
代差的碾压 AMD Zen 3处理器暨ROG C8DH评测报告

 登录|注册
登录|注册






随着笔记本这边的 Zen2 产品线命名为 Ryzen 4000 系列后,Ryzen 5000 系列也就自然而然的成为了 Zen 3 的产品型号了。
第一波的 Zen 3 主要针对高端产品,它们分别是 Ryzen 7 5800X、Ryzen 9 5900X、Ryzen 9 5900X,此外还有针对中高端的 Ryzen 5 5600X,先放个简单的对比表:
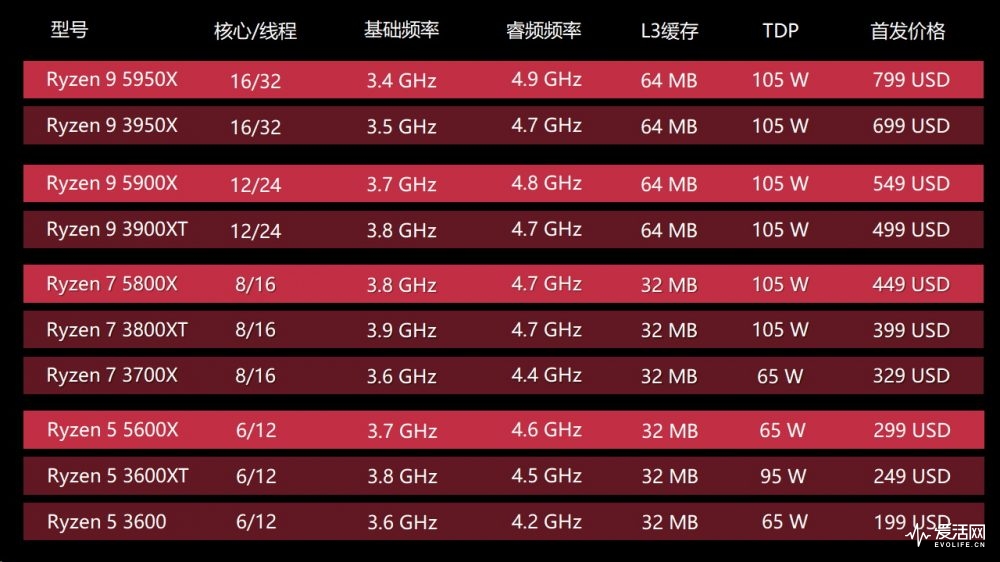
对于 AMD 来说,Ryzen 5000 系列的主要任务与 Intel 的十系列(内核步进代号 CometLake)台式处理器竞争,因此其性能必须达到相当甚至更好的水平。
CometLake 的最高端产品为 Core i9 10900K,微架构可以追溯至 5 年前(2015 年 8 月)的 SkyLake(各编译器里 CometLake 对应的微架构旗标就是 skylake),属于 SkyLake 的第七版步进,Zen 3 面对的就是这个潜力一挖再挖的微架构,最初采用 Skylake 的产品被称作第六代 Core(酷睿),是十系列四代之前的产品了。
SkyLake 微架构发展:SkyLake->KabyLake->CoffeeLake->AmberLake->WhiskeyLake->CoffeeLake 更新->CometLake

而在 Zen 3 这边 AMD 较早之前给开源编译器组织 CNU 和 LLVM 递交了名为 znver3 的编译器开关,其中有若干条新指令。
首先是目前 Intel 并未公开支持的:
INVLPGB – 可以在刷新整个 TLB 的情况下更新指定的 TLB 条目。
TLBSYNC – 这条指令是为了确保逻辑处理器执行了 INVLPGB 指令后,系统中所有逻辑处理器都实现相应的同步。
SNP – SNP 其实由 PSMASH、PVALIDATE、RMPUPDATE、RMPADJUST 四条指令组成。这里涉及到 Reverse Map Table(逆向映射页表)的概念,RMP 是为了方便实现页表回收或者迁移的机制,SNP 的作用就是实现对 RMP 操作的加速。
然后是 Intel 目前已经支持的:
VAES – 向量 AES 指令。
VPCLMULQDQ – 对两个 quadwords 数据进行无进位相乘操作,在 64 位系统中,quadword 的长度是 256 位。这条指令被认为 Intel AVX 512 中同类指令的 256 位版本。
INVPCID – 主要用于避免额外的 TLB 刷新,Intel 在 2010 年代就提供了该指令的支持,它被引起关注主要是因为 2018 年的时候,使用它可以减少 Meltdown 危机导致的性能开销。
OSPKE – 操作系统相关的密钥指令。
其中对性能有影响的主要是前面的 5 条指令,不过目前最新的 GCC 正式版 10.2 并未提供 znver3 旗标,GNU 这边需要到明年正式发布的 GCC 11.0 才会提供,LLVM 则需要 12.0。
换而言之,除非是使用汇编代码,目前的 GCC/Clang 编译器只能使用 znver2 来编译,在 Zen 3 上会有轻微的性能发挥问题,这些零星的新指令算不上重要的扩展。行文至此,AMD 自己的 AOCC 编译器依然停留在 2.2 版(基于 Clang 10 和旧 Flang 的 AMD 官方优化版)。
从 CometLake 可以看出,如果没有什么重要的改动,编译器一般不会去增加微架构旗标,包括 Intel 自己的编译器也都没有为 SkyLake 后的架构改版增加微架构优化旗标。
而到了 AMD Zen 这边,每一代微架构基本上都有一个新的旗标对应,Zen+ 虽然没有直接的旗标,但是根据我在 Ryzen 5 3550H 的实测,它使用 znver2 跑 SPEC CPU 2006/2017 时候的性能也会有一定的性能提升。
