
代差的碾压 AMD Zen 3处理器暨ROG C8DH评测报告

 登录|注册
登录|注册






在解析完微架构之后,再来看看整体架构。先让我们温习下Zen 2整体架构特点。
Zen 2是采用的Chiplet的多芯片方式进行构建,桌面级的Zen 2可以有2个封装的处理器芯片,每个处理器芯片可以有 8个核心,这8个核心被分成2个CCX组,每个组4个核心共享16MB L3缓存,一共32MB缓存。不同CCX的核心通讯需要通过IF总线访问CIOD,再回到另外CCX的核心。内存控制器和其他外围的PCIE HUB也在外部的CIOD中。

这样设计的优势是Zen 2可以以Chiplet的方式以更为低的难度和成本扩展核心数量,缺点是由于要访问核心外的CIOD芯片,跨CCX核心通讯和内存通讯性能差,延迟和耗时大。多封装的设计处于对于成本的考量,这个得失还是可以接受,Zen 2设计的主要缺陷就是单芯片双CCX的设计,这样设计会导致两个问题,第一个问题是跨CCX核心通讯性能差,究竟要去CIOD外部芯片绕一大圈,第二个问题是,虽然一个芯片有32MB L3缓存,但由于CCX一个核心只能使用一半的16MB L3,并且两个L3还需要一致性同步,这进一步的降低了L3性能。
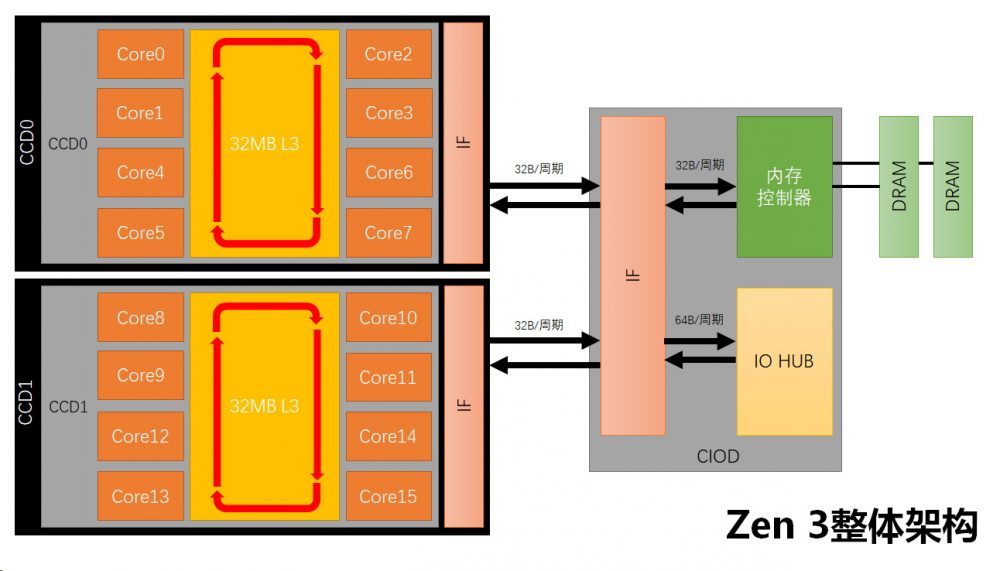
而Zen 3在整体架构上就解决了CCX设计问题,单个芯片就不再分CCX,而是8个核心在一起,共享32MB缓存,这样单个芯片的所有核心就可以直接访问同封装的所有核心,而不用再去CIOD绕一大圈,同时所有核心都可以使用全部的32MB缓存。不过跨封装的核心访问和内存访问还是要经过CIOD,还是有Zen 2的老问题。
![H0YMYH7]A4~XK7FD9254]Q1](https://file.evolife.cn/2020/11/H0YMYH7A4XK7FD9254Q1.png)
上图是Zen 2的Die,一个Die有2个CCX,每个CCX 4个核心,4个核心对应的L3缓存是由十字形的Crossbar总线连接的,Crossbar是所有核心两两都互相直连,4个核心之间都可以直接通讯,路径短,这样的Crossbar基本就是从推土机上延续下来的。
