


 9
9 6
6 9
9


从现在知道的信息来看,应该还是ARM架构,除了ARM也没什么适合移动端的新架构。

 登录|注册
登录|注册






这里,我们对 Meltdown 再做更为细致的理论探讨。在上文 Meltdown 简介部分的代码中,攻击者通过 probe_array 开辟了一段内存,而且是 256 个 page 大小的内存(乘以 4096 是假设一个 page 为 4KB),而且要保证这部分内存没有 cache 过。接下来我们就彻底地理一理整个逻辑的过程究竟是什么样的:
第一步:读取密钥
从主内存中加载数据到寄存器,引用主内存中的数据需要使用虚拟地址。在将虚拟地址转为物理地址的过程中,CPU 还检查了该虚拟地址的访问权限,用户可访问,还是仅内核可访问。所有内核地址导向有效的物理地址,CPU 也就能够访问这些地址的内容了。当前权限不允许访问某地址,CPU 就会生成异常,用户空间无法简单地读取到这类地址的内容。

不过乱序执行上线了,CPU 会在非法内存访问和产生异常这个很短的时间窗口内,乱序执行后面的指令。在上面的汇编代码中,第 4 行,RCX 寄存器里面有个内核地址,这一行载入了该地址中的字节值(密钥,实际上这个操作是不被允许的,所以理应产生异常);然后把它放到 RAX 寄存器(这也是 x86 架构中的一个 64 位寄存器)的最低有效位上。
如我们前面科普的那样,mov 指令被处理器读取,编码成 μOP,分配后发往 reorder buffer。在这个 buffer 中,RAX 和 RCX 这样的架构级寄存器,会映射到实际上的物理寄存器。
由于乱序执行的存在,代码第 5-7 行也已经解码分配成了 μOP,随后这些 μOP 被发往 unified reservation station(还记得文章前面提到的内容吗?翻回去看看)。如果后面的执行单元此时被占,或者执行指令所需的某个操作数还没准备好,μOP 就会在这里等着。实际上,后面这几行指令的 μOP 可能已经在 unified reservation station 里面等着前面第 4 行的内核地址抵达了。这个时候,如前文所述,由于 unified reservation station 通过共用数据总线监听执行单元,所以这部分 μOP 不需要等第 4 行指令 retire 就可以开始执行运算了!!!是不是感觉乱序执行顿时就高级了?
当 μOP 执行完成之后,他们按照顺序 retire,执行结果会 commit 到架构状态中。在 retire 阶段,CPU 才会处理,前面指令执行过程中产生的异常和中断。这个时候,第 4 行的 mov 指令显然要被毙掉了(因为没权限访问内核地址),异常此时才被处理,整条管线清空,消除乱序执行指令计算的所有结果。
但不要忘记,cache 里面还有后面乱序执行算出来的货呢,这些货没有清掉。