改用新的微架构旗标有提升,说明了三件事,一个是微架构有变化,另一个是编译器方面有优化,而处理器旗标的提交都是处理器厂商自己提交的,所以 AMD 软件团队基本上是跟得上节奏的,奈何软件开发的确是一件需要考虑方方面面的事情,所以还需要时间来实现。
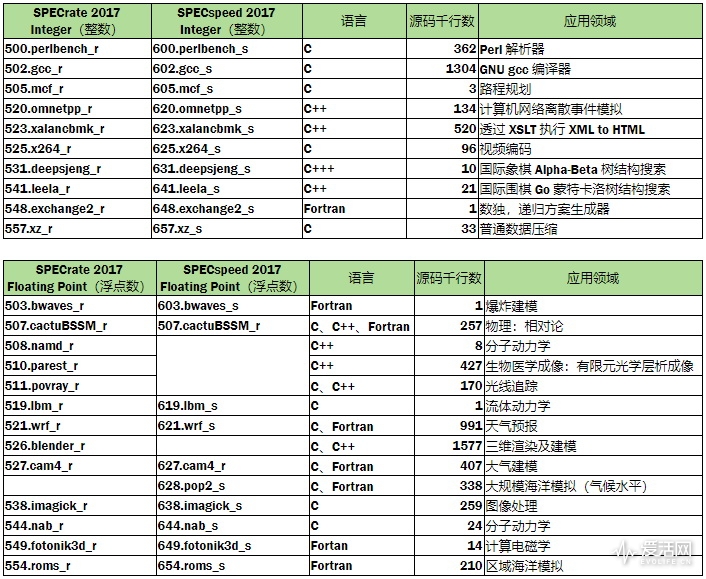
上面两个表格就是 CPU 2017 四组测试集的介绍,5 字头的都是 rate 测试、6 字头的都是 speed 测试,rate 不允许多线程或者自动并行化,但是可以同时跑多个相同实例的方式执行。speed 只有 fpspeed 是全部支持多线程,intspeed 只有 657.xz_s 支持多线程。
657.xz_s 的内存开销是 CPU 2017 单个子测试中名义最高的,根据观察起码需要 16GB 内存,但是实际上 fpspeed 对系统内存的需求更高,32 GB 内存的系统跑 fpspeed 会比 16 GB 内存快上一截。
我这次主要使用 gcc/g++/gfortran 10.2 的 GCC 三套件外加 Jemalloc 内存分配库进行测试,采用 GCC 而不是 ICC、AOCC、LLVM 的原因有三点:
1、GNU 这边有完整的 gfortran 实现,LLVM 那边的 Flang/F18 目前缺乏 codegen,只有语义等环节,AMD 的 AOCC 在页面介绍说是 LLVM 10,但是根据 Flang/F18 开发人员 Kiran Chandramohan 给我的回信,AOCC 的 Flang 其实是基于老 Flang(并入 LLVM 之前)的,所以 LLVM 的工具集并不完整,不适合作为我们的测试使用。GCC 的性能比比 AOCC 更快,。
2、Intel 编译器也是一个不错的选择,根据我的实测,跑起来会两边其实差不多,ICC 浮点会快一点点,整数一样。我们希望尽量公平一点,所以在区别极小的情况下,一律使用 GCC。此外,GCC 有些特性是我觉得很有用的,例如它提供了读取 native 微架构旗标时实际调用了哪些优化开关的功能。
3、GCC 10.2 和当年我初次接触 的 GCC 4 相比已经有非常巨大的进步,不管是代码生成质量还是兼容性、文档和技术支持,都让我可以有把握排除一些测试中遇到的问题,例如 GCC 10 引入了一些优化开关的问题,经过查找文档后我自己解决,而 SPEC 那边也在稍早公布了相应的解决方案。
按照计算机科学的划分,指令集架构(ISA)定义了指令的格式和功能,而微架构(microarchtecture)定义了处理器的内部构成。
微架构一般以流程布局图的形式展现,其中会有各种路径和功能单元,例如高速指令缓存、动态分支预测器、解码器、指令调度器、逻辑计算单元、浮点计算单元、载入/保存单元、高速数据缓存以及系统总线。
现代的微架构中,内核的概念通常是按照存储层次来划分——从寄存器到 L2 Cache 这个级别的单元集成被称作“内核”,芯片中的其余部分(包括 L3 Cache、内存控制器、系统总线)一般称之为 Uncore。这是现代方式的划分,但如果是 i386 这种“远古”时代的处理器按照官方规格连 Cache 都没有集成,需要在主板上安装昂贵的 SRAM 颗粒,这种原始物种的内核相对而言是光溜溜的。
对于微架构的改动,我们先从“内核”谈起,先放看看 AMD官方的 Zen 2和Zen 3 内核微架构对比图:
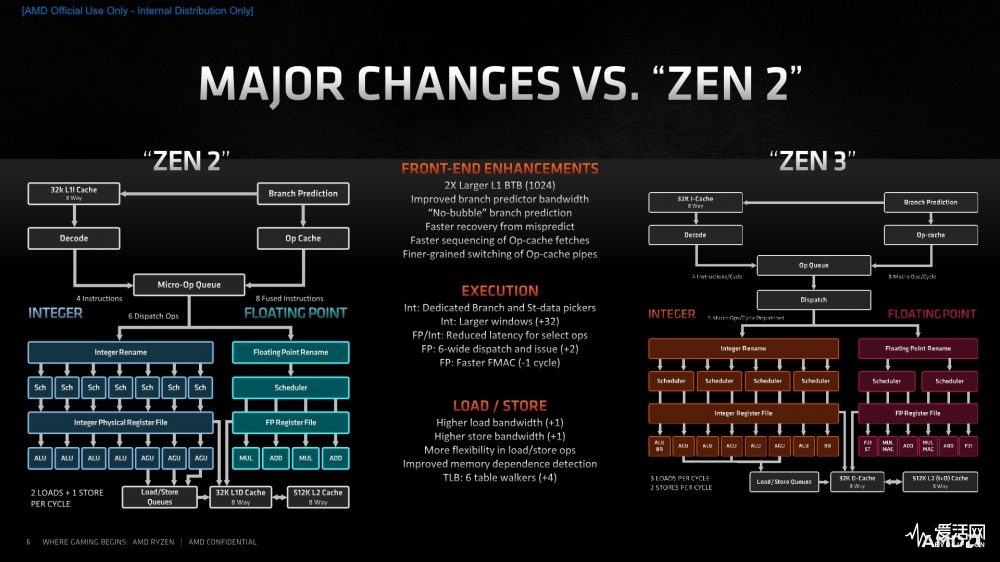
正如你所看到的那样,从“大”的方面来说,Zen 3 相对 Zen 2 内核的主要区别是 Load/Store 性能的变化:
从 Zen 2 每周期 2 Loads + 1 Stores 提升到了 Zen 3 的每周期 3 Loads + 2 Stores,幅度分别为位 +50% 和 + 100%。
众所周知,x86 是采用寄存器-内存(register-memory)的指令集架构,各种类型的算术指令既可以运行于寄存器也可以直接运行于内存上。不过,这是什么意思呢?