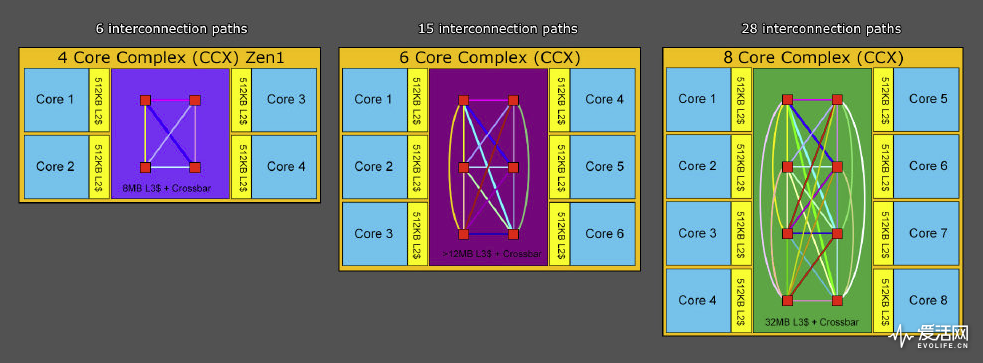
但Crossbar的两两互联,4个核心还好就是6个通路,但随着核心数的增加,通路需求就膨胀起来,6个核心需要15条,8个核心全部两两相通这就夸张到28条,这完全是个排列组合的问题。继续用Crossbar在复杂度上就不可能可以接受,因此Zen 3也改成了和Skylake一样的Ring环形总线。但这个环是个怎么样的环,就是个更为复杂的问题,甚至并不是像Skylake那样的单环。
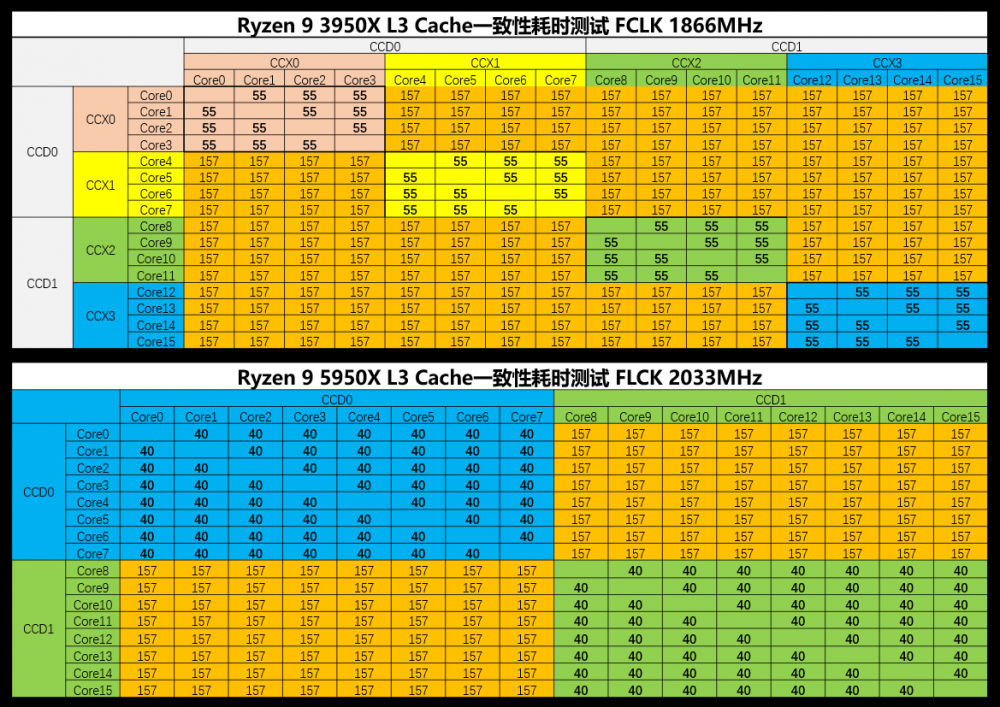
我们使用Cache 2 Cache测试不同核心的L3缓存一致性耗时(关闭SMT),3950X(FCLK 1733 内存1866MHz)同CCX耗时大概在55ns(平均近似),而跨核心和跨CCX一样,都在157ns水平。
而5950X是8个核心一个CCD,不再分CCX,单个CCD内的核心耗时40ns(平均近似),而垮CCD则也为157,和Zen 2差不多。Zen 2相同Chiplet不同CCX核心互相通讯,还是要通过IF去CIOD转一圈,而Zen 3同Chipet都可以互相通信。另外需要注意的是,RingBus相比Crossbar一致性耗时也应该是有差别的,Crossbar其实应该比较平均,在相同条件下也应该更快,Ring有一定的顺序性,路径比较长,时长变化差别也更大,但实际测试Zen 3还是更快,这个应该还是和L3性能有关系。
![TL7$]5K67UKCQ`2T1IBB_93](https://file.evolife.cn/2020/11/TL75K67UKCQ2T1IBB_93.png)
并且对于5600X/5800X这样单Chiplet处理器影响更大,所有核心都可以直接通讯,而没之前3600/3700X/3800X的跨CCX性能下降的问题。其实大部分用户都会选择8核心或者以下的型号,这个完全无跨CCX的提升其实意义更为重大。
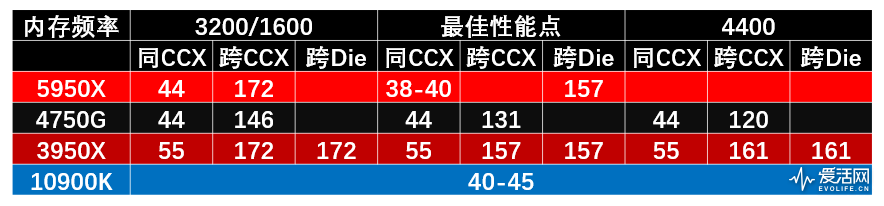