第二步:传输密钥
如果 transient instruction 序列在上面的 mov 指令 retire 之前执行,那么第一步就成功了。这里生成异常(即 mov 指令 retire),和 transient instruction 之间有个竞争状态,就是 transient instruction 必须要先执行,否则异常如果先生成了,后面指令的乱序执行就不会进行——所以攻击中需要减少 transient instruction 序列的运行时间,这才能够提升攻击的成功率。接下来就该是把密钥传出去了。
说穿了,transient instruction 所做的事情就是把前面的密钥放进 cache 里面。那么在传出密钥阶段,攻击者用 probe_array 开辟一部分内存(还记得前面的代码吗?),并且确保这部分内容没有被 cache。在上面汇编代码的第 5 行,是把从第一步中取得的密钥,乘以 page size,假定 page 大小是 4KB(对应于高级语言 access(probe_array[data * 4096]))。
这个乘法是为了保证对数组的访问,相隔距离足够大,阻止处理器的 prefetcher 去预取相邻内存位置。这样的话内存占用 256 x 4096(256 个 page)。代码的第 7 行,是将乘法运算过后的密钥,和 probe array 的地址相加,组成最后 convert channel 的目标地址。这个地址被读取,用以对相应 line 进行 cache。
第三步:接收密钥
这部分其实就是本文的第一部分,Meltdown 攻击描述也基本采用了 FLUSH+RELOAD 攻击方案。上面第二步中提到的 transient instruction 序列执行后,probe array 的一个 line 被 cache。probe array 的 cache line 位置就取决于第一步中读取的密钥。那么攻击者对 probe array 的所有 256 个 page 进行迭代,测量 page 的每个首行 cache line。包含已写入到缓存的 cache line 的那个页数(也就是哪个 cache line 写入时间最短),也就直接表示密钥的值了。
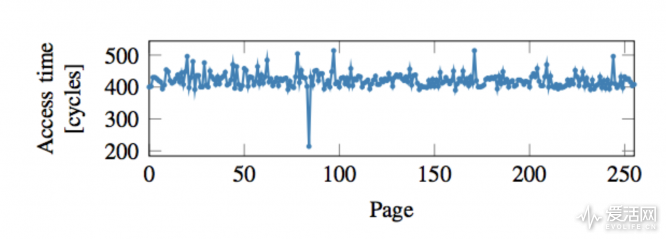
对 256 个 page 进行迭代,观察读取时间,仅有一个 cache 命中,这个命中的 page 就是 data 值啦!
这两部分是不是表示看不懂了?没关系,反正只要搞清楚,恶意进程依靠一些巧妙的算法,试出了这个敏感数据是什么——根据文章第一部分 FLUSH+RELOAD 的思路,再用编程的一些技巧就可以搞定。
通过对前面三个步骤进行重复操作,对所有不同的地址进行迭代,攻击者是可以还原出整个内存样貌的。研究人员利用这套方案,在 Intel 酷睿 i7-6700K 平台,外加 Ubuntu 16.10(Linux 内核 4.80) 操作系统中进行攻击,能够从内存中获取及其向 web 服务器发出请求的 HTTP header。另外,还能获取 Firefox 56 浏览器的内存部分,并找出存储在其内部密码管理器中的密码。
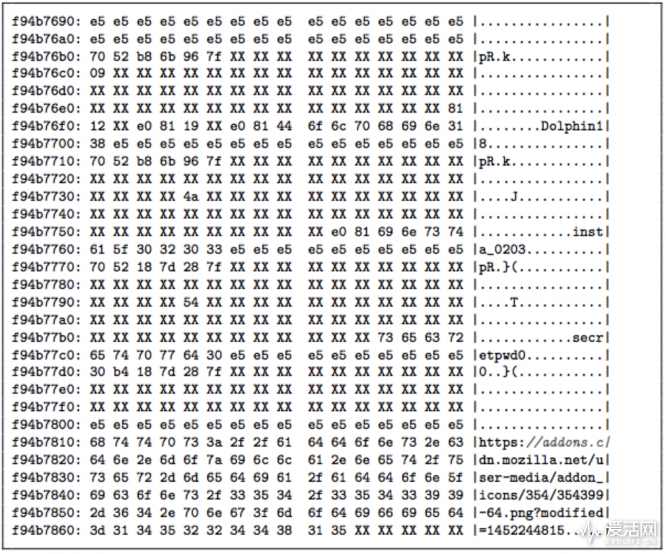
Firefox 56 存储的密码一览无遗啊
Meltdown 的这套攻击方案,利用的是漏洞 CVE-2017-5754。实际上,这种攻击技术的提出并不是近期才有的,去年 7 月份就有人写过一篇警告文《Negative Result: Reading Kernel Memory From User Mode》[10],不过此人当时未能完美复现 Meltdown 造成的问题,但他自己说似乎是“开启了潘多拉魔盒”。
这是个实实在在的硬件级漏洞,属于 CPU 微架构实施层面的漏洞。鉴于硬件产品的特殊性,让 Intel 召回这 20 年的产品是不现实的。不过封堵这种程度的漏洞,最佳方案难道不是禁用乱序执行吗?但这对当代 CPU 性能影响将会是灾难性的。
硬件层面实际上还可以对权限检查和寄存器读取,实施一个序列化过程——如果权限检查失败,则不读取该内存地址。但这么做的代价也会非常大,每次内存读取都要进行权限检查。更加现实的方案应该是从硬件层面实现对用户空间和内核空间的隔离:设立分隔比特位,内核必须位于地址空间上部,用户空间则必须位于地址空间下半部。这样一来,内存读取即便通过虚拟地址都能发现读取目标是否违反安全边界。
要发表评论,您必须先登录。



叹为观止!终于有人讲明白这两个漏洞是怎么回事了
典型的理论分析吧。。。
看来amd说自己安全保险也有吹牛的成分在里面
9代应该也是暗藏隐患,毕竟很早就开始设计定型了,也许10代都不一定是重新设计的
nb
炸裂
+1
叹为观止,终于有人讲明白这两个漏洞是怎么回事了
叹为观止,终于有人讲明白这两个漏洞是怎么回事了