例如,x86 常见的指令类型(为了方便,我这里使用伪指令):
add Reg_A, MemAddr_var_1;
这是一条加法指令,将内存源地址 var_1 里的值和目的寄存器 A 的值相加,计算结果存放在寄存器 A 中,同一条指令里既有寄存器,也有内存。
内存地址_var_1 指向的值可能在物理内存或者高速缓存中,如果是后者就可以显著减少访存导致的性能下降。
寄存器属于最接近计算单元的存储资源,时延一般是 0 或者 1 周期,而内存需要访存指令,时延可能会高到 100 到数百个周期以上。
这是 CISC 指令集的特点之一,与之相对应的 RISC 指令集里,运算指令的源和目的数都必须位于寄存器中,寄存器的值需要另外透过 Load/Store 指令从内存加载(Load)或者向内存(Store)保存,上面的伪指令改为 RISC 来写的话,可能就是这样了:
ldr Reg_B, MemAddr_var_1
add Reg_A, Reg_B;
当然这是指令集层面的,对于现在的 x86 处理器来说,指令中的内存访问操作其实也是透过专门的 Load/Store 指令单元(LSU)来实现,不管哪种指令集架构,LSU 都直接影响程序运行表现。
Load/Store 属于内存操作,因此增加 Load/Store 单元,主要改善的是涉及内存密集型的操作,具体得看程序里的动态 Load/Store 指令占比,L/S 动态指令占比越高 L/S 单元性能表现影响应该越大,当然因为涉及到内存,所以 L1 D-Cache、L2 Cache、L3 Cache、硬件预拾取器、主内存以及它们的总线等也会有相应的影响。
空口无凭,大家先来看看我使用 AMD Ryzen 7 3800X 在 SPEC CPU 2017 中 INTRate(整数密集型)测试集单线程模式下实测测试时的动态指令类型分布,数据采集源自处理器的事件计数器。
软件配置说明:SPEC CPU 2017 1.1;
编译器/ 库/操作系统:gcc/g++/gfortran 10.2 + Jemalloc 5.2.1,Ubuntu 20.04 Kennel 5.4;
编译器主要优化旗标为 znver2、-Ofast;
我们这里先用 rate 测试集为例,提供该测试集中分支指令、L/S 指令比率和占比情况:
SPEC CPU 2017 intrate 整数测试集特性,数据采用 CPU 厂商的性能事件计数器采集统计:

SPEC CPU 2017 fprate 浮点数测试集特性:
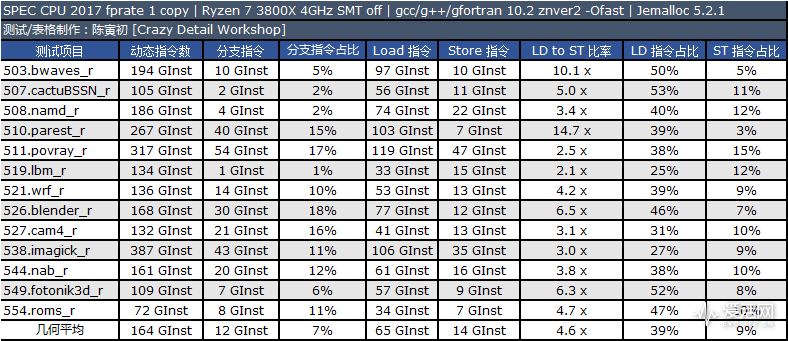
(单位说明,GInst:十亿条指令;x:倍数)
正如你所看到的,在 CPU2017 中,L/S 指令的动态指令数(处理器实际执行的指令数,非编译后的二进制静态指令数)占比平均超过了 45%,引入更多的 L/S 单元能让处理器有效提高指令并行度。
整数和浮点测试集的 LT/ST 指令比率的几何平均值分别为 3.1x 和 4.6x,这说明 Load 单元的数量应该尽量设计为比 Store 单元更多才合理,目前大部分处理器都是如此,在 Zen 3 中这个比例是 1.5x 或者说 3:2。
值得一提的是,我们在测试 SPEC CPU 的时候采用的 Jemalloc 是一个内存分配器。
C 和 C++ 的内存资源分为静态内存和动态内存,前者使用栈的方式进行分配(静态变量存活的生命周期取决于函数或者所在域的生命周期),分配的内存大小在初始化后就固定不变的,出于性能优化的目的,如果编译器这边不设置专门的参数,其大小一般很小,例如几十 KiB,优势是性能比较容易优化。
而动态内存则相对灵活许多,其大小可以用变量的方式设定,
相对于 gcc/g++ 内建的内存分配器可以在一些测试中提供更出色的内存性能。
在更早之前的 CPU20XX 系列官方测试榜单上,内存分配器基本上是 SmartHeap 的天下,smartheap 是收费的库,价格非常贵,这使得我以前跑 CPU20XX 的时候只能各种羡慕与好奇,直到后来出现了 Facebook 推出开源的 Jemalloc 后情况才有变化。微软这边也做了一个 mimalloc,据闻性能也不错,有时间再看。
AMD 的文档在前面的架构图基础上提供了更多的细节,下面根据他们提供的列表展开 Zen 3 微架构的介绍。
前端各工位主要设计目标:更快的指令拾取,尤其是分支类指令以及长指令,Zen 3 进行了如下改进:
L1 分支目标缓存(L1 BTB)大小加倍到 1024 条目,实现更快的分支时延;
提升了分支预测器的带宽;
更快地从预测失误中恢复;
“不冒泡”预测能力让“背对背”预测可以更快更好地处理分支代码;
op cache 取指测序更快;
op cache 流水线的切换粒度更精细。
处理器的流水线可以分为取指、解码、执行、写回四个工位,其中前端(front-end)是指取指和解码,执行和写回被称为后端(back-end)。
对于现在的超标量流水线处理器说,每个周期可以执行多条指令,前端需要为后端提供匹配的取指、解码能力,同时为了保证流水线闲置执行单元不浪费,人们还引入了分支预测单元,根据预测结果决定是否将下一条指令先派发给后端闲置的单元执行,待分支确定是否选中后再决定是否保留计算结果或者重置流水线。