上面是最佳性能点的测试,此外我们还测试了不同内存频率、FCLK对于性能的影响。
我们现在用的C2C精度不足以继续细致分析,再改为使用 Intel 的 Memory Latency Checker 3.9(AMD 内部也是使用这个工具)进行该测试:

Memory Latency Checker 中有一个 –c2c 的测试开关,可以用于指定测试不同内核之间进行数据交换的时延。
它提供了两种测试模式,分别是 HITM 和 HIT,我们使用的指令分别类似于以下的样子:
mlc –c2c_latency -c0 -w1 -b200000 -C128
写入线程绑定到 1 号内核 1 上,在其 L2 cache 中对 128 KiB 的数据进行修改,然后数据传输到 0 号内核上,由于数据块处于 M 状态,因此嗅探响应会将它设定为 Hit-Modified 状态,然后数据块才会从 cache 传输到“请求者”。之后,控制权转回到做写入操作的 1 号内核,该内核会把操作窗口移动到参数 b 指定的缓存(大小为 200 KiB)中的另一个 128KiB 数据块上,然后重复上述的处理至完成。
和:
mlc –c2c_latency -c0 -w1 -b200000 -C128 -H
类似上面的操作,但是 1 号内核不做数据修改处理,它会绑定并读取参数 -b 指定的缓存到自己的 L2 Cache,然后将控制移交给 0 号内核做读取操作。此时参数 -b 指定的 200KiB 数据已经被读取至 1 号内核中,其状态被设置为 E 状态,嗅探响应会被设定为 Hit-Clean(HIT),数据块会从该 cache 传输到请求者(0 号内核)里。
从我们的测试来看,Zen 2 的 L2 cache 数据交换操作时延在 4 号到 7 号出现接近 300 个周期的时延,到了 Zen 3 这边,时延降低到了 100 周期的视频,现在的速度相当于是以前的 3 倍。
比较特别的是,Zen 3 的时延有一个特点,那就是第 0、2、4、6 号的数据交换时延是相对较快的,都在 90 周期以内(HITM 模式),然后 1、3、5、7 的时延会高一些,大约高 6 到 17 个周期,幅度还 20 个周期。相较而言,CometLake 的内核数据共享时延基本上都在 63 到 75 周期,幅度在 12 周期。
