中的信息了(此处是要提取 data 的值):也就是不停探测某个内存位置是否进入 cache。
完整的 Meltdown 攻击主要分成两个组成部分,第一部分就是让 CPU 执行某个永远不会在路径中被执行的指令,如上例中的第三行代码——我们将这种指令称作 transient instruction。真正要将这种 transient instruction 应用到实践攻击中,就要求指令序列中包含密钥之类的东西——就是攻击者想要窃取的数据。
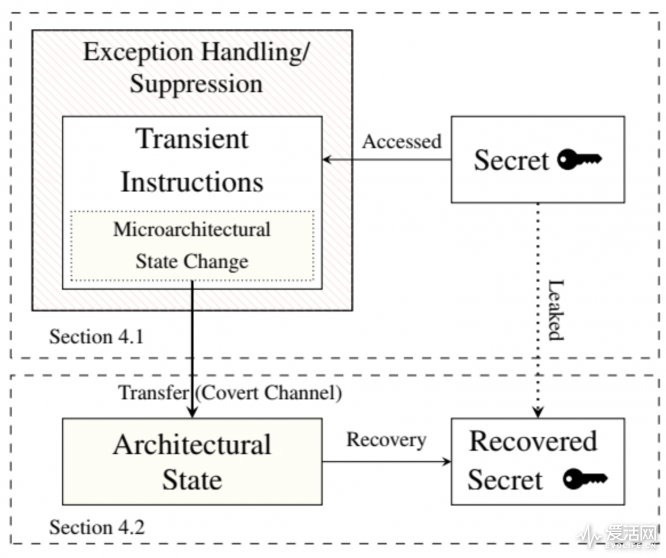
Meltdown 的第二部分主要就是我们这篇文章第一部分提到的那种基于时间的边信道攻击了,把密钥给恢复出来,或者说对 L3 cache 进行攻击获取数据的方法。这样我们基本上已经把 Meltdown 的攻击过程给说清楚了。但实际操作中可能会碰到很多复杂的情况,如攻击者要获取密钥,那么就意味着要访问用户不可访问的 page,比如说内核页——访问这样的位置,由于没有权限,所以会导致异常。攻击者需要去想办法处理这样的异常,否则的话进程就要被终止了。处理方法可以是把攻击程序分成不同部分,只在子进程中执行后面的 transient instruction 序列,而父进程通过后续的边信道攻击来恢复密钥。
另外,在第二部分的边信道攻击,也就是上图中所谓构建 covert channel 秘密通道,悄悄把已经存在于 cache 中的密钥给窃取到了。在这部分里,我们可以把 transient instruction 序列看成是这个通道的发射端,而接收端可以是不同的进程(和第一部分的 transient instruction 可以是无关的),比如可以是前面提到的父进程。

如果你还是不明白,这里举个简单例子:有家餐厅(CPU),这家餐厅有个收银员,还有个厨师(执行引擎)。小明和小红每天都去这家餐厅吃东西,小红(内核)每次点东西的方法都是对收银员说:我要和昨天一样的东西——然后厨师把东西做出来,收银员给小红打包带走。小明很想知道小红吃的究竟是什么,所以他有一天跟在小红身后;小红点完以后,小明跟收银员说:我要和小红一样的东西。收银员说:你这是侵犯人家的隐私,滚出我们餐厅(发生异常)!于是小明就被人收银员一脚踢出了餐厅(管线清空)。
小明想了一个新的办法,第二天他带着小方一起去,他俩跟在小红后面。小红照常点餐(点的是汉堡),小明大声喊:我要和小红点一样的东西。餐厅的厨师听到了,于是就做了两个汉堡出来(执行引擎进行乱序执行,第二个汉堡进入了 cache)。但小明再次因为侵犯隐私,被收银员扔出了餐厅。小方(cache 边信道攻击)这个时候上前了,他和小明是串通一气的,他对收银员说:我要点汉堡、薯条、鸡腿、土豆泥、红豆派、可乐、鸡翅……最终小方发现,最快送上前来的是汉堡(因为在 cache 里面),于是就知道小红点的其实是汉堡。
要发表评论,您必须先登录。



叹为观止!终于有人讲明白这两个漏洞是怎么回事了
典型的理论分析吧。。。
看来amd说自己安全保险也有吹牛的成分在里面
9代应该也是暗藏隐患,毕竟很早就开始设计定型了,也许10代都不一定是重新设计的
nb
炸裂
+1
叹为观止,终于有人讲明白这两个漏洞是怎么回事了
叹为观止,终于有人讲明白这两个漏洞是怎么回事了