op cache 也被称作 micro-op cache 或者 L0 I-Cache,它里面存放的是若干段处理器认为会被近期重复使用的微操作(micro-ops),所谓的微操作是 x86 处理器为了简化后端设计引入的处理器本机指令,是已经经过解码器解码的长度固定的本机指令。
在循环语句里的指令在很多情况下都是不断重复的,这些指令以微操作的方式放在 uop cache 后,后面重复执行这些操作的话,就无须经过解码器这个工位,直接发往后端的队列里等待发射执行。
uop cache 在 x86 上的原型是当年 Pentium 4 引入的 Trace Cache,Trache Cache 需要消耗大量的芯片面积,但是这是提高超长流水线架构处理器性能重要的一环。在 Pentium 4 终止后,Trace Cache 的瘦身版就以 uop cache 的形式引入,AMD 在 Zen 上面也引入了该技术。
那么 Zen 3 经过上面的措施后,对解码能力、分支预测能力以及 op cache 的实际改进如何呢?我们先来看看解码部分的实测性能。

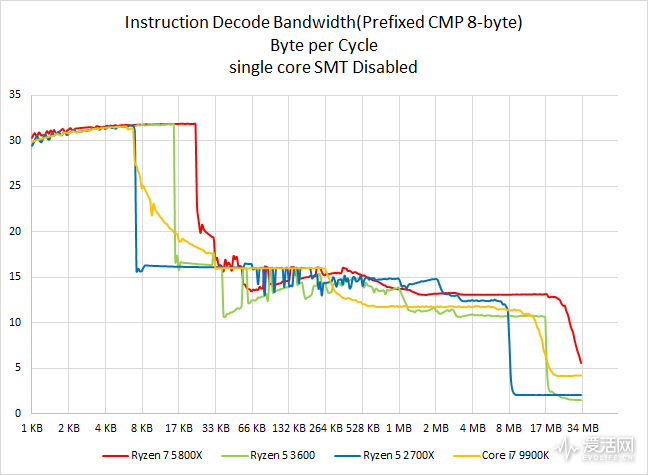
非常有意思的测试结果。
从测试结果来看,Zen 3 在单字节指令时候的解码、执行能力达到了真正的每周期 6 指令,当然这样简单的指令可能实际意义不是很大,先看着乐吧,它至少证明了前后端的单元规模在简单指令的情况下,是可以满足每周期 6 指令的吞吐要求。
到了 8 个字节长度的指令时,虽然 Zen3 依然是只有每周期 32 字节(相当于每周期两条长度为 8 字节的 x86 指令)的解码带宽结果,但是维持每周期 32 字节的能力已经从 Zen2 时代的 15 KiB 平移到了 22 KiB 字节,这相当于 7 KiB,达到了 i7 9900K 的两倍,可能的解释是 op cache 大小或者等效大小增加了 7 KiB。
在更早之前,网上有一篇 AMD 美国研究院 Jagadish B. Kotra 和 John Kalamatianos 撰写的预印刷论文《Improving the Utilization of Micro-operation Caches in x86 Processors》,里面介绍的是透过减少未操作高速缓存碎片,从而实现的微操作高速缓存压缩,实现了性能提升。
AMD 前面提到的 uop cache 切换粒度更小可能与此有关,因为类似的情况在单字节指令(NOP)中并未出现,而长字节指令更容易被压缩。当然目前还没得到官方回复的情况下,这些纯属个人猜测。
接下来,让我们看看 Zen 3 在分支预测能力的变化,这里采用 SPEC CPU2017 Intrate 来对比:

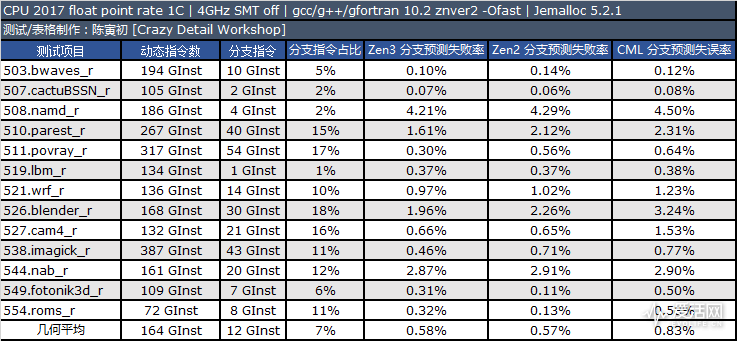
我们同样采用处理器厂商提供的硬件事件计数器记录下三款处理器运行 SPEC CPU2017 时候的分支预测失误率数据。理论上,这个世界不可能存在完美的分支预测器,但是可以尽量接近 0% 的预测失误率。
一旦分支预测失败,流水线就会被洗刷重置,流水线有多长,就会损失与流水线工位数相当的周期数,例如流水线长度是 20 级的话,出现分支预测失败,就会至少损失掉 20 个周期的性能。也就是说,当出现一条分支指令预测失败的话,性能损失将会放大 20 倍。
假设动态指令中分支指令占比 20%,里面有 1% 的分支指令预测失败,至少要损失整体 2% 的性能,但如果其中有访存等动作,实际的性能损失可能是这个数字的 10 倍以上,例如实际整体性能可能要损失 10% 到 30%。
从测试结果来看,我们认为 Zen 3 的动态分支虽然有变动,但是整体的预测准确度和 Zen 2 差不多,Zen 2 在 549 和 554 中有更好的表现,而 Zen 3 在 511 和 538 中有较高的表现。
和 Intel 目前最新的 CometLake 相比(我们测试的是 Core i9 10900K),AMD Zen 2/Zen3 的动态分支预测准确度明显要高出不少,这里点个赞。
前端部分有了解码和分支预测性能,好像写的差不多了,不过我想这里插播一下流水线深度测试,看看 Zen 2 的流水线到底有多少个工位。
这是有原因的,它和分支预测失败导致的性能开销以及频率延伸能力有一定的关系,而 AMD 和英特尔现在都没有公布这方面的数据,这次的 Zen 3 测试指南中只是有一句模棱两可的话语:更快地从预测失误中恢复。
下表中的左侧是以伪代码方式提供分支程序测试片段,以第 7 个测试(Test 6)为例:
Test 6, N= 1, 8 br, MOVZX XOR ; if (c & mask) { REP-N(c^=v[c-256]) } REP-2(c^=v[c-260])
这段内容包含了一个 MOVZX 内存载入操作指令,它需要额外的 5 到 6 个周期来执行,在支持乱序执行、乱序 L/S 的处理器中,这个动作占用的流水线工位通常会被掩盖掉。
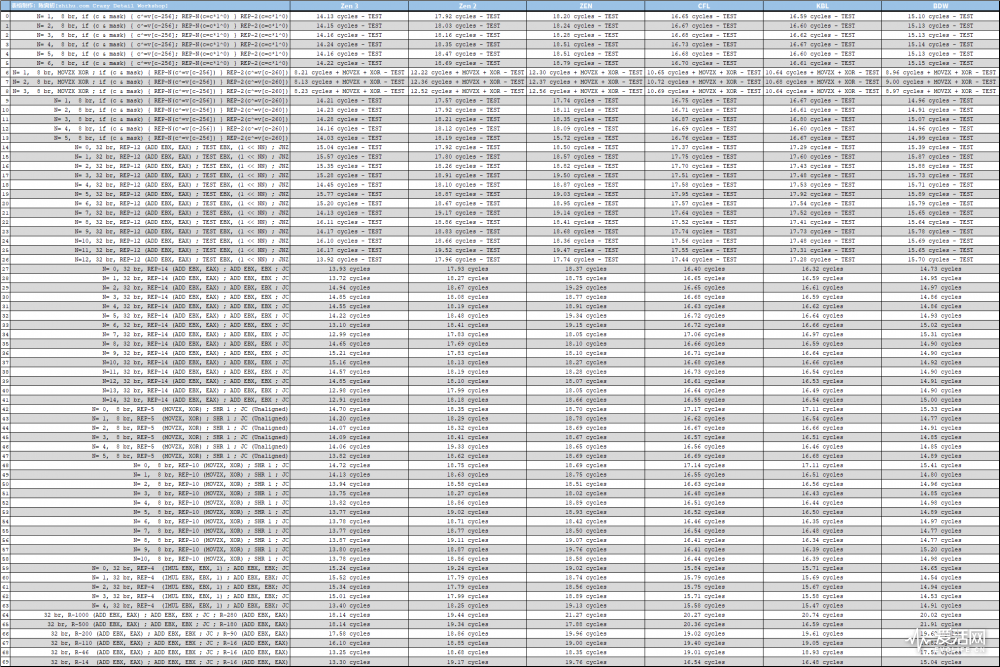
从测试结果来看,Test 6 的 Zen 3、Zen2、Zen 1 测试结果分别是 8.21、12.22、12.30 个周期,加上 MOVZX 的 5 个周期,那这个测试的 Zen 3、Zen 2、Zen 1 有效结果就是分别是 13、17、17 个周期。
Zen 3 的等效流水线工位是 14-18 级左右,普遍减少了 4 个工位!