可以这么认为,在芯片级的内核间交换时延方面,AMD 已经有长足的进步,但是和 Intel 的最新处理器相比,仍然有一点差距。
内存频率影响
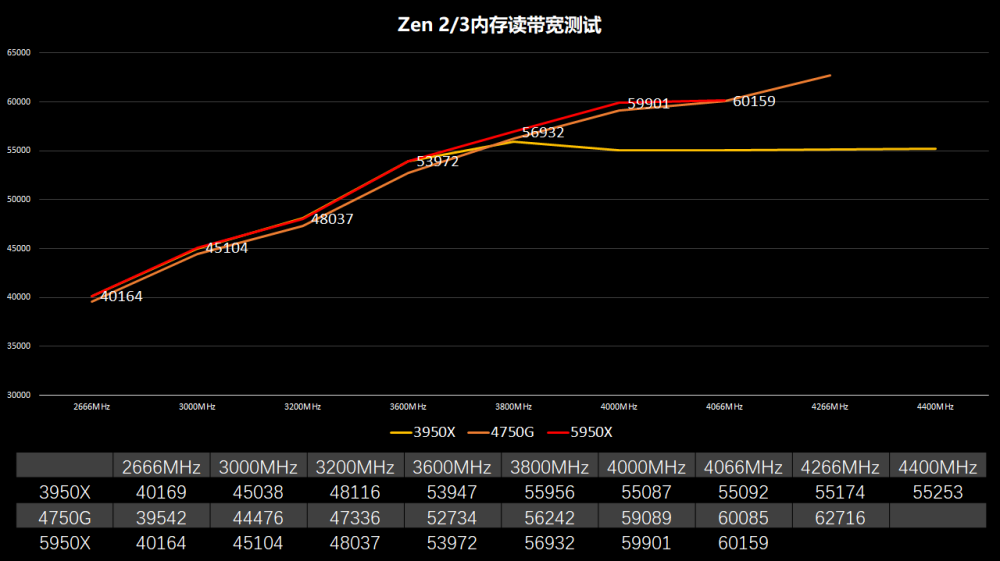
Zen 2内存存在一个甜点频率,其内存控制器频率存在一个和IF总线频率FLCK同步的问题,FCLK体质好的可以到1900MHz,那内存控制器也是运行1900MHz,内存就跑在3800MHz。(当然部分体质较差的U只能跑1866,那内存同步就是3733MHz)。如果内存频率超过3800MHz,那FLCK就会变成异步模式,频率为内存控制器频率的一半,虽然内存带宽上升,但IF总线的速度砍半,这样会直接导致跨CCX核心通讯性能大幅下降。因此Zen 2内存跑在4000、4266性能是不升反降,3800就是完美的甜点频率。‘

Zen 3也是采用相同的设计,但FCLK上限从1800提升到了2000,这就意味着内存可以跑到4000MHz。经过我们实际测试,体质好的可以到2033MHz,则内存可以同步到4066MHz。我这4颗Zen 3虽然2033 FLCK可以点亮,但5900X/5950X会出现高负载重启的问题,实际5900X可用稳定运行在2000MHz,而5950X 2000都不能完全稳定,从我这手上的4颗初步看来核心数越高,FCLK就越难稳定。
 、
、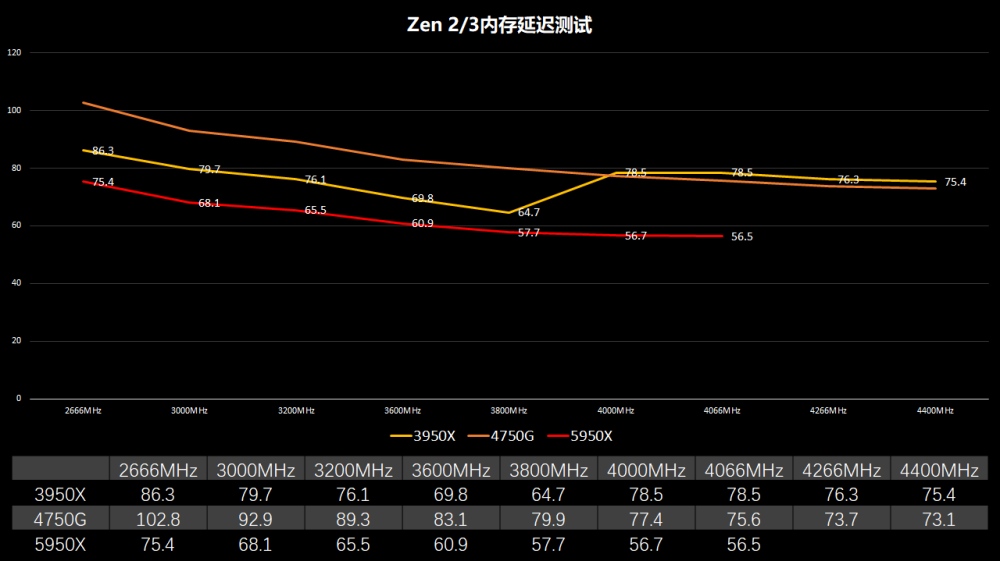
我们将Zen2/3还有Renoir 4750G进行内存带宽和延迟对比(内存设置参数为20-19-19-39),使用的是工具是AIDA 64 6.30。Zen 2的FCLK拐点是1900MHz,FLCK不能超过1900MHz,内存频率再高FLCK就是是半速。带宽带宽和内存延迟都不升反降。而Zen 3在同频相比Zen 2内存带宽差不多,但可以上到2033的FCLK,这样还是可以获得更大的带宽。内存延迟方面,在同频Zen 3相比Zen 2还是有10ns的优势。