测试结果完全出乎我的意料——没想到 Zen 到了第三代的时候居然出现了流水线工位减少的情况,流水线工位减少,意味着分支预测失败的惩罚更低,随之而来的是频率延伸能力可能更低,但是最终产品来看,Zen 3 系列的全核加速频率并不比 Zen 2 弱甚至要更快。
这说明了一点:AMD 在缩短流水线工位的同时透过优化电路、制程等措施,实现了更高的频率。
主要设计目标:降低时延、扩充单元,实现更高的指令级并行(ILP),Zen 3 作了如下的改进。
为整数操作提供独立的分支和存储拾取单元,相对于上一代的 Zen 2 增加了三个,达到了 10 指令发射能力;
更大的整数指令窗口,相对于 Zen 2 增加了 32 条目;
降低了个别浮点和整数指令的时延;
浮点内存操作单元增加了两个,浮点流水线派发和发射能力提升到 6 指令;
浮点 FMA 指令时延缩短了 1 个周期。
对于执行引擎,我们测试了 ReOrder Buffer、指令吞吐时延等数据。
很多乱序执行处理器都采用了名为 Re-Order Buffer(重排序缓存)的技术,使指令在乱序执行后能够按照原来的顺序提交结果。指令在以乱序方式执行后,其结果会被存放在 ROB 中,然后会被写回到寄存器或者内存中,如果有其它指令马上需要该结果,ROB 可以直接向所需的数据。简而言之,ROB 的大小对于确保有足够的乱序驻留指令以及动态分支预测的恢复,对提升指令集并行度有不可忽视的作用。
我这里使用 Travis Downs 的 rob size 工具来测试,测试结果如下:
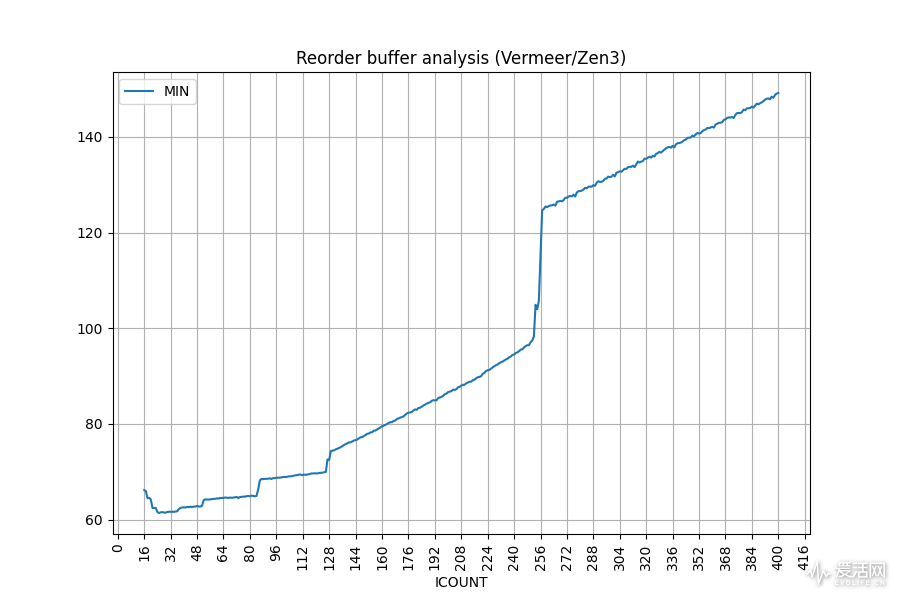


正如你所看到的那样,Zen 3 的整数 ROB 大小已经从 Zen 2 的 224 提高到了 256,这是一个不错的提升,意味着 Zen 3 能够提供多 32 条指令或者说微操作的乱序执行能力。
现在让我们看看指令时延和吞吐的测试结果,测试数据源自 AIDA64,不过由于篇幅有限,而采样的指令数据高到 4600 项,我们只能采用只选取若干我们认为比较重要的指令,例如赋值(mov)、位移(shift)、加法(add)、乘法(mul)、FMA、除法(div)、平方根(sqrt)以及与之对应的单精度(xxxxPS)、双精度模式(xxxxPD),此外还有 AES 等指令,测试结果以 时延|吞吐 的方式展现,单位是周期。
测试结果如下:
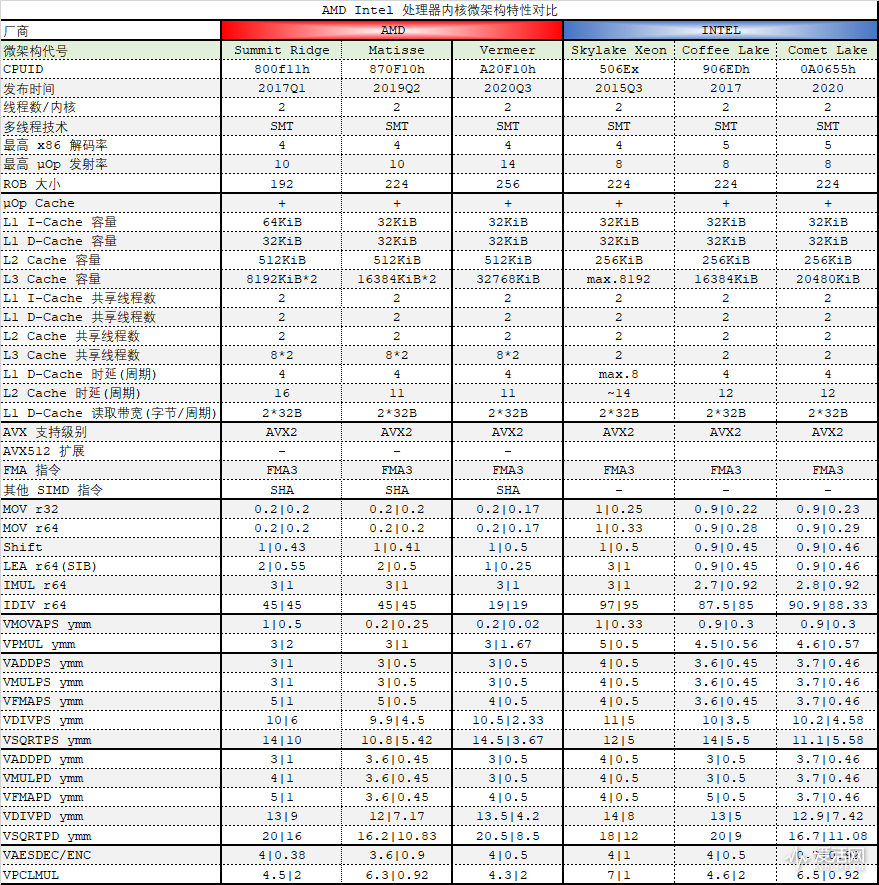
在 x86 中,mov 和 lea 都属于赋值指令,这里测试的是寄存器赋值。其他的指令大家应该都比较熟悉,相关的文档也有介绍,例如 VPMUL 指令可以在这里找到解释。
mov 指令方面,Zen 3 有 15% 的吞吐提升,而 lea 指令的吞吐则提升了一倍。
FMA 指令如 AMD 介绍的那样,时延降低了 1 个周期,与 Intel 的 FMA 指令时延相当了。
向量除法和 Zen2 相比吞吐性能提升了一倍;
平方根和 Zen2 相比吞吐性能提升了 30%;
AES 和 Zen2 相比指令吞吐性能提升了一倍。
让我们再看看物理寄存器堆(register file)大小。
从 Cyrix 在 95 年发布的 Cyrix M1 处理器是史上第一款具备寄存器重命名和乱序执行能力的 x86 处理器算起,x86 处理器的乱序执行至今已经有 25 年了。
在绝大部分情况下,寄存器重命名不一定和乱序执行是挂钩,例如 Intel IA64 就有多达 128 个通用整数寄存器,虽然也涉及寄存器重命名的概念,但这是编译时的事情,在编译时做寄存器重命名也不见得都是好事(容易导致代码膨胀,降低指令高速缓存命中率)。
对于 x86-64 这种只有 16 个指令集架构寄存器的指令集架构而言,寄存器重命名是保障乱序执行必不可少的技术,要重命名,自然得需要有足够的物理寄存器才行,物理寄存器越多,可供重命名的资源也就越多,维持乱序执行的能力就越强。
我们使用 robsize 同样的测试程序进行了物理寄存器堆(PRF)大小的探测。这里说明一下,我们前面的 rob 大小探测使用的是 nop (空操作)指令,不占用任何寄存器,而接下来做的 PRF 大小推测测试,使用的是 add(加法)指令。
需要注意的是,物理寄存器堆里同时含有乱序执行中可用于推测执行的推测寄存器数量和已提交寄存器数量,因此这种测试方式不能把直观地把整个物理寄存器堆的大小给出来,它只能测量出可用于推测执行的寄存器数量。

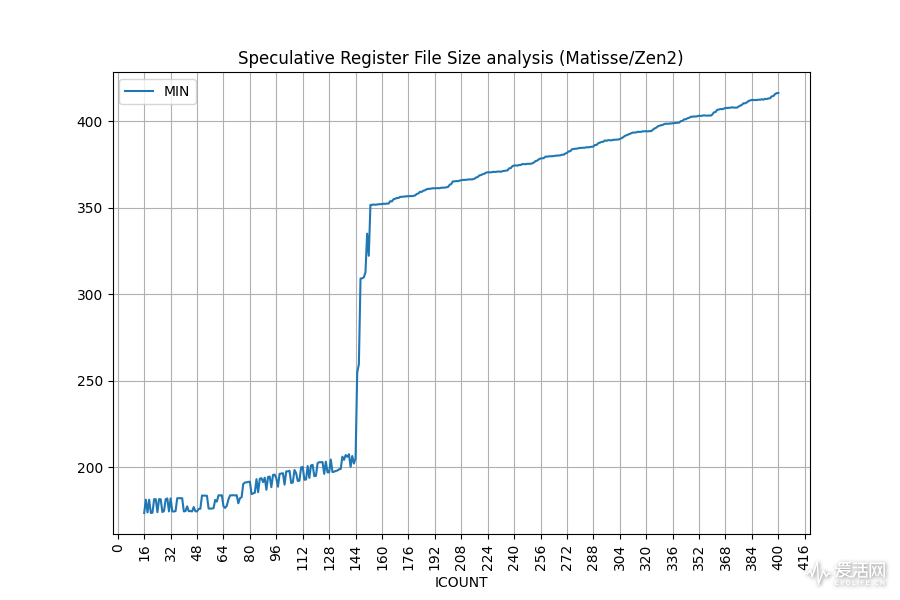

正如你所看到的那样,Zen 3 可用于推测执行的物理寄存器大小要比 Zen 2 小了 16 个.