另外5600X/5800X单CCD的型号内存写带宽是减半的,原因是是将写入带宽从CCD->IOD从32B/cyc降低到16B/cyc,而读取带宽保持在完全32B/cyc,这个和Zen 2是一样的。
Renoir没有采用chiplet分开分装,而是采用传统内存控制器和核心都是在一起的单封装,这样内存控制器和FLCK都是采用新工艺新设计可以上到更高的频率。但由于L3容量小,其内存带宽在同频略差于Zen2/3,尽在2000以上频率有少许优势,延迟方面的情况也差不多。

Zen 3工艺方面现在并没什么定论,早期PPT写的是7nm+。TSMC 7nm改进工艺有两种,第一种是N7P,N7P是最开始7nm的工艺概率优化,大概可以在相同功耗下提升7%的性能,Zen 2在今年某个时间点频率性能大概好了0.2GHz,我一直就怀疑上了N7P。而N7+则是使用EUV的大改工艺,密度可以提高20%,同性能可以降低15%的功耗,或者在同功耗提升10%的性能。
Zen 3相比Zen 2在核心规模扩大的情况,频率大概还是提升0.2GHz的,这样的提升幅度还是比较明显。但官方资料仅仅写的是7nm工艺,并没有说明是DUV还是EUV。一般理解7nm+就应该是N7+。但至今anandtech对AMD CTO的采访中,Papermaster说道:
Papermaster大概意思就是说Zen 3还是使用相同的工艺节点,还是相同的工艺设计方案。不过工艺会在后续做小的优化改进,这个意思应该是说Zen 3还应该是7nm DUV。

再来看看我们的主角,Ryzen 5000系列CPU,依次是5600X/5800X/5900X/5950X,接口和封装没有任何变化。生产日期在20年36-38周,大概就是10月。
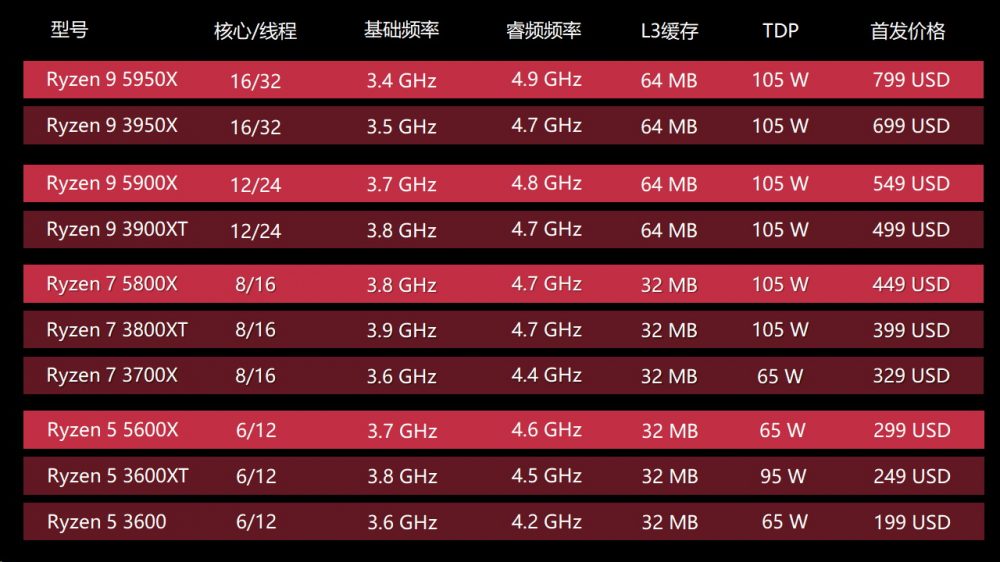
Ryzen 5000系列相比3000系列相同定位的产品核心数量和缓存容量都没有变化,频率基本都有一点拉高。我们手头的5800X/5600X FCLK可以上2033,5900X是2000,5950X是1966,后面如果没有特别说明,就都是按这个FCLK设置进行测试。
 31
31 0
0
 0
0 31
31