按照官方的规格,Zen 2 的物理寄存器堆大小是 180 个,实测可用于推测执行的是 144 个,因此有 36 个不能用于推测执行,而到了 Zen 3 上,我预期其大小不应该少于 Zen 2,例如也都是 180 个,因此在 Zen 3 上不可用于推测执行的寄存器数量应该是 48 个。
Comet Lake 预期的物理寄存器数量应该是 180 个,实测可用于推测执行的是 144 个,有 36 个物理寄存器不能用于推测执行。
再看看浮点物理寄存器的情况,我们使用 AVX 指令来探测。
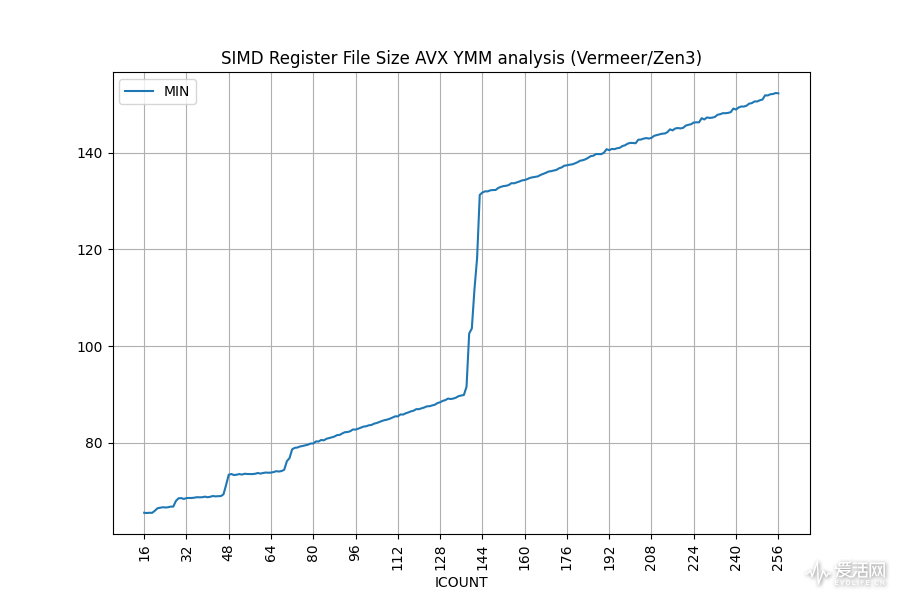


三个微架构可用于推测执行的浮点物理寄存器大小相当,都是 144 个。
三个微架构都不支持 AVX-512,所以这次就不用考虑测试 zmm/ymm 寄存器的共享问题了。
主要设计目标:扩建+更快的预拾取,以支持增强了的执行工位。
更高带宽,满足更大、更快的执行工位带宽需求;
Load 单元 +1;
Store 单元 +1;
更灵活的 L/S 操作;
内存相依性检测能力增强;
TLB 中的页表搜索器(table walker)增加了 4 个。
我们首先使用 uarch-bench 做了一些 LSU 相关的测试,
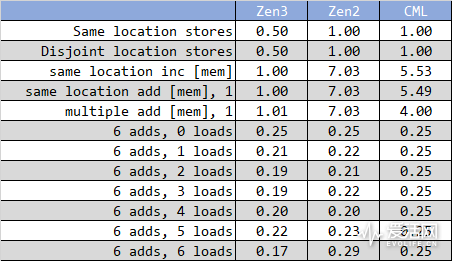
正如你所看到的,Zen 3 的实测 store 性能达到了每周期两个,对于相同目标地址的内存操作(里面混合了 load 和 store 指令),现在只需要 1 个周期就能完成,而 Zen 2 需要 7 个周期,我相信除了增加 LSU 外,Zen 3 还有一些别的优化措施实现这个能力。
我这次采用 SPEC CPU2017 进行对比,首先,我们使用同频率 4GHz 来测试,其中插播一片 10 年前的 Core i7 2600K:


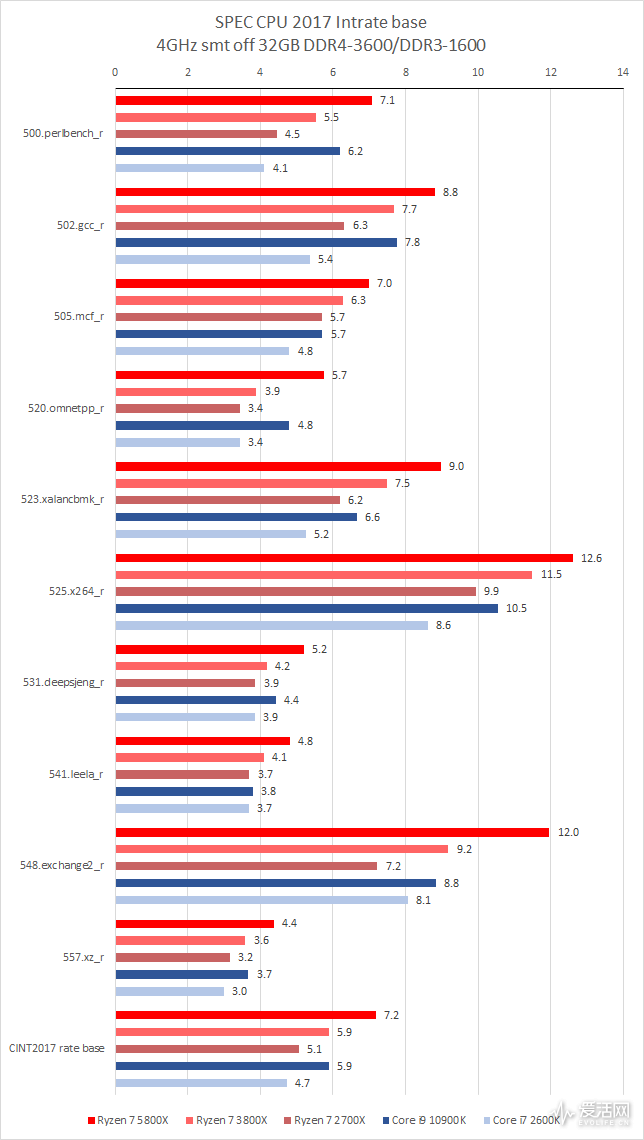
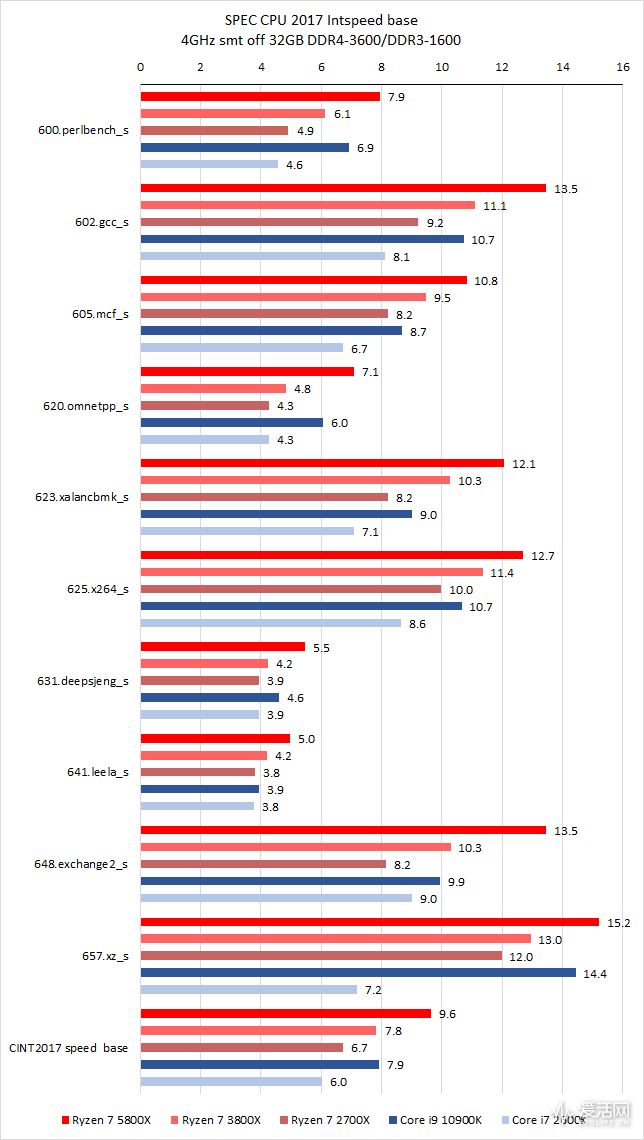
我们采用了 4GHZ 同频的目的是为了便于比较 IPC。
在整数 rate 1copy 测试中,Ryzen 7 5800X 的同频性能比 Ryzen 7 3800X、Ryzen 7 2700X、Core i9 10900K、Core I7 2600K 快大约 22%、42%、22% 和 52%。
在浮点 rate 1copy 测试中,Ryzen 7 5800X 的同频性能比 Ryzen 7 3800X、Ryzen 7 2700X、Core i9 10900K、Core I7 2600K 快大约 13%、28%、20% 和 78%。
在整数 speed 测试中,Ryzen 7 5800X 的同频性能比 Ryzen 7 3800X、Ryzen 7 2700X、Core i9 10900K、Core I7 2600K 快大约 23%、43%、21% 和 60%。
在浮点 speed 测试中,Ryzen 7 5800X 的同频性能比 Ryzen 7 3800X、Ryzen 7 2700X、Core i9 10900K、Core I7 2600K 快大约 5%、16%、0% 和 188%。
以上是纯 IPC 方面的提升幅度。
对于在运行于默认频率(含自动加速)的测试,代表了大家日常的应用感受。
默认频率( CPU 自我放飞了),关闭超线程:
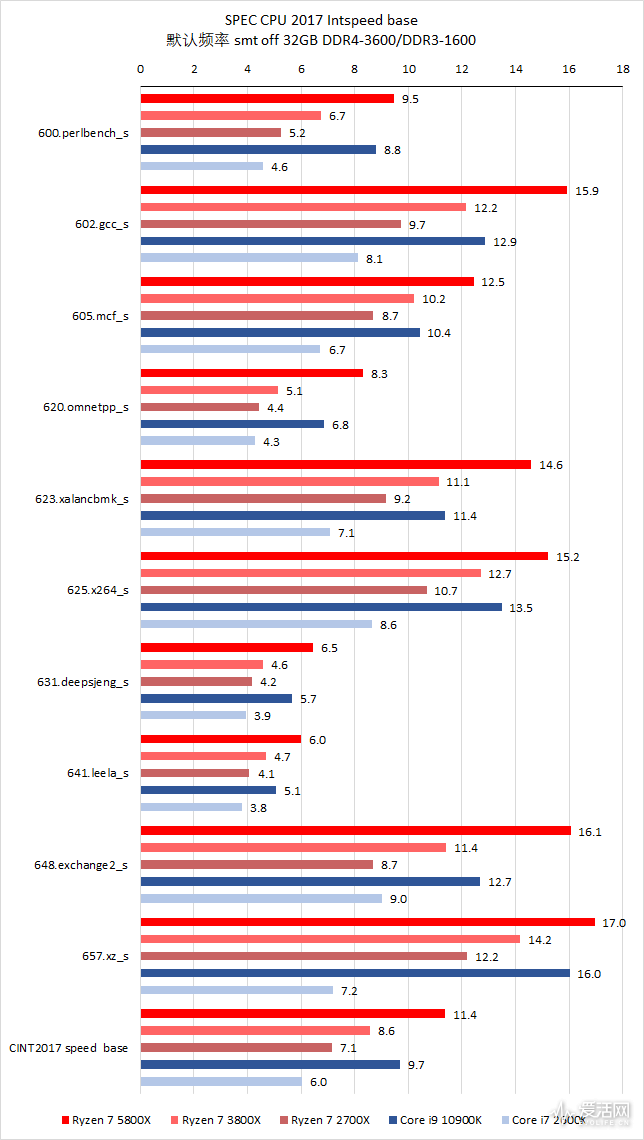



在整数 rate 1copy 测试中,Ryzen 7 5800X 的默认频率性能比 Ryzen 7 3800X、Ryzen 7 2700X、Core i9 10900K、Core I7 2600K 快大约 32%、59%、慢 17% 和 80%。
在浮点 rate 1copy 测试中,Ryzen 7 5800X 的默认频率性能比 Ryzen 7 3800X、Ryzen 7 2700X、Core i9 10900K、Core I7 2600K 快大约 20%、41%、15% 和 110%。
在整数 speed 测试中,Ryzen 7 5800X 的默认频率性能比 Ryzen 7 3800X、Ryzen 7 2700X、Core i9 10900K、Core I7 2600K 快大约 33%、59%、17% 和 89%。
在浮点 speed 测试中,Ryzen 7 5800X 的默认频率性能比 Ryzen 7 3800X、Ryzen 7 2700X、Core i9 10900K、Core I7 2600K 快大约 10%、23%、4% 和 207%。
透过这次针对 Zen 3 微架构测试,大家可以了解到,Zen 3 在很多细节上的变化:
1、LSU 单元各增加一个;
2、L3 Cache 合体,对游戏等应用将会有显著的提升;
3、诸多指令的时延和吞吐能力获得提升;
4、流水线长度缩短了;
5、uop cache 有重大优化;
6、指令窗口增加到 256 条目;
7、物理寄存器堆可用于推测执行的资源减少了。
这些诸多的改变,对于 Zen 3 来说,反映到 SPEC CPU 2017 中,最显著的提升领域是整数性能,单线程下,同频比 Zen 2 大约提升了 22%,浮点相对较少,是 13%,和 Comet Lake 比整数大约快大约 22%,浮点大约快 20%。由于 Comet Lake 具有 10 个内核,所以在多线程浮点中,两者同频性能相当。
默认频率规格下,Ryzen 7 5800X 的提升幅度更大,单线程下整数和浮点分别比 3800X 快大于 32% 和 21%,时隔 一年,这是非常大的提升了(斜眼 Intel)。
 31
31 0
0
 0
0 31
31




